| Oracle® Warehouse Builder Data Modeling, ETL, and Data Quality Guide 11g Release 2 (11.2) E10935-05 |
|
|
PDF · Mobi · ePub |
| Oracle® Warehouse Builder Data Modeling, ETL, and Data Quality Guide 11g Release 2 (11.2) E10935-05 |
|
|
PDF · Mobi · ePub |
After you finish designing your data warehouse or data mart, you are ready to design your target system. This chapter shows you how to create relational data objects.
This chapter contains the following topics:
Oracle Warehouse Builder supports relational and dimensional data objects. Relational objects, like relational databases, rely on tables and table-derived objects to store and link all of their data. The relational objects you define are physical containers in the database that are used to store data. It is from these relational objects that you run queries after the warehouse has been created. Relational objects include tables, views, materialized views, sequences, user-defined types, and queues. You can also create optional structures associated with relational objects such as constraints, indexes, partitions, and attribute sets.
Dimensional objects contain additional metadata to identify and categorize your data. When you define dimensional objects, you describe the logical relationships that help store the data in a more structured format. Dimensional objects include dimensions and cubes.
The Oracle module contains nodes for each type of relational and dimensional data object that you can define in Oracle Warehouse Builder. In the Projects Navigator, expand the module to view nodes for all the supported data objects.
In addition to relational and dimensional objects, Oracle Warehouse Builder supports intelligence objects. Intelligence objects are not part of Oracle modules. They are displayed under the Business Intelligence node in the Projects Navigator. Intelligence objects enable you to store definitions of business views. You can deploy these definitions to analytical tools such as Oracle Discoverer and perform ad hoc queries on the warehouse.
See Also:
Oracle Warehouse Builder Sources and Targets Guide for more information about creating business definitions for Oracle BI DiscovererList of Oracle Warehouse Builder Data Objects
Table 2-1 describes the types of data objects that you can use in Oracle Warehouse Builder.
Table 2-1 Data Objects in Oracle Warehouse Builder
| Data Object | Type | Description |
|---|---|---|
|
Tables |
Relational |
The basic unit of storage in a relational database management system. a table is created, valid rows of data can be inserted into it. Table information can then be queried, deleted, or updated. To enforce defined business rules on its data, define integrity constraints for a table. See "Defining Tables" for more information. |
|
External Tables |
Relational |
External tables are tables that represent data from non-relational flat files in a relational format. Use an external table as an alternative to using a Flat File operator and SQL*Loader. See Oracle Warehouse Builder Sources and Targets Guide for more information about external tables. |
|
Views |
Relational |
A view is a custom-tailored presentation of data in one or more tables. Views do not actually contain or store data; they derive their data from the tables on which they are based. Like tables, views can be queried, updated, inserted into, and deleted from, with some restrictions. All operations performed on a view affect the base tables of the view. Use views to simplify the presentation of data or to restrict access to data. See "Defining Views" for more information. |
|
Materialized Views |
Relational |
Materialized views are precomputed tables comprising aggregated or joined data from fact and possibly dimension tables. Also known as a summary or aggregate table. Use materialized views to improve query performance. See "Defining Materialized Views" for more information. |
|
Sequences |
Relational |
Sequences are database objects that generate lists of unique numbers. You can use sequences to generate unique surrogate key values. See "Defining Sequences" for more information. |
|
Dimensions |
Dimensional |
A general term for any characteristic that is used to specify the members of a data set. The three most common dimensions in sales-oriented data warehouses are time, geography, and product. Most dimensions have hierarchies. See "Overview of Dimensions" for more information. |
|
Cubes |
Dimensional |
Cubes contain measures and links to one or more dimension tables. They are also known as facts. See "Overview of Cubes" for more information. |
|
Advanced Queues |
Relational |
Advanced queues enable message management and communication required for application integration. See "Creating Advanced Queue Definitions" for more information. |
|
Queue Tables |
Relational |
Queue tables are tables that store queues. Each queue table contains a payload, whose data type is specified at the time of creating the queue table. See "Creating Queue Table Definitions" for more information. |
|
Object Types |
Relational |
An object type is composed of one or more user-defined types or scalar types. See "About Object Types" for more information. |
|
Varrays |
Relational |
A Varray is an ordered collection of elements. See "About Varrays" for more information. |
|
Nested Tables |
Relational |
A nested table complements the functionality of the Varray data type. A nested table permits a row to have multiple "mini-rows" of related data contained within one object. See "About Nested Tables" for more information. |
The metadata for the data objects that you create is stored in the repository. The metadata consists of details such as the attribute or column names, data types, and level names.
Table 2-2 displays the data types that you can use to define columns or attributes.
Table 2-2 Oracle Warehouse Builder Supported Data Types
| Data Type | Description |
|---|---|
|
Stores double-precision IEEE 754-format single-precision floating-point numbers. Used primarily for high-speed scientific computation. Literals of this type end with |
|
|
Stores single-precision IEEE 754-format single-precision floating-point numbers. Used primarily for high-speed scientific computation. Literals of this type end with |
|
|
Stores large binary objects in the database, inline or out-of-line. Every |
|
|
Stores fixed-length character data to a maximum size of 4,000 characters. How the data is represented internally depends on the database character set. You can specify the size in terms of bytes or characters, where each character contains one or more bytes, depending on the character set encoding. |
|
|
Stores large blocks of character data in the database, inline or out-of-line. Both fixed-width and variable-width character sets are supported. Every |
|
|
Stores fixed-length date times, which include the time of day in seconds since midnight. The date defaults to the first day of the current month; the time defaults to midnight. The date function |
|
|
Stores a single-precision, floating-point number. |
|
|
A |
|
|
Stores intervals of days, hours, minutes, and seconds. |
|
|
Stores intervals of years and months. |
|
|
Stores fixed-length character strings. The |
|
|
Stores binary data or byte strings. Use this data type to store graphics, sounds, documents, or arrays of binary data. |
|
|
Stores the geometric description of a spatial object and the tolerance. Tolerance is used to determine when two points are close enough to be considered as the same point. |
|
|
Stores an array of type |
|
|
Stores the dimension name, lower boundary, upper boundary, and tolerance. |
|
|
Stores an array of type |
|
|
Stores Geographical Information System (GIS) or spatial data in the database. For more information, see Oracle Spatial Developer's Guide. |
|
|
Stores the list of all vertices that define the geometry. |
|
|
Stores two-dimensional and three-dimensional points. |
|
|
Stores fixed-length (blank-padded, if necessary) national character data. Because this type can always accommodate multibyte characters, you can use it to hold any Unicode character data. How the data is represented internally depends on the national character set specified when the database was created, which might use a variable-width encoding (UTF8) or a fixed-width encoding (AL16UTF16). |
|
|
Stores large blocks of |
|
|
Stores real numbers in a fixed-point or floating-point format. Numbers using this data type are guaranteed to be portable among different Oracle platforms, and offer up to 38 decimal digits of precision. You can store positive and negative numbers, and zero, in a |
|
|
Stores variable-length Unicode character data. Because this type can always accommodate multibyte characters, you can use it to hold any Unicode character data. How the data is represented internally depends on the national character set specified when the database was created, which might use a variable-width encoding (UTF8) or a fixed-width encoding (AL16UTF16). |
|
|
Stores binary data or byte strings. For example, a |
|
|
|
Base 64 string representing the unique address of a row in its table. This data type is primarily for values returned by the |
|
An Oracle-supplied type that can contain an instance of a given type, with data, plus a description of the type. |
|
|
A type that is the ADT (Abstract Data Type) used to store a A For more information about this data type, see: |
|
|
A type that is the ADT used to store a A For more information about this data type, see: |
|
|
An ADT type that can represent any of five different JMS message types: text message, bytes message, stream message, map message, or object message. Queues created using this ADT can therefore store all five types of JMS messages. For more information about this data type, see Oracle Database PL/SQL Packages and Types Reference: |
|
|
A type that is the ADT used to store a For more information about this data type, see: |
|
|
A type that is the ADT used to store a For more information about this data type, see: |
|
|
A type that represents a data manipulation language (DML) change to a row in a table. This type uses the |
|
|
Extends the |
|
|
Extends the |
|
|
Extends the |
|
|
Represents the address of certain rows in relational tables that are not physical or are not generated by Oracle Database. For example, row address of an index-organized table and row IDs of non-Oracle foreign tables (such as DB2 accessed using a gateway). The maximum size is 4,000 bytes. |
|
|
Stores a length-value data type consisting of a binary length subfield followed by a character string of the specified length. The length is in bytes, unless character-length semantics are used for the data file. In that case, the length is in characters. |
|
|
Stores variable-length character data. How the data is represented internally depends on the database character set. The |
|
|
An object type that is used to specify formatting arguments for |
|
|
You can use an Oracle-supplied type to store and query XML data in the database. It has member functions that you can use to access, extract, and query the XML data by using XPath expressions. XPath is a standard developed by the W3C committee to traverse XML documents. |
|
|
User-defined Types |
Use Oracle built-in data types and other user-defined data types as the building blocks of object types that model the structure and behavior of data in applications. User-defined types include Object Types, Varrays, and Nested tables. |
Oracle Warehouse Builder architecture comprises several classes of objects, such as First Class Objects, Second Class Objects, and Third Class Objects. This section describes these classes of objects.
A First Class Object (FCO) represents a component in the metadata repository that can be manipulated through the Oracle Warehouse Builder interface. FCOs often, but not always, own other objects. For example, a TABLE is an FCO that may own the following Second Class Objects: TABLE_COLUMN, UNIQUE_KEY, FOREIGN_KEY, and CHECK_CONSTRAINT.
For those accessing Oracle Warehouse Builder using the Design Center, FCOs generally appear on the navigation tree. Similarly, users who access Oracle Warehouse Builder through OMB*Plus can generalize FCOs as objects of OMBCREATE, OMBALTER, OMBRETRIEVE, and OMBDROP commands.
A Second Class Object (SCO) represents a dependent object component. An SCO is always owned by another object, and can, in turn, own objects itself. For example, the FCO called MAPPING contains the SCO MAPPING_OPERATOR, which in turn contains ATTRIBUTES.
For those accessing Oracle Warehouse Builder through the Design Center, SCOs can only be manipulated through an FCO. Similarly, users who access Oracle Warehouse Builder through OMB*Plus can only manipulate SCO definitions through a command against an FCO.
Third Class and Fourth Class objects are relative rankings of objects owned by other objects. These refer only to objects whose ownership spans several layers. For example, INDEX_COLUMN is an SCO in the scenario where a DIMENSION_TABLE (which is a FCO) owns INDEX_COLUMN. However, INDEX_COLUMN becomes a Third Class Object in the scenario where the FCO CUBE_TABLE owns the SCO INDEX, which in turn owns INDEX_COLUMN.
The rules for naming data objects depend on the naming mode that you set for Oracle Warehouse Builder. Oracle Warehouse Builder maintains a business and a physical name for each object stored in a workspace. The business name for an object is its descriptive logical name and the physical name is the name used when Oracle Warehouse Builder generates code.
You set the naming mode using the Naming Preferences section of the Preferences dialog box.
See Also:
Oracle Warehouse Builder Concepts for more information about naming preferences.When you name or rename data objects, use the following naming conventions.
In the physical naming mode, the name for an Oracle data object can be between 1 and 30 alphanumeric characters. The name must be unique across the object category that owns the object. Blank spaces are not enabled. Data object names cannot begin with OWB$.
