| Oracle® In-Memory Database Cache Introduction 11g Release 2 (11.2.2) E21631-04 |
|
|
PDF · Mobi · ePub |
| Oracle® In-Memory Database Cache Introduction 11g Release 2 (11.2.2) E21631-04 |
|
|
PDF · Mobi · ePub |
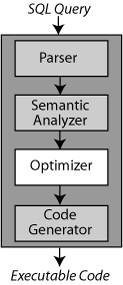
TimesTen and IMDB Cache have a cost-based query optimizer that ensures efficient data access by automatically searching for the best way to answer queries. Optimization is performed in the third stage of the compilation process. The stages of compilation are shown in Figure 5-1.
The role of the optimizer is to determine the lowest cost plan for executing queries. By "lowest cost plan," we mean an access path to the data that takes the least amount of time. TimesTen invokes the optimizer for SQL statements when more than one execution plan is possible. The optimizer chooses what it thinks is the optimum plan. This plan persists until the statement is either invalidated or dropped by the application.
The optimizer determines the cost of a plan based on:
Table and column statistics
Metadata information (such as referential integrity, primary key)
Index choices (including automatic creation of temporary indexes)
Scan methods (full table scan, rowid lookup, range index scan, bitmap index lookup, hash index lookup)
Join algorithm choice (nested loop joins, nested loop joins with indexes, or merge join)
This chapter includes the following topics:
The optimizer is designed to generate the best possible plan within reasonable time and memory constraints. No optimizer always chooses the optimal plan for every query. Instead, the goal of the optimizer is to choose the best plan from among a set of plans generated by using strategies for finding the most promising areas within the search-space of plans. Because optimization usually happens only once for each query while the query itself may be executed many times, the optimizer is designed to give precedence to execution time over optimization time.
The plans generated by the optimizer emphasize performance over memory usage. The optimizer may designate the use of significant amounts of temporary memory space in order to speed up execution time. In memory-constrained environments, applications can use the optimizer hints described in "Optimizer hints" to disable the use of temporary indexes and tables in order to create plans that trade maximum performance for reduced memory usage.
When determining the execution path for a query, the optimizer examines statistics about the data referenced by the query, such as the number of rows in the tables, the minimum and maximum values and the number of unique values in interval statistics of columns used in predicates, the existence of primary keys within a table, the size and configuration of any existing indexes. These statistics are stored in the SYS.TBL_STATS and SYS.COL_STATS tables, which are populated when an application calls the ttIsql statsupdate command, ttOptUpdateStats, or ttOptEstimateStats built-in procedures.
The optimizer uses the statistics for each table to calculate the selectivity of predicates, such as t1.a=4, or a combination of predicates, such as t1.a=4 AND t1.b<10. Selectivity is an estimate of the number of rows in a table. If a predicate selects a small percentage of rows, it is said to have high selectivity, while a predicate that selects a large percentage of rows has low selectivity.
You can apply hints to pass instructions to the TimesTen query optimizer. The optimizer considers these hints when choosing the best execution plan for your query. You can apply hints as follows:
To apply a hint only for a particular SQL statement, use a statement level optimizer hint.
To apply a hint for an entire transaction, use a transaction level optimizer hint with the appropriate TimesTen built-in procedure.
The query optimizer uses indexes to speed up the execution of a query. The optimizer uses existing indexes or creates temporary indexes to generate an execution plan. An index is a map of keys to row locations in a table. Strategic use of indexes is essential to obtain maximum performance from a TimesTen system.
TimesTen uses these types of indexes:
Hash index: Hash indexes are useful for finding rows with an exact match on one or more columns. They can be designated as unique or not unique. In general, hash indexes are faster than range indexes for exact match lookups and equijoins. However, hash indexes cannot be used for lookups involving ranges or the prefix of a key and can require more space than range indexes and bitmap indexes.
Range index: Range indexes are useful for finding rows with column values within a range specified as an equality or inequality. Range indexes can be created over one or more columns of a table. They can be designated as unique or not unique. When you create an index using the CREATE INDEX SQL statement and do not specify the index type, TimesTen creates a range index.
