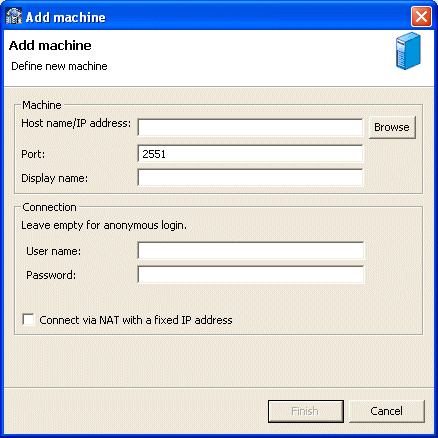
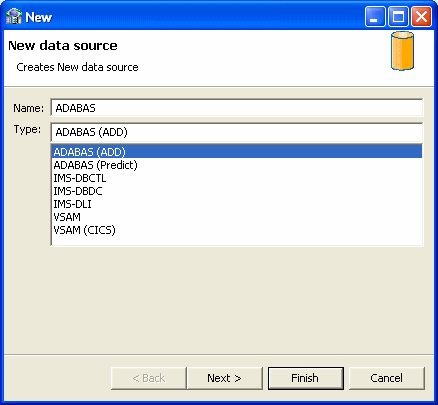
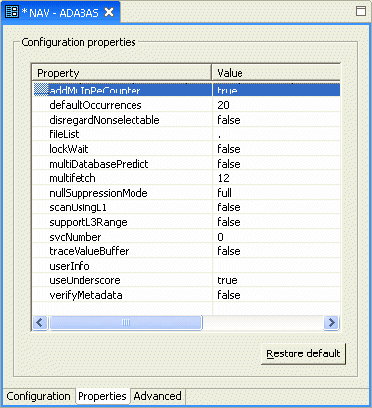
After defining the connection, you set the data source properties.
The following properties can be configured for the Adabas data source in the Properties tab of the Configuration Properties screen:
-
dbNumber: (Predict, ADD) The Adabas database number.
-
predictFileNumber: (Predict only) The Predict file number.
-
predictDbNumber: (Predict only) In some cases the Predict file is located in a different database than the data. If so, use this attribute to specify the database number in which the Predict file is located.
-
svcNumber: (Predict, ADD; MVS only) The installation on MVS places the SVC number of Adabas in the GBLPARMS file. Alternatively, you can specify the SVC number using this attribute. This simplifies configuration in sites where several Adabas installations on different SVC numbers need to be accessed from a single installation. Each SVC will still require a different workspace, but the same GBLPARAMS and the same RACF profile can be used for the different workspaces.
-
addMuInPeCounter: (Predict, ADD) Until version 4.6 Oracle Connect for IMS, VSAM, and Adabas Gateways did not support counters for MUs inside of PEs. In version 4.6 this support was added, but since it changes behavior for existing users, this attribute was added to allow existing users to turn off this new feature to preserve compatibility. Default: addMuInPeCounter='true'.
-
defaultOccurences: (Predict only) If the Predict occurrences field for multiple value fields or periodic group fields is not specified, the value of this parameter is used. If a record is retrieved with more occurrences than specified, an error is returned. Default: defaultOccurances='10'.
-
disableExplicitSelect: (Predict, ADD) This attribute indicates whether or not the Explicit Select option is disabled. If disabled, a select * query on an Adabas table will return all fields in the table, including ISN and subfields that are normally suppressed unless explicitly requested in the query (for example, select ISN, *…). Default: disableExplicitSelect='false'.
-
disregardNonselectable: (Predict, ADD) This attribute enables you to configure the data source to ignore descriptors defined on a multiple value (MU) field, a periodic group (PE) field or phonetic/hyper descriptors. The special ACSEARCH fields that are normally created for a table are referred to as "non-selectable" because you cannot specify them in the select list of a query. Setting the disregardNonselectable attribute to 'true' will prevent these fields from being created. Default: disregardNonselectable='false'.
-
fileList: (Predict, ADD) This attribute is passed as the record buffer to the OP command. Adabas allows a list of file numbers to be provided in the record buffer of the OP command, along with the operations allowed on each file. By using this attribute, a user can restrict access to the database, allowing only specific operations on specific files.