See Also:
For information about the length of physical names on other platforms, see:In the business naming mode, the limit is 200 characters. The name must be unique across the object category that owns the object. For example, because all tables belong to a module, table names must be unique across the module to which they belong. Similarly, module names must be unique across the project to which they belong.
Edit the description of the data object as necessary. The description can be between 1 and 4,000 alphanumeric characters and can contain blank spaces. Specifying a description for a data object is optional.
Best Practices for Naming Data Objects
Data object names or FCO names should be unique across the object category that owns the FCO. Additionally, it is a good practice to ensure that SCO names are unique across the object category that owns the FCO and are different from those of the FCO containing the SCO.
For example, a table contains constraints. The table is an FCO and constraints are SCOs. When you define the table, provide a table name that is unique across the module in which it is defined. Additionally, Oracle recommends that you provide constraint names that are unique across all the FCOs and SCOs in that module.
The Data Viewer enables you to view the data stored in relational and dimensional data objects. For example, the data viewer for a table enables you to view the table data. Similarly, the data viewer for a cube enables you to view data stored in a cube.
To access the Data Viewer for a data object, from the Projects Navigator, right-click the data object and select Data. The Data Viewer containing the data stored in the data object is displayed in a separate tab.
The Data Viewer tab contains the following buttons: Execute Query, Get More, Where Clause, and More. The More button is displayed at the bottom of the tab.
Click Execute Query to run a query on the data object and fetch its data.
By default, the Data Viewer displays the first hundred rows of data. To retrieve the next set of rows, click Get More. Alternatively, you can click More to perform the same action.
Click Where Clause to specify a condition that is used to restrict the data displayed by the Data Viewer. Clicking this button displays the Where Clause dialog box. Use this dialog box to specify the condition used to filter data. You can use this option for tables and views only.
The columns and column names displayed in the Data Viewer are taken directly from the location in which the actual table is deployed.
Note:
For columns with the data typeLONG, the Data Viewer displays "<UNSUPPORTED DATATYPE>" instead of the actual value stored in the column.Oracle Warehouse Builder enables you to create error tables to store logical errors that may occur while loading data into Oracle data objects such as tables, views, materialized view, dimensions, and cubes.
Use error tables to:
Capture logical errors when data rules are applied to tables, views, or materialized views.
Capture physical errors using DML error logging.
Store errors caused by orphan records when an orphan management policy is enabled for dimensional objects.
See Also:
"Orphan Management for Dimensional Objects" for more information about orphan managementAn error table is created for a data object only if you set the Error Table Name configuration parameter for the data object. If you do not specify an error table name for a data object, then logical errors are not logged for that object. However, when a data object has data rules associated with it, even if you do not specify an error table name for the object, Oracle Warehouse Builder creates an error table using a default name. For example, if the name of the table for which you specified data rules is EMP, then the error table is called EMP_ERR.
To create an error table for a data object:
In the Projects Navigator, right-click the data object for which you want to create an error table, and select Configure.
The Configuration tab containing the configuration parameters for the data object is displayed.
In the Configuration tab, expand the Error Tables node.
Set the value of the Error Table Name parameter to the name of the error table for the data object.
If you modify the value of the Error Table Name parameter after the data object is deployed, then you must drop the data object and redeploy it. If this data object was used in mappings, then ensure that you synchronize all operators that are bound to this data object and then redeploy the mappings.
Note:
The Error Table Name and Truncate Error Table configuration parameters of the Table, View, or Materialized View operators are not used for row-based code.In addition to the columns contained in the data object, error tables for a data object contain the columns listed in Table 2-3.
| Column Name | Description |
|---|---|
|
|
Oracle Database error number |
|
|
Oracle Database error message text |
|
|
Row ID of the row in error (for update and delete) |
|
|
Type of operation: insert (I), update (U), delete (D) |
|
|
Step or detail audit ID from the run time audit data. This is the |
For scalar data types, if no data rules are applied to the data object, then the columns in the error table are of data type VARCHAR2(4000). It enables physical data errors such as ORA-12899: value too large for column, to be captured. If data rules are applied, then the columns in the error table are of the same data type as the columns in the data object.
For example, the table TEST has two columns C1, of data type NUMBER, and C2, of data type VARCHAR2(10). The error table generated for TEST contains the DML error columns C1 and C2. If no data rules are applied to TEST, then the data type for both C1 and C2 should be VARCHAR2(4000). If data rules are applied to TEST, then C1 should be NUMBER and C2 of data type VARCHAR2(10).
Tables are metadata representations of relational storage objects. They can be tables from a database system such as Oracle Database or even an SAP system.
The following sections provide information about defining tables:
Tables capture the metadata used to model your target schema. Table definitions specify the table constraints, indexes, partitions, attribute sets, and metadata about the columns and data types used in the table. This information is stored in the workspace. You can later use these definitions to generate.ddl scripts that can be deployed to create physical tables in your target database. These tables can then be loaded with data from chosen source tables.
Ensure that you create the target schema that contains your table as described in "Designing Target Schemas".
To create a table in an Oracle module:
From the Projects Navigator, expand the Databases node and then the Oracle node.
Expand the module where you want to create the table, right-click Tables, and select New Table.
or
Right-click the module where you want to create a table and select New. The New Gallery dialog box is displayed. From the Items section, select Table and click OK.
In the Create Table dialog box, enter a name and an optional description for the table and click OK. Alternatively, you can accept the autogenerated unique name for the table and click OK.
The Table Editor is displayed. Define the table using the following tabs:
After you define the table using these tabs, the table definitions are created and stored in the workspace. The new table name is also added to the Projects Navigator. At this stage, only the metadata for the table is created in the workspace. To create the table in your target schema, you must deploy the table.
Note:
You can also create a table from the Graphical Navigator.Use the Name tab to specify the name and description of a table. This tab contains the following fields:
Name: Represents the name for the table. The name should be unique within the module in which the table is defined.
Description: Specify an optional description for the table.
Follow the rules in "Naming Conventions for Data Objects" to specify a name and an optional description.
Use the Columns tab to define the columns in the table. This tab displays a table that you use to define columns. Each row in the table corresponds to the definition of one table column. Oracle Warehouse Builder generates the column position in the order in which you type in the columns. To reorder columns, see "Reordering Columns in a Table".
Enter the following details for each column:
Name: Enter the name of the column. The column name should be unique within the table.
Data Type: Select the data type of the column from the Data Type list. A default data type is assigned based on the column name. For example, if you create a column named start_date, then the data type assigned is DATE. You can change the default assignment if it does not suit your data requirement.
For a list of supported Oracle Database data types, see "Supported Data Types".
Length: Specify the length of the column. Length is applicable to character data types only.
Precision: Specify the total number of digits enabled for the column. Precision is applicable for numeric data types only.
Scale: Specify the total number of digits to the right of the decimal point. Scale is applicable to numeric data types only.
Seconds Precision: Used for TIMESTAMP, TIMESTAMP WITH TIME ZONE, and TIMESTAMP WITH LOCAL TIME ZONE data types only. Specify the number of digits in the fractional part of the datetime field.
Not Null: Select this field to specify that the column should not contain null values. By default, all columns in a table enable nulls.
Default Value: Specify the default value for this column. If no value is entered for this column while you are loading data into the table, then the default value is used. If you specify a value for this column while loading data, then the default value is overridden and the specified value is stored in the column.
Virtual: Select this option to indicate that the column is a virtual column.
Virtual columns are not stored in the database. They are computed using the expression specified in the Expression field. You can refer to virtual columns just like any other column in the table, except that you cannot explicitly write to a virtual column.
Expression: Specify the expression that is used to compute the value of the virtual column. The expression can include columns from the same table, constants, SQL functions, and user-defined PL/SQL functions.
Description: Enter an optional description for the column.
Use the Keys tab to create constraints on the table columns. You can create primary keys, foreign keys, unique keys, and check constraints. For more information about creating constraints, see "Creating Constraints".
Use the Indexes tab to create indexes on the table. Indexes enable faster retrieval of data stored in your data warehouse. You can create the following types of indexes: unique, nonunique, bitmap, function-based, composite, and reverse. For more information about creating these indexes, see "Creating Indexes".
Use the Partitions tab to create partitions for the table. Partitions enable better manageability of larger tables. They also improve query and load performance. You can create the following types of partitions: range, hash, hash by quantity, list, range-hash, range-hash by quantity and range-list. For more information about partitions and how to create each type of partition, see "Defining Partitions".
Use the Attribute Sets tab to create attribute sets for the table. For more information about creating attribute sets for a table, see "Defining Attribute Sets".
Use the Data Rules tab to apply data rules to a table. Data rules enable you to determine legal data within a table and legal relationships between tables. When you apply a data rule to a table, Oracle Warehouse Builder ensures that the data in the table conforms to the specified data rule.
Oracle Warehouse Builder provides a set of predefined data rules that are listed in the DERIVED_DATA_RULES node under the Data Rules node of the Projects Navigator. You can define your own data rules by creating data rules under the Data Rules node.
Click Apply Rule to apply a data rule to a table. The Apply Data Rule Wizard is displayed. Use this wizard to select the data rule and the column to which the data rule should be applied.
After you apply a data rule to a table, it is listed on the Data rules tab. For the data rule to be applied to a table, ensure that the check box to the left of the data rule name is selected. Deselect this option if you do not want the data rule to be applied to the table.
Use the Table Editor to edit table definitions. To open the editor, right-click the name of the table in the Projects Navigator and select Open. Alternatively, you can double-click the name of the table in the Projects Navigator. This section describes the table definitions that you can edit.
Use one of the following methods to rename a table:
On the Name tab of the table editor, click the Name field and enter the new name for the table. You can also modify the description stored in the Description field.
Alternatively, select the table in the Projects Navigator to display the properties of the table in the Property Inspector. Edit the values of the Physical Name and Description properties.
In the Projects Navigator, select the table you want to rename and press the F2 key. The table name is highlighted. Enter the new table name and press the Enter key.
In the Projects Navigator, right-click the table name and select Rename. The table name is highlighted. Enter the new name for the table and press the Enter key.
Use the Columns tab of the Table Editor to add, modify, and remove table columns.
Navigate to the Columns tab. Click the Name field in an empty row and enter the details that define the new column. For more information, see "Columns Tab".
Use the Columns tab of the Table Editor to modify column definitions. You can modify any of the attributes of the column definition either by entering the new value or selecting the new value from a list. For more information, see "Columns Tab".
Navigate to the Columns tab. Right-click the gray cell to the left of the column name to remove and select Delete.
Navigate to the Keys tab of the Table Editor.
For details on adding and editing constraints, see "Creating Constraints" and "Editing Constraints" respectively.
To delete a constraint, select the row that represents the constraint by clicking the gray cell to the left of the column name. Click Delete at the bottom of the tab.
Use the Attribute Sets tab of the Table Editor to add, modify, or delete attribute sets in a table.
For details about adding attribute sets, see "Creating Attribute Sets". See "Editing Attribute Sets" for instructions on how to edit an attribute set.
To delete an attribute set, navigate to the Attribute Sets tab. Right-click the cell to the left of the attribute set to remove and select Delete.
By default, columns in a table are displayed in the order in which they are created. This order is also propagated to the DDL script generated to create the table. If this default ordering does not suit your application needs, or to further optimize query performance, then you can reorder the columns.