Bitmap index: Bitmap indexes encode information about a unique value in a row in a bitmap. Each bit in the bitmap corresponds to a row in the table. Use a bitmap index for columns that do not have many unique values. An example of such a column is a column that records gender as one of two values. Bitmap indexes are widely used in data warehousing environments. The environments typically have large amounts of data and ad hoc queries, but a low level of concurrent DML transactions. Bitmap indexes are compressed and have smaller storage requirements than other indexing techniques.
The Index Advisor tool can be used to recommend a set of indexes that could improve the performance of a specific SQL workload. For more details, see "Using the Index Advisor to recommend indexes" in the Oracle TimesTen In-Memory Database Operations Guide.
The optimizer can select from multiple types of scan methods. The most common scan methods are:
Full table scan
Rowid lookup
Range index scan (on either a permanent or temporary index)
Hash index lookup (on either a permanent or temporary index)
Bitmap index lookup (on a permanent index)
TimesTen and IMDB Cache perform fast exact matches through hash indexes, bitmap indexes and rowid lookups. They perform range matches through range indexes. The ttOptSetFlag built-in procedure can be used to allow or disallow the optimizer from considering certain scan methods when choosing a query plan.
A full table scan examines every row in a table. Because it is the least efficient way to evaluate a query predicate, a full scan is only used when no other method is available.
TimesTen assigns a unique ID, called a rowid, to each row stored in a table. A rowid lookup is applicable if, for example, an application has previously selected a rowid and then uses a WHERE ROWID= clause to fetch that same row. Rowid lookups are faster than index lookups.
A range index scan uses a range index to access a table. Such a scan is applicable to exact match predicates such as t1.a=2 or to range predicates such as t1.a>2 and t1.a<10 as long as the column used in the predicate has a range index defined over it. If a range index is defined over multiple columns, it can be used for multiple column predicates. For example, the predicates t1.b=100 and t1.c>'ABC' result in a range index scan if a range index is defined over columns t1.b and t1.c. The index can be used if it is defined over more columns. For example, if a range index is defined over t1.b, t1.c and t1.d, the optimizer uses the index prefix over columns b and c and returns all the values for column d that match the stated predicate over columns b and c.
A hash index lookup uses a hash index to find rows with an exact match on one or more columns. Such lookups are applicable for equality searches over one or more specified columns.
A bitmap index lookup uses a bitmap index to find rows that satisfy an equality predicate such as customer.gender='male'. Bitmap indexes are appropriate for columns with few unique values. They are particularly useful in evaluating several predicates each of which can use a bitmap index lookup because the combined predicates can be efficiently evaluated through bit operations on the indexes themselves. For example, if table customer has a bitmap index on the column gender and if table sweater has a bitmap index on the column color, the predicates customer.gender='male' and sweater.color ='pink' could rapidly find all male customers who purchased pink sweaters by performing a logical AND operation on the two bitmap indexes.
The optimizer can select from multiple join methods. When the rows from two tables are joined, one table is designated the outer table and the other the inner table. The optimizer decides which of the tables should be the outer table and which should be the inner table. During a join, the optimizer scans the rows in the outer and inner tables to locate the rows that match the join condition.
The optimizer analyzes the statistics for each table and, for example, might identify the smallest table or the table with the best selectivity for the query as outer table. If indexes exist for one or more of the tables to be joined, the optimizer takes them into account when selecting the outer and inner tables.
If more than two tables are to be joined, the optimizer analyzes the various combinations of joins on table pairs to determine which pair to join first, which table to join with the result of the join, and so on for the optimum sequence of joins.
The cost of a join is largely influenced by the method in which the inner and outer tables are accessed to locate the rows that match the join condition. The optimizer selects from two join methods when determining the query optimizer plan:
In a nested loop join with no indexes, a row in the outer table is selected one at a time and matched against every row in the inner table. All of the rows in the inner table are scanned as many times as the number of rows in the outer table. If the inner table has an index on the join column, that index is used to select the rows that meet the join condition. The rows from each table that satisfy the join condition are returned. Indexes may be created on the fly for inner tables in nested loops, and the results from inner scans may be materialized before the join.