Note:
Note that the value provided in this attribute is passed "as-is" to Adabas. No validation is performed. The default value grants unrestricted access to all files in the database:
fileList='.'
-
lockWait: (Predict, ADD) This attribute specifies whether the data source waits for a locked record to become unlocked or returns a message that the record is locked. In Adabas terms, if this attribute is set to true a space is passed in command option 1 of the HI/L4 commands. Otherwise an 'R' is passed in command option 1. Default: lockWait='false'.
-
multiDatabasePredict: (Predict only) Turn this flag on if your Predict file includes metadata for several different databases. This has two effects on the way that the Predict information is read:
-
Only tables that belong to the current database are returned in the table list.
-
The file number for a table is read separate from the metadata as different databases may include the same table using a different file number.
-
multifetch: (Predict, ADD) This parameter controls the number of records to be retrieved in a single read command (L2, L3, S1-L1). The value provided in this attribute controls the value passed in the ISN lower limit control block field. By default no multifetch is used. The multifetch buffer size can be controlled as follows:
-
multifetch='0': Lets the driver decide the number of records to retrieve. The driver will generally retrieve rows to fill a 10k buffer. No more than 15 rows are fetch at once.
-
multifetch='n': Causes n rows to be read at a time, where n is a number from 2 to 15.
-
multifetch='-n': Defines a read-ahead buffer with a fixed size, where n is less than or equal to 10000 bytes.
-
multifetch='1': Disables the read-ahead feature. (default)
-
nullSuppressionMode: (Predict, ADD) This attribute controls the behavior of the Adabas driver with regard to null suppression handling. This attributes allows a user to change this default NULL suppression policy. Note that changing this setting improperly may result in incomplete query results. The following values can be selected:
-
full: (default) NULL suppressed fields are exposed as NULLABLE and must be qualified for the Oracle optimizer to consider using a descriptor based on a NULL suppressed field.
-
disabled: NULL suppressed fields are handled like any other field. Use this setting only if you completely understand the potential implications as incomplete query results may returned.
-
indexesOnly: Only NULL suppressed fields that are part of a descriptor/super-descriptor are exposed as NULLABLE. Other NULL suppressed fields are handled normally. This setting is as safe as the "full" setting and does not include the risk of incomplete results as the "disabled" option does.
-
scanUsingL1: (Predict, ADD) A scan strategy on a table is normally implemented by an L2 command. It is possible, however, to turn on this attribute in order to scan using the L1 command. This has the advantage of providing better data consistency at some performance penalty. Default: scanUsingL1='false'.
-
supportL3Range: (Predict, ADD) Older versions of Adabas did not allow for a range specification on an L3 command (such as AA,S,AA in the search buffer). Only the lower limit could be provided. If your version of Adabas supports a range in the L3 command you can turn on this attribute to enjoy better performance in some queries. Default: supportL3Range='false'.
-
traceValueBuffer: This is a debugging tool to be used in conjunction with driverTrace='true' in the environment. Turning on driverTrace will record the Adabas commands executed in the server log file. If you also want a binary dump of the value buffer and record buffer, set this attribute to true. Default: traceValueBuffer='false'.
-
userInfo: (Predict, ADD) This attribute specifies the value passed as a null-terminated string to Adabas as the seventh parameter on the adabas call. The value provided is then available in Adabas user exits. This has no affect at all on Oracle Connect for IMS, VSAM, and Adabas Gateways, but some users have taken advantage of this feature to implement some specific auditing. Note that it is possible to control the value of the userInfo attribute dynamically at run time using the nav_proc:sp_setprop stored procedure. Default: userInfo=''.
-
useUnderscore: (Predict, ADD) This attribute indicates whether or not to convert hyphens (-) in table and column names into underscores (_). The inclusion of hyphens in Adabas table names and field names poses an inconvenience when accessing these tables from SQL because names that include a dash need to be surrounded with double quotes. To avoid this inconvenience, the data source can translate all hyphens into underscores. Default: useUnderscore='true'.
-
verifyMetadata: (Predict, ADD) This attribute indicates whether or not to cross-check the Predict or ADD metadata against the LF command. Resulting discrepancies are written to the log and removed from the metadata at run time. It is usually unnecessary to use this attribute. Default: verifyMetadata='false'.