To change the position of a column:
If the Table Editor is not open for the table, then open the editor.
You can do this by double-clicking the name of the table in the Projects Navigator. Alternatively, you can right-click the name of the table in the Projects Navigator and select Open.
On the Columns tab, select the gray square located to the left of the column name.
The entire row is highlighted.
Use the buttons on the left of the Columns tab to move the column to the required position.
The position of the column is now updated.
Close the Table Editor.
You must deploy the changed table definition in order for the new column position in the table to be saved in the workspace.
You can define views and materialized views in Oracle Warehouse Builder. This section describes views. Views are used to simplify the presentation of data or restrict access to data. Often the data that users are interested in is stored across multiple tables with many columns. When you create a view, you create a stored query to retrieve only the relevant data or only data that the user has permission to access.
See Also:
"Defining Materialized Views" for information about materialized viewsA view can be defined to model a query on your target data. This query information is stored in the workspace. You can later use these definitions to generate.ddl scripts that can be deployed to create views in your target system.
This section contains the following topics:
A view definition specifies the query used to create the view, constraints, attribute sets, data rules, and metadata about the columns and data types used in the view. This information is stored in the workspace. You can generate the view definition to create.ddl scripts. These scripts can be deployed to create the physical views in your database.
Ensure that you create the target schema that contains your view as described in "Creating Target Modules".
To define a view:
From the Projects Navigator, expand the Databases node and then the Oracle node.
Expand the target module where you want to create the view, right-click Views, and select New View.
or
Right-click the target module where you want to create the view and select New. In the New Gallery dialog box, select View and click OK.
In the Create View dialog box, enter a name and an optional description for the view and click OK.
The View Editor is displayed.
Note:
The name and description must follow the naming conventions listed in "Naming Conventions for Data Objects".Provide information on the following tabs of the View Editor:
Oracle Warehouse Builder creates a definition for the view, stores this definition in the workspace, and adds this view name in the Projects Navigator.
Note:
You can also define a view from the Graphical Navigator.Use the Name tab to modify the name and description that you provided in the Create View dialog box. Ensure that the name and description follow the rules listed in "Naming Conventions for Data Objects".
Use the Columns tab to define the columns in the view. For each view column, enter the following details: Name, Data Type, Length, Precision, Scale, Seconds Precision, Not Null, Default Value, Virtual, Expression, and Description. For more information about each detail, see "Columns Tab".
Use the Query tab to define the query used to create the view. A view can contain data from tables that belongs to a different module than the one to which the view belongs. You can also combine data from multiple table using joins. Ensure that the query statement you type is valid. Oracle Warehouse Builder does not validate the text in the Query tab and attempts to deploy a view even if the syntax is invalid.
Use the Keys tab to define logical constraints for a view. Although these constraints are not used when enumerating DDL for the view, they can be useful when the view serves as a data source in a mapping. The Mapping Editor can use the logical foreign key constraints to include the referenced dimensions as secondary sources in the mapping. For more information about creating constraints, see "Creating Constraints".
Note:
You cannot create check constraints for views.Use the Attribute Sets tab to define attribute sets for the view. For more information about attribute sets and how to create them, see "Defining Attribute Sets".
Use the Data Rules tab to specify the data rules that are applied to the view. Data rules help ensure data quality by defining the legal data within a table, or legal relationships between tables. For more information about the Data Rules tab, see "Data Rules Tab".
Use the View Editor to edit view definitions. To open the View Editor, right-click the view in the Projects Navigator and select Open. The following sections describe the view definitions that you can edit.
Use the Name tab of the View Editor to rename views. Click the Name field and enter the new name for the view. You can also modify the description stored in the Description field. Enter the new name over the highlighted object name. Alternatively, select the view in the Projects Navigator to display the view properties in the Property Inspector. Edit the values of the Physical Name and Description properties.
Use the Columns tab to add, modify, or delete view columns. For more information, see "Columns Tab".
Adding columns: On the Columns tab, click the Name field in an empty row and enter the details that define a column.
Editing columns: Use the Columns tab of the Table Editor to modify column definitions. You can modify any of the attributes of the column definition.
Removing columns: On the Columns tab, right-click the gray cell to the left of the column name to remove and select Delete.
Use the Keys tab of the View Editor to add, modify, or delete view constraints. For details on adding and editing constraints, see "Creating Constraints" and "Editing Constraints" respectively.
To delete constraints, on the Keys tab, select the row that represents the constraint. Click Delete at the bottom of the tab.
Use the Attribute Sets tab of the View Editor to add, modify, or delete attribute sets. For details about adding attribute sets, see "Creating Attribute Sets". See "Editing Attribute Sets" for instructions on how to edit an attribute set.
To delete an attribute set, navigate to the Attribute Sets tab. Right-click the cell to the left of the attribute set to remove and select Delete.
Materialized views improve query performance. When you create a materialized view, you create a set of query commands that aggregate or join data from multiple tables. Materialized views provide precalculated data that can be reused or replicated to remote data marts. For example, data about company sales is widely sought throughout an organization.
When you create a materialized view, you can configure it to take advantage of the query rewrite and fast refresh features available in Oracle Database. For information about query rewrite and fast refresh, see "Fast Refresh for Materialized Views".
A materialized view definition specifies the query used to create the materialized view, constraints, indexes, partitions, attribute sets, data rules, and metadata about the columns and data types used in the materialized view. You can generate the view definition to obtain.ddl scripts that are used to deploy the materialized view.
Create the target schema that contains your materialized view, as described in "Creating Target Modules".
To define materialized views:
From the Projects Navigator, expand the Databases node and then the Oracle node.
Expand the target module where you want to create the materialized view, right-click Materialized Views, and select New Materialized View.
or
Right-click the target module where you want to create the view and select New. In the New Gallery dialog box, select Materialized View and click OK.
In the Create Materialized View dialog box, enter a name and an optional description for the materialized view and click OK.
The name and description must follow the naming conventions listed in "Naming Conventions for Data Objects".
Provide information on the following tabs of the Materialized View Editor:
Oracle Warehouse Builder creates a definition for the materialized view, stores this definition in the workspace, and inserts its name in the Projects Navigator.
Note:
You can also define a materialized view from the Graphical Navigator.Use the Columns tab to define the materialized view columns. For each column, specify the following details: Name, Data Type, Length, Precision, Scale, Seconds Precision, Not Null, Default Value, and Description. For more information about the details to be provided for each materialized view column, see "Columns Tab".
Use the Query tab to define the query used to create the materialized view. Ensure that you type a valid query in the Select Statement field. For column names, use the same names that you specified on the "Columns Tab". If you change a column name on the columns page, then you must manually change the name in the Query tab. Oracle Warehouse Builder does not validate the text in the Query tab and attempts to deploy a materialized view even if the syntax is invalid.
Use the Keys tab to define constraints for the materialized view. Defining constraints is optional. These constraints are for logical design purposes only and are not used when enumerating DDL for the materialized view. You can create primary keys, foreign keys, and unique keys. For information about creating constraints, see "Creating Constraints".
Note:
You cannot create check constraints for materialized views.Use the Indexes tab to define indexes on the materialized view. Defining indexes is optional. You can create the following types of indexes: Unique, non-Unique, Bitmap, Function-based, Composite, and Reverse. For information about creating indexes, see "Creating Indexes".
Use the Partitions tab to define partitions on the materialized view. Partitioning a materialized view is optional. You can perform "Index Partitioning", "Range Partitioning", "Hash Partitioning", "Hash by Quantity Partitioning", "List Partitioning", or "Composite Partitioning".
Use the Attribute Sets tab to define attribute sets for the materialized view. Defining attribute sets is optional. For information about how to define attribute sets, see "Creating Attribute Sets".
Use the Data Rules tab to specify data rules that must be applied to the materialized view data. For more information, see "Data Rules Tab".
Use the Materialized View Editor to edit a materialized view definition. To open the Materialized View Editor, right-click the materialized view and select Open. The following sections describe the type of editing operations that you can perform on a materialized view.
Double-click the Name field on the Name tab of the editor. This selects the name. Type the new name.
Alternatively, select the materialized view in the Projects Navigator to display the materialized view properties in the Property Inspector. Edit the values of the Physical Name and Description properties.
Use the Columns tab to add, modify, or delete materialized view columns.
Adding columns: On the Columns tab, click the Name field in an empty row and enter the details for the column. For more information about these details, see "Columns Tab".
Removing columns: On the Columns tab, right-click the gray cell to the left of the column name to remove and select Delete.
Use the Keys tab of the Materialized View Editor to add, modify, or delete materialized view constraints. For details on adding and editing constraints, see "Creating Constraints" and "Editing Constraints" respectively.
To delete a constraint, on the Keys tab, select the row that represents the constraint. Click Delete at the bottom of the tab.
Use the Attribute Sets tab to add, modify, or delete attribute sets in a materialized view. For details about adding attribute sets, see "Creating Attribute Sets". See "Editing Attribute Sets" for instructions on how to edit an attribute set.
To delete an attribute set, on the Attribute Sets tab, right-click the cell to the left of the attribute set to remove and select Delete.
You can optionally create constraints on relational data objects such as tables, views, and materialized views.
Constraints are used to enforce the business rules to associate with the information in a database. Constraints prevent the entry of invalid data into tables. Business rules specify conditions and relationships that must always be true, or must always be false.
For example, if you define a constraint for the salary column of the employees table as Salary < 10000, then this constraint enforces the rule that no row in this table can contain a numeric value greater than 10000 in this column. If an INSERT or UPDATE statement attempts to violate this integrity constraint, then an error message is displayed. Remember that constraints slow down load performance.
You can define the following constraints for tables, views, and materialized views:
Unique Key (UK): A UK constraint requires that every value in a column or set of columns (key) be unique. No two rows of a table can have duplicate values in a specified column or set of columns. A UK column can also contain a null value.
Primary Key (PK): A value defined on a key (column or set of columns) specifying that each row in the table can be uniquely identified by the values in the key (column or set of columns). No two rows of a table can have duplicate values in the specified column or set of columns. Each table in the database can have only one PK constraint. A PK column cannot contain a null value.
Foreign Key (FK): A rule defined on a key (column or set of columns) in one table that guarantees that the values in that key match the values in a PK or UK key (column or set of columns) of a referenced table.
Check Constraint: A user-defined rule for a column (or set of columns) that restricts inserts and updates of a row based on the value it contains for the column (or set of columns). A Check condition must be a Boolean expression that is evaluated using the values in the row being inserted or updated.
For example, the condition Order Date < Ship Date checks that the value of the Order Date column is always less than that of the Ship Date column. If not, there is an error when the table is loaded and the record is rejected. A check condition cannot contain subqueries and sequences or SYSDATE, UID, USER, or USERENV SQL functions. Although check constraints are useful for data validation, they slow load performance.
Use the Keys tab of the object editors to create constraints. You can create the following types of constraints: primary key, foreign key, unique key, and check constraints.
To create constraints on a table, view, or materialized view:
Open the editor for the data object to which you want to add constraints.
In the Projects Navigator, double-click the data object on which you want to define a constraint. Alternatively, you can right-click the data object in the Projects Navigator and select Open.
Navigate to the Keys tab.
Depending on the type of constraint to define, see one of the following sections:
To define a primary key constraint:
On the Keys tab, click the Add Constraint button.