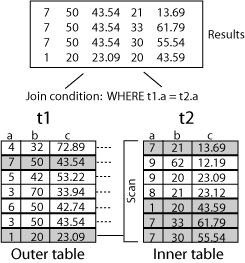
Figure 5-2 shows an example of a nested loop join. The join condition is:
WHERE t1.a=t2.a
For this example, the optimizer has decided that t1 is the outer table and t2 is the inner table. Values in column a in table t1 that match values in column a in table t2 are 1 and 7. The join results concatenate the rows from t1 and t2. For example, the first join result is the following row:
7 50 43.54 21 13.69
It concatenates a row from t1:
7 50 43.54
with the first row from t2 in which the values in column a match:
7 21 13.69
A merge join is used only when the join columns are sorted by range indexes. In a merge join, a cursor advances through each index one row at a time. Because the rows are already sorted on the join columns in each index, a simple formula is applied to efficiently advance the cursors through each row in a single scan. The formula looks something like:
If Inner.JoinColumn < Outer.JoinColumn, then advance inner cursor
If Inner.JoinColumn = Outer.JoinColumn, then read match
If Inner.JoinColumn > Outer.JoinColumn, then advance outer cursor
Unlike a nested loop join, there is no need to scan the entire inner table for each row in the outer table. A merge join can be used when range indexes have been created for the tables before preparing the query. If no range indexes exist for the tables being joined before preparing the query, the optimizer may in some situations create temporary range indexes in order to use a merge join.
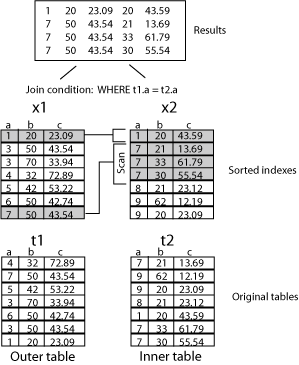
Figure 5-3 shows an example of a merge join. The join condition is:
WHERE t1.a=t2.a
x1 is the index on table t1, sorting on column a. x2 is the index on table t2, sorting on column a. The merge join results concatenate the rows in x1 with rows in x2 in which the values in column a match. For example, the first merge join result is:
1 20 23.09 20 43.59
It concatenates a row in x1:
1 20 23.09
with the first row in x2 in which the values in column a match:
1 20 43.59
Like most database optimizers, the query optimizer stores the details on how to most efficiently perform SQL operations in a query execution plan, which can be examined and customized by application developers and administrators.
The execution plan data is stored in the TimesTen SYS.PLAN table and includes information about which tables are to be accessed and in what order, which tables are to be joined, and which indexes are to be used. You can use either the ttSqlCmdQueryPlan built-in procedure or the ttIsql explain command to display the query plans for recently executed SQL statements. Users can direct the query optimizer to enable or disable the creation of an execution plan in the SYS.PLAN table with the generate plan optimizer hint. (For transaction level hints, use the GenPlan optimizer flag in the ttOptSetFlag built-in procedure; for statement level hints, use the TT_GenPlan hint in the SQL statement.)
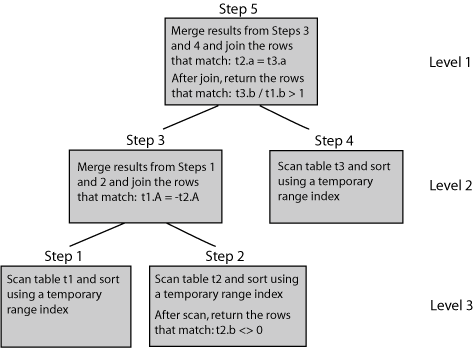
The execution plan designates a separate step for each database operation to be performed to execute the query. The steps in the plan are organized into levels that designate which steps must be completed to generate the results required by the step or steps at the next level.
Consider this query:
SELECT COUNT(*)
FROM t1, t2, t3
WHERE t3.b/t1.b > 1
AND t2.b <> 0
AND t1.a = -t2.a
AND t2.a = t3.a;
In this example, the optimizer breaks down the query into its individual operations and generates a 5-step execution plan to be performed at three levels, as shown in Figure 5-4.
For more information about the query optimizer, see "The TimesTen Query Optimizer" in Oracle TimesTen In-Memory Database Operations Guide.
For more information about indexing, see "Understanding indexes" in Oracle TimesTen In-Memory Database Operations Guide.
Also see descriptions for the CREATE TABLE and CREATE INDEX statements in Oracle TimesTen In-Memory Database SQL Reference.
|
Copyright © 2012, 2013, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|