A blank row is displayed with the cursor positioned in the Name column.
Enter the name of the constraint in the Name column.
Constraint names must be unique within the module that contains the data object on which the constraint is defined.
In the Type column, select Primary Key.
Press the Tab key to exit from the Type column or use the mouse and click the empty space in the Keys tab.
Click Add Local Column.
A new row is added below the current row that contains the constraint name and constraint type. This new row displays a list in the Local Columns column.
In the Local Columns list of the new row, select the name of the column that represents the primary key.
(Optional) To create a composite primary key, repeat Steps 4 and 5 for each column to add to the primary key.
To define a foreign key constraint:
On the Keys tab, click the Add Constraint button.
A blank row is displayed with the cursor positioned in the Name field.
Enter the name of the constraint in the Name column.
Constraint names must be unique within the module that contains the data object on which the constraint is defined.
In the Type column, select Foreign Key.
Press the tab key to navigate out of the Type column or use the mouse and click the empty space in the Keys tab.
In the References column, click the Ellipsis button.
The Key Selector dialog box is displayed.
In the Key Selector dialog box, select the primary key constraint that the foreign key being created references.
For example, the DEPARTMENTS table has a primary key called DEPT_PK defined on the department_id column. To specify that the column department_id of the EMPLOYEES table is a foreign key that references the primary key DEPT_FK, select DEPT_FK under the node that represents the DEPARTMETNS table in the Key Selector dialog box.
Click OK.
To define a unique key constraint:
On the Keys tab, click the Add Constraint button.
A blank row is displayed with the cursor positioned in the Name field.
Enter the name of the constraint in the Name column and press the Enter key.
You can also press the Tab key or click any other location in the editor.
Constraint names must be unique within the module that contains the data object on which the constraint is defined.
In the Type column, select Unique Key.
Press the tab key to navigate out of the Type column or use the mouse and click the empty space in the Keys tab.
Click Add Local Column.
A new row is added below the current row that contains the constraint name and constraint type. This new row displays a list in the Local Columns column.
In the Local Columns list of the new row, select the name of the column on which a unique key should be created.
(Optional) To create a composite unique key, repeat steps 4 and 5 for each column to add to the unique key.
To define a check constraint:
On the Keys tab, click the Add Constraint button.
A blank row is displayed with the cursor positioned in the Name field.
Enter the name of the constraint in the Name column and press the Enter key.
You can also press the Tab key or click any other location in the editor.
Constraint names must be unique within the module that contains the data object on which the constraint is defined.
In the Type column, select Check Constraint.
Press the tab key to exit from the Type column or use the mouse and click the empty space in the Keys tab.
In the Check Condition column, enter the condition to be applied for the check constraint. For example, salary > 2000. If you leave this field blank, then an error is generated during validation and you cannot generate valid code for this constraint.
The column name referenced in the check condition must exactly match the physical column name defined in the table. Oracle Warehouse Builder does not check the syntax of the condition during validation. This may result in errors during deployment. If this happens, then check the Repository Browser for details.
You can edit constraints using the Keys tab of the object editors to accomplish the following tasks:
Rename a constraint
Change the constraint type
Modify the check condition
Modify the referenced column for a foreign key constraint
Modify the primary key column for a primary key
After editing constraint definitions, ensure that you regenerate and redeploy the data object containing the modified constraints.
Use indexes to enhance query performance of your data warehouse. In Oracle Warehouse Builder, you can define indexes for tables and materialized views. In the following sections, the word table refers to all objects for which you can define indexes.
Indexes are important for speeding queries by quickly accessing data processed in a warehouse. You can create indexes on one or more columns of a table to speed SQL statement execution on that table. Indexes have the following characteristics:
Indexes provide pointers to the rows in a table that contain a given key value.
Index column values are stored presorted.
Because the database stores indexes in a separate area of the database, you can create and drop indexes at any time without affecting the underlying table.
Indexes are independent of the data in the table. When you delete, add, or update data, the indexes are maintained automatically.
See Also:
Oracle Database Data Warehousing Guide for more information about indexing strategiesYou create indexes by using the Indexes tab in the editor. To start the editor, navigate to the table or other data object on the Projects Navigator and double-click it, or right-click and select Open. When you select an index type, Oracle Warehouse Builder displays the appropriate template enabling you to create the index. Index names must be unique within the module that contains the data object on which the indexes are defined.
For all types of indexes except bitmap indexes, you can determine whether the index inherits the partitioning method of the underlying table. An index that inherits its partitioning method is known as a local index whereas an index with its own partitioning method is known as a global index. For additional information, see "Index Partitioning".
You can create the following types of indexes in Oracle Warehouse Builder:
Unique: These indexes ensure that no two rows of a table have duplicate values in the key column or composite key columns.
Non-Unique: These are B-tree type indexes that do not impose restrictions against duplicate values in the key column or composite key columns.
Bitmap: These indexes are primarily used for data warehousing applications to enable the querying of large amounts of data. These indexes use bitmaps as key values instead of a list of row IDs. Bitmaps are effective when the values for the index key comprise a small list. For example, AGE_GROUP could be a good index key but AGE would not.
Bitmaps enable star query transformations, which are cost-based query transformations aimed at efficiently executing star queries. A prerequisite of the star transformation is that a bitmap index must be built on each of the foreign key columns of the cube or cubes.
When you define a bitmap index in Oracle Warehouse Builder, set its scope to LOCAL and partitioning to NONE.
Function-based: These indexes compute and store the value of a function or expression that you define on one or more columns in a table. The function can be an arithmetic expression that contains a PL/SQL function, package function, C callout, or SQL function.
Composite: Also known as concatenated indexes, these are indexes on multiple columns. The columns can be in any order in the table and need not be adjacent to each other.
To define a composite index in Oracle Warehouse Builder, create the index as you would any other index and assign between 2 and 32 index columns.
Reverse: For each indexed column except for the row ID column, this index reverses the bytes in the columns. Because the row ID is not reversed, this index maintains the column order.
To define a reverse index in Oracle Warehouse Builder, create the index as you would any other index and then go to the Configurations tab of the data object and set the Index Sorting parameter listed under the Performance Parameters to REVERSE.
Partitions enable you to efficiently manage very large tables and indexes by dividing them into smaller, more manageable parts. Partitions improve query and load performance because operations work on subsets of data. Use partitions to enhance data access and improve overall application performance, especially for applications that access tables and indexes with millions of rows and many gigabytes of data.
In Oracle Warehouse Builder, you can define partitions for tables, indexes, materialized views, and MOLAP cubes. For brevity, in the following sections, the word table is used to refer to all objects for which you can define partitions. The following sections discuss partitioning for all the objects previously listed except partitioning MOLAP cubes, which is described separately.
You define partitions for these objects by using the Partitions tab in the object editors. Depending on the type of partition that you create, you must configure tablespaces for the partitions in the Configuration tab.
You can perform the following types of partitioning:
"Range Partitioning": Use range partitioning to create partitions based on a range of values in a column. When you use range partitioning with a date column as the partition key, you can design mappings that instantly update target tables, as described in "Improved Performance through Partition Exchange Loading".
"Hash Partitioning": Use hash partitioning to direct Oracle Database to evenly divide the data across a recommended even number of partitions. This type of partitioning is useful when data is not historical and there is no obvious column or column list.
"Hash by Quantity Partitioning": To quickly define hash partitioning, use Hash by quantity partitioning. This equals hash partitioning except that you specify only a partition key and the number of partitions. The partitions are created and named automatically. You can then configure the partitions to share the same tablespace list.
"List Partitioning": Use list partitioning to explicitly assign rows to partitions based on a partition key that you select. It enables you to organize the data in a structure not available in the table.
"Composite Partitioning": You can use Oracle Warehouse Builder to specify a composite of either range-hash, range-hash by quantity, or range-list partitioning. Oracle Database first performs the range partitioning and then further divides the data using the second partitioning that you select. For example, in range-list partitioning, you can base partitions on the sales transaction date and then further divide the data based on lists of states where transactions occurred.
"Index Partitioning": You can define an index that inherits the partitioning method of its underlying table. Or, you can partition an index with its own partitioning strategy.
Depending on the partition type that you create, the Partitions tab is dynamically altered to display only the relevant information. Columns or rows on this tab that are not required for a particular partition type are hidden.
For example, when you create a range or list partition, since you cannot create subpartitions, the rows Subpartition Key and Subpartition Template are hidden. When you create a range-hash partition, the Subpartition Template row contains an entry for Hash Subpartition Quantity with the condition "=".
The conditions that define the upper bound for subpartitions depend on the type of partitioning method used. For example, for a range-list partition, the condition enabled for determining the upper bound for a partition must be based on equality. Thus, the column that contains the condition (the column between the Partition and Value columns) contains "=" and is disabled. However, the condition for determining the upper bound for the subpartition is displayed as "<" and you cannot edit this field.
Range partitioning is the most common type of partitioning and is often used to partition data based on date ranges. For example, you can partition sales data into monthly partitions.
To use range partitioning, go to the Partitions tab in the editor to specify a partition key and assign a name and value range for each partition you want to create.
To partition data by range:
On the Partitions tab in the object editor, click the cell under Type and select Range.
If necessary, click the plus sign to the left of Type to expand the template for the range partition.
Select a partition key under the Partition Key node.
Oracle Warehouse Builder lists all the columns for the object you selected under Key Columns. You can select a column of any data type; however, DATE is the most common partition key for range partitioning.
You can base the partition key on multiple key columns. To add another key column, select the partition key node and click Add.
Define the partitions under the Partitions node.
To assist you in defining the partitions, the template offers two partitions that you can edit but not delete. P1 represents the first partition and PDEFAULT represents the last partition. To partition data based on month, then you can rename P1 to Jan and PDEFAULT to Dec.
The last partition is set to the keyword MAXVALUE, which represents a virtual infinite value that sorts higher than any other value for the data type, including the null value.
To add more partitions between the first and last partitions, click the Partitions node and select Add.
In Values, specify the greatest value for the first range and all the additional ranges that you create. These values are the less than values.
Figure 2-1 shows how to define a partition for each quarter of a calendar year.
Figure 2-1 Example Table with Range Partitioning
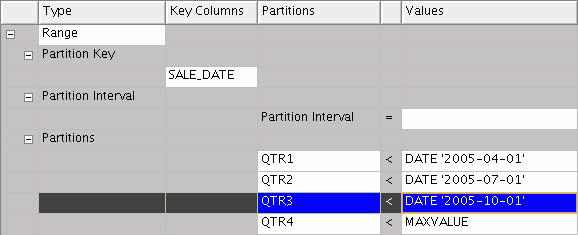
You can also partition data for each month or week. When you design mappings using such a table, consider enabling Partition Exchange Loading (PEL). PEL is a data definition language (DDL) operation that swaps existing partitions on the target table with new partitions. Because it is not a data manipulation language (DML) operation, the exchange of partitions occurs instantaneously.
Hash partitioning assigns data to partitions based on a hashing algorithm that Oracle Database applies to a partitioning key you identify. The hashing algorithm evenly distributes rows among partitions, giving partitions approximately the same size. Hash partitioning is a good and easy-to-use alternative to range partitioning when data is not historical and there is no obvious column or column list where logical range partition pruning can be advantageous.
To partition data based on the hash algorithm:
On the Partitions tab in the object editor, click the cell below Type and select Hash.
If necessary, click the plus sign to the left of Type to expand the template for defining hash partitions.
Select a partition key in the Key Columns column under the Partition Key node.
Oracle Warehouse Builder lists all the columns for the object you selected. You can select a column of any data type.
Define the partitions under the Partitions node.
Oracle Warehouse Builder provides two partitions that you can rename. Click the Partitions node and select Add to add as many partitions as necessary.
Oracle Database uses a linear hashing algorithm. To prevent data from clustering within specific partitions, you should define the number of partitions by a power of two (for example, 2, 4, 8).
Use hash by quantity partitioning to quickly define hash partitioning. When you define a partition key and specify the number of partitions, the partitions are automatically created and named. You can then configure the partitions to share the same tablespace list.
To partition data based on the hash by quantity algorithm:
On the Partitions tab in the object editor, click the cell below Type and select Hash by Quantity.
If necessary, click the plus sign to the left of Type to expand the template for defining hash by quantity partitions.
Define the partition key using the Partition Key column under the Partition Key node.
Define the number of partitions in the Values column under the Partitions node. The default value is two partitions.
Oracle Database uses a linear hashing algorithm and, to prevent data from clustering within specific partitions, you should define the number of partitions by a power of two (for example, 2, 4, 8).
In the Configuration tab, define the "Partition Tablespace List" and "Overflow Tablespace List".
To display the Configuration tab for a data object, right-click the data object and select Configure.
List partitioning enables you to explicitly assign rows to partitions. You can achieve this by specifying a list of discrete values for each partition. The advantage of list partitioning is that you can group and organize unordered and unrelated sets of data in a natural way.
Figure 2-2 shows an example of a table partitioned into list partitions based on the instructions described below.
To partition data based on a list of values:
On the Partitions tab in the object editor, click the cell below Type and select List.
If necessary, click the plus sign to the left of Type to expand the template for defining list partitions.
Select a partition key using the Key Columns column under the Partition Key node.
Oracle Warehouse Builder lists all the columns for the object you selected. You can select a column of any data type.
Define the partitions under the Partitions node.
PDEFAULT is set to the keyword DEFAULT and includes all rows not assigned to any other partition. A partition that captures all unassigned rows is essential for maintaining the integrity of the data.
To assist you in defining the partitions, the template offers two partitions that you can edit but not delete. P1 represents the first partition and PDEFAULT represents the last partition.
To add more partitions between the first and last partitions, click the Partitions node and select Add.
In Values, enter a comma-delimited list of values for each partition that corresponds to data in the partition key you previously selected. For example, if the partition key is COUNTRY_ID, then you can create partitions for Asia, Eastern Europe, Western Europe, and so on. Then, for the values for each partition, list the corresponding COUNTRY_IDs for each country in the region.
Figure 2-2 shows a table with data partitioned into different regions by using list partitioning based on the COUNTRY_ID column. Each partition has a single comma-separated list.
Figure 2-2 List Partitioning Based on a Single Key Column
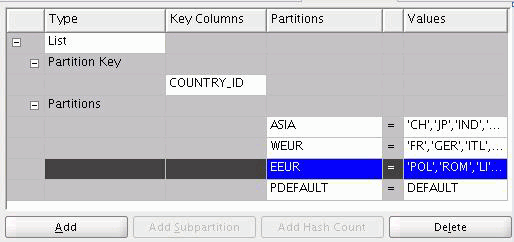
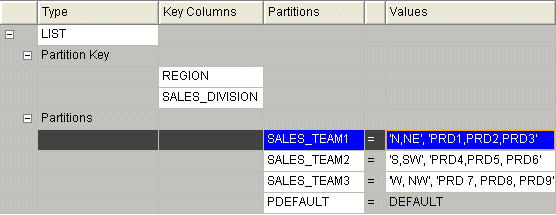
Figure 2-3 shows a table with data partitioned based on key columns REGION and SALES_DIVISION. Each partition includes two comma-separated lists enclosed by single quotation marks. In this example, N, NE, S, SW, W, and NW correspond to REGION while PRD1, PRD2, PRD3, and so on correspond to SALES_DIVISION.
Figure 2-3 List Partitioning Based on Multiple Key Columns
Composite partitioning methods include range-hash, range-hash by quantity, and range-list partitioning. Oracle Database first performs the range partitioning and then further divides the data using the second partitioning that you select.
The steps for defining composite partition methods are similar to those used to define simple partition methods such as (range, hash, and list) but include additional options.
To partition data based on range and then subpartition based on list, hash, or hash by quantity:
On the Partitions tab in the object editor, click the cell below Type and select one of the composite partitioning methods.
If necessary, click the plus sign to the left of Type to expand the template.
Select a partition key and define partitions as described in "Range Partitioning".
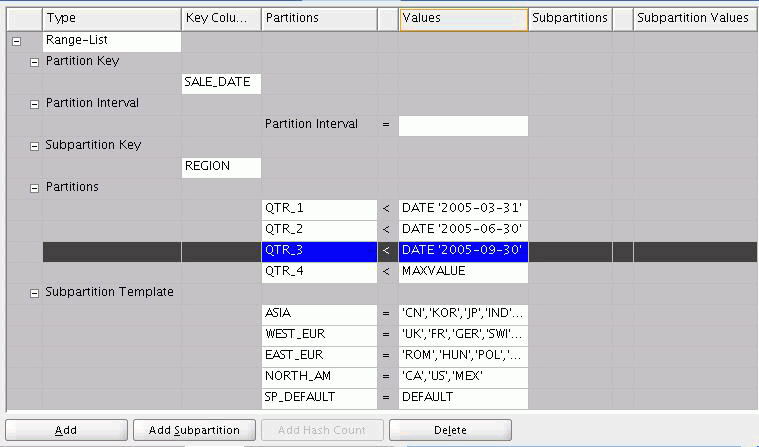
In Figure 2-4, the partition key is SALE_DATE and its associated range partitions are QTR_1, QTR_2, QTR_3, and QTR_4.
Figure 2-4 Range-List Partitioning with List Defined Under a Subpartition Template
Select a column for the subpartition key in the Key Columns list under the Subpartition Key node.
Under the Subpartition Template node, define the values for the second partitioning method as described in "About the Subpartition Template".
(Optional) Define custom subpartitions.
For range-list partitions, you can specify custom subpartitions that override the defaults you defined under the subpartition node. For details, see "Creating Custom Subpartitions".
Configure the "Partition Tablespace List" and "Overflow Tablespace List" in the Configuration tab.
To display the Configuration tab for a data object, right-click the data object and select Configure.
Use the subpartition template to specify the second partitioning method in composite partitioning. The steps you take depend on the type of composite partition you select.
For range-hash by quantity, enter the number of subpartitions only.
For range-hash, the subpartition template enables you to enter names for the subpartitions only.
For range-list, name the lists and enter comma-delimited values. Be sure to preserve the last subpartition as set to DEFAULT.
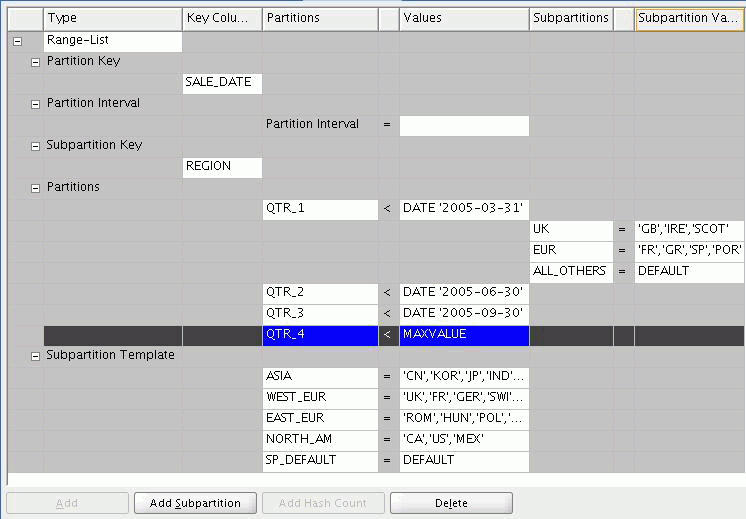
Figure 2-4 shows a list subpartition based on the REGION key column and subpartitions for groups of countries. Oracle Warehouse Builder divides each partition (such as QTR_1 and QTR_2) into subpartitions (such as ASIA and WEST_EUR).
Using the subpartition template is the most convenient and likely the most common way to define subpartitions. Entries that you specify under the Subpartition Template node apply uniformly to all the partitions under the partition node. However, in some cases, you may want to override the subpartition template.
For range-hash by quantity, select a partition and then click Add Hash Count. Oracle Warehouse Builder expands the partition node to enable you to specify the number of hash subpartitions that uniquely apply to that partition.
For range-hash, select a partition and then click Add Subpartition. Oracle Warehouse Builder expands the partition node and you can name subpartitions for that partition only.
For range-list, select a partition and then click Add Subpartition. Oracle Warehouse Builder expands the partition node to enable you to specify list subpartitions for that partition only. Be sure to preserve the last subpartition as set to DEFAULT.
Figure 2-5 shows that partition QTR_1 is subpartitioned into lists for UK, EUR, and ALL_OTHERS whereas the other quarters are partitioned according to the subpartition template.
Figure 2-5 Subpartitions Overriding Subpartition Template
For all types of indexes except bitmap indexes, you can determine whether the index inherits the partitioning method of the underlying table. An index that inherits the partitioning method of the underlying table is known as a local index. An index with its own partitioning method is known as a global index.
Local indexes are partitioned on the same columns and have the same definitions for partitions and subpartitions as specified on the underlying table. Furthermore, local indexes share the same tablespaces as the table.
For example, if you used range-list partitioning to partition a table of sales data by quarter and then by region, then a local index is also partitioned by quarter and then by region.
Bitmap indexes can only be defined as local indexes to facilitate the best performance for querying large amounts of data.
To define an index as local in Oracle Warehouse Builder set the Scope to LOCAL and Partitioning to NONE.
A global index is one in which you can partition the index independently of the partition strategy applied to the underlying table. You can choose between range or hash partitioning. The global index option is available for all indexes except bitmap indexes.
In releases before Oracle Database 10g, Oracle recommended that you not use global indexes for data warehouse applications because deleting partitions on the table during partition maintenance would invalidate the entire index and result in having to rebuild the index. Beginning with Oracle Database 10g, this is no longer a limitation, as global indexes are no longer negatively affected by partitioning maintenance.
Nonetheless, local indexes are likely to be the preferred choice for data warehousing applications due to ease in managing partitions and the ability to parallelize query operations.
A global index is useful when you want to specify an index partition key other than any of the table partition keys. For a global index, ensure that there are no duplicate rows in the index key column and select unique for the index type.
For some but not all partitioning methods, you must configure partition tablespaces.
You can access the parameters for partitions using the Projects Navigator. Right-click the table and select Configure to display the Configuration tab for the table. Scroll down to view the Partition Parameters node.
Enter a comma-delimited list of tablespaces when you partition by any of the following methods: hash by quantity, range-list, range-hash, or range-hash by quantity.
If you neglect to specify partition tablespaces, then the default tablespaces associated with the table are used and the performance advantage for defining partitions is not realized.
Enter a comma-delimited list of tablespaces when you partition by the method hash by quantity. If you provide a list of tablespaces less than the number of partitions, then the Oracle Database cycles through those tablespaces.
If you neglect to specify overflow tablespaces, then the default tablespaces associated with the table are used and the performance advantage for defining partitions is not realized when the limits for the partition tablespaces are exceeded.
An attribute set contains a chosen set of columns. Attribute sets are useful while defining a mapping or during data import and export. Oracle Warehouse Builder enables you to define attribute sets for tables, views, and materialized views. For brevity, in the following sections, the word table is used to refer to all objects for which you can define attribute sets.
Use the Attribute Sets tab of the object editors to create attribute sets. You can define attribute sets for tables, views, and materialized views.
To define an attribute set:
From the Projects Navigator, right-click the object name in which the attribute set is to be defined and select Open.
The object editor is displayed.
Select the Attribute Sets tab.
This tab contains two sections: Attribute sets and Attributes of the selected attribute set.
The Attribute sets section displays the attribute sets defined for the table. It contains two columns that define each attribute set: Name and Description.
The Attributes of the selected attribute set section lists all the attributes in the table. The attributes that are selected using the Include column are the ones that are included in the attribute set that is selected in the Attribute sets section.
In the Attribute sets section, click the Name field of an empty row and enter a name for the attribute set.
In physical mode, you must enter a name between 1 and 30 valid characters. Spaces are not enabled. In logical mode, you can enter up to 200 valid characters. The attribute set name must be unique within the object.
Notice that all the table attributes are displayed in the Attributes of the selected attribute set section.
In the Attributes of the selected attribute set section, select Include for each attribute you want to include in the attribute set. The order in which you select the columns determines their initial order in the attribute set.
Click Select All to select all the displayed columns in the attribute set. Click Deselect All to exclude all the columns from the attribute set. To remove a column from the attribute set, deselect Include.
Use the Attribute Sets tab of the object editor to edit attribute sets. Before you edit an attribute set, ensure that the editor is open for the object that contains the attribute set. Also, navigate to the Attribute Sets tab of the editor.
You can perform the following actions when you edit an attribute set:
Rename the attribute set
Click the name of the attribute set in the Name column of the Attribute sets of the entity section and enter the new name.
Add or remove attributes from the attribute set
Adding attributes to an attribute set: Select the attribute set to which you want to add attributes by clicking the gray cell to the left of the attribute set name in the Attribute sets section. In the Attributes of the selected attribute set section, select Include for each attribute to include in the attribute set.
Removing attributes from an attribute set: Select the attribute set from which you want to remove attributes by clicking the gray cell to the left of the attribute set. In the Attributes of the selected attribute set section, unselect Include for the attributes to remove from the attribute set.
Delete the attribute set
In the Attribute Sets section, right-click the gray cell to the left of the attribute set name and select Delete.
A sequence is a database object that generates a serial list of unique numbers. You can use sequences to generate unique primary key values and to coordinate keys across multiple rows or tables. Sequence values are guaranteed to be unique. When you create a sequence, you are creating sequence definitions that are saved in the workspace. Sequence definitions can be used in mappings to generate unique numbers while transforming and moving data to your target system.
The following sections provide information about using sequences:
A sequence is referenced in SQL statements with the NEXTVAL and CURRVAL pseudocolumns. Each new sequence number is incremented by a reference to the pseudocolumn NEXTVAL, whereas the current sequence number is referenced using the pseudocolumn CURRVAL. These attributes are created when you define a sequence.
You can also import sequence definitions from existing source systems using the Metadata Import Wizard.
To create a sequence:
From the Projects Navigator, expand the Databases node and then the target module node.
Right-click Sequences and select New Sequence from the menu.
Oracle Warehouse Builder displays the Create Sequence dialog box.
Use the Name field to specify a name and the Description field to specify an optional description for the sequence.
In addition to the rules listed in "Naming Conventions for Data Objects", the name must be unique across the module.
Click OK.
Oracle Warehouse Builder stores the definition for the sequence and inserts its name in the Projects Navigator.
Use the Edit Sequence dialog box to edit a sequence definition. You can edit the name, description, and column notes of a sequence.
To edit sequence properties, right-click the name of the sequence from the Projects Navigator and select Open. Or double-click the name of the sequence. The Edit Sequence dialog box is displayed. This dialog box contains two tabs: "Name Tab" and "Columns Tab". Use these tabs to rename a sequence or edit sequence columns.
Rename a sequence by typing the new name in the Name field. You can also rename a sequence by right-clicking the sequence name in the Projects Navigator and selecting Rename.
Follow the rules in "Naming Conventions for Data Objects" to specify the name and description.
To modify a sequence description, enter the new description in the Description field.
The Columns tab displays the sequence columns CURRVAL and NEXTVAL.
User-defined data types use Oracle built-in data types and other user-defined data types as the building blocks of object types that model the structure and behavior of data in applications. The built-in data types are mostly scalar types and do not provide the same flexibility that modeling an application-specific data structure does.
User-defined data types extend the modeling capabilities of native data types by specifying both the underlying persistent data (attributes) and the related behaviors (methods). With user-defined types, you can create better models of complex entities in the real world by binding data attributes to semantic behavior.
Consider a simple example of a Customers table. The Customer address information is usually modeled as four or five separate fields, each with an appropriate scalar type. User-defined types enable for a definition of "address" as a composite type and also to define validation on that type.
Oracle Warehouse Builder enables you to define the following user-defined data types:
Object types
Varrays
Nested tables
Object types are abstractions of the real-world entities, such as purchase orders, that application programs deal with. An object type is a heterogeneous user-defined type. It is composed of one or more user-defined types or scalar types.
An object type is a schema object with the following components:
Name: A name identifies the object type uniquely within that schema.
Attributes: An attribute is used to create the structure and state of the real-world entity that is represented by an object. Attributes can be built-in types or other user-defined types.
Methods: A method contains functions or procedures that are written in PL/SQL or Java and stored in the database, or written in a language such as C and stored externally. Methods are code-based representations of the operations that an application can perform on the real-world entity.
Note:
Methods are currently not supported.For example, the ADDRESS type definition can be defined as follows:
CREATE TYPE ADDRESS AS OBJECT (street_name varchar2(240), door_no varchar2(30), po_box_no number, city varchar2(35), state varchar2(30), country varchar2(30));
the type has been defined it can be used across the schema for any table that requires the type definition "address" as one of its fields.
To define an object type:
In the Projects Navigator, expand the Databases node and then the Oracle node.
Expand the target module in which you want to create the object type.
Expand the User Defined Types node.
Right-click Object Types and select New Object Type.
The Create Object Type dialog box is displayed.
Enter a name and an optional description for the object type and click OK.
The Object Type Editor is displayed. Use the following tabs on the editor to define the object type:
Use the Name field to enter a name for the object type. Use the Description field to enter an optional description for the object type. To rename an object type, select the name and enter a new name.
Follow the rules in "Naming Conventions for Data Objects" to specify a name and description.
Use the Columns tab to define the attributes in the object type. This tab displays a table that you can use to define attributes. Each row in the table corresponds to the definition of one object type attribute.
Specify the following details for each attribute:
Name: Enter the name of the attribute. The attribute name must be unique within the object type.
Data Type: Select the data type of the attribute from the Data Type list. Oracle Warehouse Builder assigns a default data type for the attribute based on the name. For example, if you create an attribute named start_date, then the data type assigned is DATE. You can change the default assignment if it does not suit your data requirement.
See Also:
"Supported Data Types" for a list of supported Oracle Database data typesLength: Specify the length of the attribute. Length is applicable to character data types only.
Precision: Specify the total number of digits enabled for the attribute. Precision is applicable for to data types only.
Scale: Specify the total number of digits to the right of the decimal point. Scale is applicable to numeric data types only.
Seconds Precision: Specify the number of digits in the fractional part of the datetime field. Seconds precision is used for TIMESTAMP, TIMESTAMP WITH TIME ZONE, and TIMESTAMP WITH LOCAL TIME ZONE data types.
Not Null: Select this field to specify that the attribute should not contain NULL values. By default, all columns in a table enable nulls. This column is not applicable to object types.
Default Value: Specify the default value for this attribute. If no value is entered for this column while data is stored in the table, then the default value is used. If you specify a value for this column while loading data, then the default value is overridden and the specified value is stored in the column. This column is not applicable for object types.
Virtual: Select this option to indicate that the attribute behaves like a virtual column.
Virtual columns are not stored in the database. They are computed using the expression specified in the Expression field. You can refer to virtual columns just like any other column in the table, except that you cannot explicitly write to a virtual column.
Expression: Specify the expression that is used to compute the value of the virtual attribute. The expression can include columns from the same table, constants, SQL functions, and user-defined PL/SQL functions.
Description: Type an optional description for the attribute.
To edit an object type:
In the Projects Navigator, expand the Databases node and then the Oracle node.
Expand the module that contains the object type.
Expand the User Defined Types node and then the Object Types node.
Right-click the object type to edit and select Open.
The Object Type Editor is displayed. Use the Name and Columns tabs as defined in "Defining Object Types" to edit the definition of the object type.
A Varray is an ordered collection of data elements. The position of each element in a Varray is stored as an index number. You can use this number to access particular elements. When you define a Varray, you specify the maximum number of elements it can contain. You can change this number later. Varrays are stored as opaque objects (such as RAW or BLOB).
If the customer has multiple address, for example three addresses, then you can create another type, a table type, that holds three addresses. The following example creates a table of ADDRESS type:
TYPE address_store is VARRAY(3) of address;
The first address in the list is considered as the primary address and the remaining addresses are considered as the secondary addresses.
To define a Varray:
From the Projects Navigator, expand the Databases node and then the Oracle node.
Expand the target module in which you want to create the Varray.
Expand the User Defined Types node.
Right-click Varrays and select New Varray.
The Create Varray dialog box is displayed.
Enter a name and an optional description for the Varray and click OK.
The Varray Editor is displayed. Use the following tabs on the editor to define the object type:
Use the Name field to enter a name for the Varray. Use the Description field to enter an optional description for the Varray. To rename a Varray, select the name and enter a new name.
Follow the rules in "Naming Conventions for Data Objects" to specify a name and an optional description.
Use the Details tab to specify the value for the following fields:
Data Type: Select the data type of the attribute from the Data Type list.
See Also:
"Supported Data Types" for a list of supported Oracle Database data typesLength: Specify the length of the Varray element. Length is applicable for character data types only.
Precision: Specify the total number of digits enabled for the Varray element. Precision is applicable to numeric data types only.
Scale: Specify the total number of digits to the right of the decimal point. Scale is applicable to numeric data types only.
Seconds Precision: Specify the number of digits in the fractional part of the datetime field. Seconds precision is used for TIMESTAMP, TIMESTAMP WITH TIME ZONE, and TIMESTAMP WITH LOCAL TIME ZONE data types only.
Size: Specify the size of the Varray.
To edit a Varray:
From the Projects Navigator, expand the Databases node and then the Oracle node.
Expand the module that contains the Varray type.
Expand the User Defined Types node and then the Varrays node.
Right-click the Varray to edit and select Open.
The Varray Editor is displayed. Use the Name and Details tabs of the Varray Editor, as described in "Defining Varrays", to edit the definition of the Varray.
A nested table is an unordered collection of data elements. Nested tables enable you to have any number of elements. There is no maximum number of elements specified in the definition of the table. The order of the elements is not preserved. All the operations, such as SELECT, INSERT, and DELETE that you perform on ordinary tables can be performed on nested tables. Elements of a nested table are stored in a separate storage table containing a column that identifies the parent table row or object to which each element belongs. The elements may be built-in types or user-defined types. You can view a nested table as a single-column table, or if the nested table is an object type, as a multicolumn table, with a column for each attribute of the object type.
Nested tables are used to store an unordered set of elements that do not have a predefined size, such as customer references.
To define a nested table:
From the Projects Navigator, expand the Databases node and then the Oracle node.
Expand the target module where you want to create the nested table.
Expand the User Defined Types node.
Right-click Nested Tables and select New Nested Table.
The Create Nested Table dialog box is displayed.
Enter the name and an optional description for the nested table and click OK.
The Nested Table Editor is displayed. Use the following tabs on the editor to define the nested table.
Use the Name field to enter a name for the nested table. Use the Description field to enter an optional description for the nested table. To rename a nested table, select the name and enter a new name.
Follow the rules in "Naming Conventions for Data Objects" to specify a name and an optional description.
Use the Details tab to specify the value for the following fields:
Data Type: Select the data type of the attribute from the Data Type list.
See Also:
"Supported Data Types" for a list of supported data typesLength: Specify the length of the nested table element. Length is applicable for character data types only.
Precision: Specify the total number of digits enabled for the nested table element. Precision is applicable to numeric data types only.
Scale: Specify the total number of digits to the right of the decimal point. Scale is applicable to numeric data types only.
Seconds Precision: Specify the number of digits in the fractional part of the datetime field. Seconds precision is used for TIMESTAMP,TIMESTAMP WITH TIME ZONE, and TIMESTAMP WITH LOCAL TIME ZONE data types only.
To edit a nested table:
From the Projects Navigator, expand the Databases node and then the Oracle node.
Expand the module that contains the nested table.
Expand the User Defined Types node and then the Nested Tables node.
Right-click the nested table to edit and select Open.
The Nested Table Editor is displayed. Use the Name and Details tabs, as defined in "Defining Nested Tables", to edit the definition of the nested table.
Queues enable asynchronous information sharing using messages. Use queues to implement incremental data warehousing or replication solutions, both within a database or from one database to another.
Before you can share data in the form of messages, you must create a data object that stores and manages multiple messages. This object is the Advanced Queue (AQ). You can propagate messages between different queues by defining queue propagations. The following sections describe how to define and use queues.
Queues provide the following advantages:
Creating applications that communicate with each other in a consistent, reliable, secure, and autonomous manner
Storing messages in database tables, bringing the reliability and recoverability of the database to your messaging infrastructure
Retaining messages in the database automatically for auditing and business intelligence
Queues are stored in queue tables. Each queue table is a database table and contains one or more queues. Creating a queue table creates a database table with approximately 25 columns. These columns store Oracle AQ metadata and the user-defined payload.
You can create queue tables that store any type of messages by using the SYS.ANYDATA data type to define the type of data stored in the queue table.
In the Projects Navigator, expand the Databases node, the Oracle node, and then the module node under which you want to define a queue table.
Expand the Queues node, right-click Queue Tables and select New Queue Table.
The Create Queue Table dialog box is displayed.
Specify the details required to define queue tables and click OK.
For more details, see "Defining the Payload Type of Queue Tables".
The metadata for the queue table is created in the workspace and the queue table is added to the Projects Navigator under the Queues node.
Use the Create Queue Table dialog box or the Edit Queue Table dialog box to provide additional details about the queue table such as the payload type and order in which the messages in the queue should be sorted. The following section describes the details to be provided for a queue table.
The Name field represents the name of the queue table. The name should be unique within the Oracle module containing that queue table. For more details, see "Naming Conventions for Data Objects".
Use the Description field to provide an optional description for the queue table.
Each queue contains a payload that stores the actual data that is to be transferred. The Payload Type represents the type of data that is permitted in the queue table.
You can select one of the following options for the payload type: Object Type, "SYS.ANYDATA", "RAW", "SYS.AQ$_JMS_BYTES_MESSAGE", "SYS.AQ$_JMS_MAP_MESSAGE", "SYS.AQ$_JMS_MESSAGE", "SYS.AQ$_JMS_STREAM_MESSAGE", "SYS.AQ$_JMS_TEXT_MESSAGE", and "XMLTYPE".
Use the Search For field to search for an object. This field is enabled only when you select Object Type as the "Payload Type".
The area below the Search For field displays the object types in your workspace. Object types are listed under the module to which they belong. To search for an object with a specific name, enter the name of the object in the Search For field and click Go.
Enable Transactional Property for Messages
Select Enable Transactional Property for Messages to enable message grouping. This option is enabled for all object-typed queues except SYS.ANYDATA queues.
Message grouping enables messages belonging to one queue to be grouped so that they form a set that can only be consumed by one user at a time. All messages belonging to a group must be created in the same transaction, and all messages created in one transaction belong to the same group.
This feature enables users to segment complex messages into simple messages. It is also useful if the message payload contains complex large objects such as images and video that can be segmented into smaller objects.
Select Secured Queue Table when you want to create a secure queue. This option is enabled for all object-typed queues except SYS.ANYDATA queues.
Secure queues are queues for which Oracle Streams Advanced Queuing (AQ) agents must be associated explicitly with one or more database users who can perform queue operations, such as enqueue and dequeue. The owner of a secure queue can perform all queue operations on the queue, but other users cannot perform queue operations on a secure queue, unless they are configured as secure queue users.
Use the Sort Messages By list to specify the order in which the messages contained in the payload should be sorted. The options you can use to sort messages are:
Enqueue_time: Sorts by the arrival time of the message.
Priority: Sorts by message priority.
Enqueue_time, priority: Sorts by the arrival time of the message and, for messages with the same arrival time, sorts by message priority.
Priority, enqueue_time: Sorts by message priority and, for messages with the same priority, sorts by arrival time of the message.
To edit queue tables, right-click the queue table and select Open. The Edit Queue Table dialog box is displayed. Use this to modify your queue table definition.
You can modify queue tables and change the name, description, or payload type. However, if you modify the payload type of a queue table, then the queue table and any queues based on this queue table are dropped and re-created. Thus, all the existing data in the queue is lost. deployed, it is recommend to not to modify the payload type.
Advanced Queues (AQs) provide database-integrated message queuing functionality. They optimize the functions of Oracle Database so that messages can be stored persistently, propagated between queues on different computers and databases, and transmitted using Oracle Net Services, HTTP, and HTTPS.
Use advanced queues to propagate and manage data either within an Oracle database or between different databases. Every advanced queue is based on a queue table that stores the actual queue data.
See Also:
Oracle Streams Concepts and Administration for more information about advanced queuesTo create an advanced queue definition:
In the Projects Navigator, expand the Databases node, the Oracle node, and then the Oracle module node under which you want to define an advanced queue.
Right-click the Queues node and select New Advanced Queue.
The Create Advanced Queue dialog box is displayed.
Provide details such as the advanced queue name and the queue table on which the advanced queue is based. Click OK.
For more information, see "Specifying the Queue Table on which the AQ is Based".
Use the Create Advanced Queue dialog box to specify details such as the advanced queue name and the queue table on which the AQ is based. You can choose an existing queue table or create a new one. Use the Edit Advanced Queue dialog box to modify the name, description, or the queue table on which the AQ is based.
The Name field represents the name of the advanced queue. The name should be unique within the Oracle module containing that advanced queue. For more details, see "Naming Conventions for Data Objects".
Use the Description field to provide an optional description for the advanced queue.
Use the Select a Queue Table list to select the queue table that stores messages contained in the advanced queue.
Select Create New Queue Table to create a ueue table that contains the advanced queue data. The Create Queue Table dialog box that guides you through the process of defining a queue table is displayed. For more information about defining queue tables, see "Creating Queue Table Definitions".
You can edit advanced queues and modify the properties that you specified while creating the advanced queues. This includes the name, description, and queue table that stores queue data.
To edit an advanced queue, in the Projects Navigator, right-click the advanced queue and select Open. The Edit Advanced Queue dialog box is displayed. Use this to edit the advanced queue.
For more information about the options on this dialog box, see "Creating Advanced Queue Definitions".
After you edit an advanced queue definition, ensure that you synchronize any mappings that use this advanced queue.
Queue propagations enable you to propagate messages between different queues. For example, you have two queues SRC_QUE and TGT_QUE. In SRC_QUE, define a queue propagation with the target queue as TGT_QUE to propagate messages from SRC_QUE to TGT_QUE.
Queue propagations are typically used in replication, when you have two databases located in different location and you want to replicate the source database to the target location.
To create a queue propagation:
In the Projects Navigator, expand the Databases node, the Oracle node, and then the Oracle module node under which you want to define a queue propagation.
Expand the Queues node, right-click the advanced queue under which you want to create a propagation, and select New.
The New Gallery dialog box is displayed.
On the New Gallery dialog box, select Queue Propagations and click OK.
The Create Queue Propagation dialog box is displayed.
Use the Create Propagation dialog box to define the target queue and click OK.
The metadata for the queue propagation is created in the workspace and the queue propagation is added under the advanced queue in the Projects Navigator.
Use the Create Queue Propagation dialog box or the Edit Queue Propagation dialog box to specify the target queue for propagation. The following sections describe the fields contained in this page.
The Name field represents the name of the queue propagation. The name should be unique within the advanced queue under which the queue propagation is defined.
To rename a queue propagation, select the name and enter the new name.
The Description field represents the description of the queue propagation. Providing a description is optional.
Select a Target Queue for Propagation
Use the Select a Target Queue for Propagation section to define the target queue. The area below this section displays a node tree containing the advanced queues defined in the current project. Select the advanced queue that is used as a target. Messages from the AQ under which you define the queue propagation can then be propagated to the AQ defined as the target queue.
Use the Search For field to search for a particular object using the object name. Enter the name of the object in this field and click Go.
You can edit queue propagations and modify the selections you made which defining the queue propagation. The options you can modify include the name, description, and target queue.
To edit a queue propagation, in the Projects Navigator, right-click the queue propagation and select Open. The Edit Queue Propagation dialog box is displayed. For more information about the options on this dialog box, see "Creating Queue Propagations".
Earlier in the design phase, you defined a logical model for your target system using Oracle Warehouse Builder design objects. In the configuration phase, you assign physical deployment properties to the object definitions by configuring parameters such as tablespaces, partitions, and other identification parameters. You also configure run time parameters such as job names, and run time directories.
Set these physical properties using the Configuration tab of the data object. The following sections show you how to assign physical properties to your logical design model:
Each target module provides top-level configuration options for all the objects contained in that module.
To configure an Oracle module:
From the Projects Navigator, expand Databases, expand Oracle, and right-click a target module name, and select Configure.
Oracle Warehouse Builder displays the Configuration tab.
Choose the parameters to configure and click the space to the right of the parameter name to edit its value.
For each parameter, you can either select an option from a list, type a value, or click the Ellipsis button to display another properties dialog box.
Configure the parameters listed in the following sections.
PL/SQL Generation Mode: Defines the target database type. The options you can select are: Default, Oracle 10g, Oracle 11g, Oracle8i , and Oracle9i. Code generation is based on your choice in this field. For example, select Oracle9i to ensure the use of Oracle9i code constructs. If you select Oracle8i, then row-based code is generated.
Each release introduces new functionality, some of which you may use only with the latest version of the Oracle Database. For example, if you select Oracle8i as the PL/SQL Generation Mode, then you cannot access some Oracle Warehouse Builder 9i components such as table functions and external tables.
End of Line: Defines the end of line markers for flat files. This depends on the platform to which you are deploying your warehouse. For UNIX, use \n, and for Windows NT, use \r\n.
ABAP Extension: File name extension for ABAP scripts. The default is abap.
ABAP Run Parameter File: Suffix for the parameter script in an ABAP job. The default is _run.ini.
ABAP Spool Directory: The location where ABAP scripts are buffered during script generation processing.
DDL Directory: Enter a location for the scripts that create database objects in the target schema. The default is ddl\.
DDL Extension: Enter a file name extension for DDL scripts. The default is ddl.
DDL Spool Directory: Enter a buffer location for DDL scripts during the script generation processing. The default is ddl\log.
LIB Directory: Enter a location for the scripts that generate Oracle functions and procedures. The default is lib\.
LIB Extension: Enter a suffix to be appended to a mapping name. The default is .lib.
LIB Spool Directory: Enter a location for the scripts that generate user-defined functions and procedures. The default is lib\log\.
LOADER Directory: Enter a location for the control files. The default is ctl\.
LOADER Extension: Enter a suffix for the loader scripts. The default is .ctl.
LOADER Run Parameter File: Enter a suffix for the parameter initialization file. The default is _run.ini.
PL/SQL Directory: Enter a location for the PL/SQL scripts. The default is pls\.
PL/SQL Run Parameter File: Enter a suffix for the parameter script in a PL/SQL job. The default is _run.ini.
PL/SQL Spool Directory: Enter a buffer location for PL/SQL scripts during the script generation processing. The default is pls\log\.
PL/SQL Extension: Enter a file name extension for PL/SQL scripts. The default is .pls.
SQLPlus Directory: Enter a location for the PL/SQL scripts. The default is sql\.
SQLPlus Extension: Enter a file name extension for PL/SQL scripts. The default is .sql.
SQLPLus Run Parameter File: Enter a suffix for the parameter script in a PL/SQL job. The default is _run.ini.
Staging File Directory: For all ABAP configuration related to SAP tables. The default is abap\.
Tcl Directory: Enter a location for the tcl scripts. The default is tcl\.
See Also:
Oracle Warehouse Builder Sources and Targets Guide for more information about using SAP tables.Application Short Name: This parameter is obsolete and is no longer used.
Deployable: Select this option to indicate that the objects contained in the module can be deployed.
Location: Represents the location with which the module is associated. If the module is a source module, then this value represents the location from which the data is sourced. If the module is a target module, then this value represents the location to which the generated code and object data are deployed.
Main Application Short Name: This parameter is obsolete and is no longer used.
Top Directory: Represents the name of the directory to which the generated code is stored. The default value for this parameter is ..\..\codegen\. You can change this value to any directory in which you want to store generated code.
Archive Directory: Not currently used. The default is archive\.
Input Directory: Not currently used. The default is input\.
Invalid Directory: Directory for SQL*Loader error and rejected records. The default is invalid\.
Log Directory: Log directory for the SQL*Loader. The default is log\.
Receive Directory: Not currently used. The default is receive\.
Default Index Tablespace: Defines the name of each tablespace where indexes are created. The default is null. If you configure an index tablespace at the target module level and not at the object level, then the tablespace value configured at the target module level is used during code generation. If you configure a tablespace for each index at the object level, then the tablespace value configured at the target module level is overwritten.
Default Object Tablespace: Defines the name of each tablespace where objects are created (for example, tables, views, or materialized views). The default is null. If you configure object tablespace at the target module level and not at the individual object level, then the value configured at the target module level is used during code generation. If you configure a tablespace for each individual object, then the tablespace value configured at the target module level is overwritten.
Oracle Warehouse Builder generates DDL scripts for each table defined in a target module.
To configure the physical properties for a table:
In the Projects Navigator, right-click the name of a table and select Configure.
The Configuration tab for the table is displayed.
Set the configuration parameters listed under the following nodes: "Error Table", "Foreign Keys", "Identification", "Parallel", "Performance Parameters", "Partition Parameters", "Storage Space", and "Change Data Capture".
Error Table Name: Indicates the name of the error table that stores the rows that were not loaded into the table during a load operation.
Tablespace: Indicates the name of the tablespace in which the error table is stored.
The Foreign Keys node is displayed if your table contains a foreign key definition. A separate node is displayed, under the Foreign Keys node, for each foreign key in the table. Under this node, parameters are listed under the following categories: Creation Method and Identification.
The Creation Method category contains the following parameters:
Constraint Checking: Indicates whether the checking of this constraint can be deferred until after the transaction is committed. Set this parameter to DEFERABLE to indicate that, in subsequent transactions, you can set the SET CONSTRAINTS clause to defer checking this constraint until after the transaction is committed. Set this parameter to NOT DEFERABLE to indicate that you cannot use the SET CONSTRAINTS clause ti defer checking this constraint until after the transaction is committed. The default is NOT DEFERABLE.
Constraint State: Indicates whether the constraint should be enabled. Select ENABLE to apply the constraint to the table data. Select DISABLE to disable the integrity constraint. The default is ENABLE.
Constraint Validation: The options you can set are NOVALIDATE or VALIDATE. The effect of setting this parameter is different based on whether the constraint is enabled or disabled.
EXCEPTIONS INTO: Indicates the name of the exceptions table. You cannot use this parameters when you set NOVALIDATE as the Constraint Validation.
INITIALLY: The options you can set for this parameter are IMMEDIATE or DEFERRED. The default setting is IMMEDIATE. IMMEDIATE indicates that a deferrable constraint must be checked after each SQL statement. DEFERRED indicates that a deferrable constraint must be checked after subsequent transactions.
NOVALIDATE mode: The options you can set for this parameter are NORELY and RELY, with NORELY being the default setting. Setting this parameter to RELY activates a constraint in NOVALIDATE mode for query rewrite.
ON DELETE: During a delete operation, this parameter indicates how to handle foreign keys that depend on the record being deleted. The options you can set for this parameter are CASCADE or SET NULL. CASCADE deletes dependent foreign key values. NOT NULL sets the dependent foreign key values to null.
Deployable: Select this option to indicate to deploy this table. Scripts are generated only for tables marked deployable.
Error Table Only: Select this option to perform generation or deployment actions only on the error table associated with the table. Use this option to add an error table to an existing table. This setting only controls the actions of the Deployable parameter, but does not override it.
Deselect this option to deploy the error table along with the table.
Parallel Access Mode: Enables parallel processing when the table has been created. The default is PARALLEL.
Parallel Degree: Indicates the degree of parallelism. This is the number of parallel threads used in the parallel operation.
Buffer Cache: Indicates how Oracle Database should store rows in the buffer cache.
Data Segment Compression: Indicates whether data segments should be compressed. Compressing reduces disk use. The default is NOCOMPRESS.
Logging Mode: Indicates whether the DML actions are logged in the redo log file. To improve performance, set this parameter to NOLOGGING. The default is LOGGING.
Row-level Dependency: Indicates whether row-level dependency tracking.
Row Movement: Indicates if Oracle Database can move a table row.
Statistics Collection: Indicates if statistics should be collected for the table. Specify MONITORING if you want modification statistics to be collected on this table.
Partition Tablespace List: Specify a comma-delimited list of tablespaces. For simple partitioned objects, it is used for a HASH BY QUANTITY partition tablespace. For composite partitioned tables, it is used for subpartition template to store the list of tablespaces.
Overflow Tablespace List: Specify a comma-delimited list of tablespaces for overflow data. For simple partitioned objects, it is used for HASH BY QUANTITY partition overflow tablespaces. The number of tablespaces does not have to equal the number of partitions. If the number of partitions is greater than the number of tablespaces, then Oracle Database cycles through the names of the tablespaces.
Storage parameters enable you to define how the table is stored in the database. This category contains parameters such as BUFFER_POOL, FREELIST GROUPS, FREELISTS, INITIAL, MINEXTENTS, MAXEXTENTS, NEXT, and PCTINCREASE.
The Tablespace parameter defines the name of each tablespace where the table is created. The default value is null. If you accept the default value of null, then the table is generated based on the tablespace value set in the configuration parameters of the target module. If you configure the tablespace for individual objects, then the tablespace value configured for the target module is overwritten.
Enable: Indicates if change data capture is enabled for the table. Select True for this parameter to enable change data capture for the table.
Table Position: Indicates the position of the table in the change data capture.
To configure the physical properties for a materialized view:
From the Projects Navigator, right-click a materialized view name and select Configure.
The Configuration tab for the materialized view is displayed.
Follow the configuration guidelines listed for tables. For more information, see "Configuring Tables".
Configure the "Materialized View Parameters" listed in the following section.
Configure the Materialized View Log parameters as described in "Materialized View Log Parameters".
The following are parameters for materialized views:
Base Tables: Specify a comma-delimited list of base tables referenced by the materialized view. Separate each table name with a comma. If a table name is not in uppercase, then enclose the name in double quotation marks.
BUILD: Indicates when the materialized view is populated. The options are Immediate (default), Deferred, and Prebuilt.
Immediate: Populates the materialized view when it is created.
Deferred: Delays the population of the materialized view until the next refresh operation. You can select this option when you are designing a materialized view and the metadata for the base tables is correct but the data is not.
Prebuilt: Indicates that the materialized view is prebuilt.
Default Rollback Segment: The options are DEFAULT, DEFAULT MASTER, DEFAULT LOCAL, and NONE. The default setting is DEFAULT LOCAL. Specify DEFAULT to indicate that Oracle Database should choose which rollback segment to use. Specify DEFAULT MASTER for the remote rollback segment to be used at the remote site. Specify DEFAULT LOCAL for the remote rollback segment to be used for the local refresh group that contains the materialized view. Specify NONE to name both master and local segments.
FOR UPDATE: Select Yes to enable a subquery, primary key, row ID, or object materialized view to be updated. The default setting is No.
Local Rollback Segment: Specify a named remote rollback segment to be used for the local refresh group of the materialized view. The default is null.
Master Rollback Segment: Indicates the name of the remote rollback segment to be used at the remote master site for the materialized view.
NEXT (date): Indicates the interval between automatic refreshes. Specify a datetime value for this parameter.
Query Rewrite: Indicates if the materialized view is eligible for query rewrite. The options are ENABLE and DISABLE. The default is DISABLE.
Enable: Enables query rewrite. For other query rewrite requirements, see "Fast Refresh for Materialized Views".
Disable: Disables query rewrite. You can disable query rewrite when you know that the data in the materialized view is stale or when you want to make changes to the query statement.
REFRESH: Indicates the refresh method. The options are Complete, Fast, Force, and Never. The default setting is Force.
Complete: Oracle Database truncates the materialized view and reruns the query upon refresh.
Fast: Uses materialized views to only apply changes to the base table data. There are many requirements for fast refresh to operate properly. For more information, see "Fast Refresh for Materialized Views".
Force: Oracle Database attempts to refresh using the fast mode. If unable to refresh in fast mode, the Oracle server reruns the query upon refresh.
Never: Prevents the materialized view from being refreshed.
Refresh On: The options are COMMIT and DEMAND. Specify COMMIT to indicate that a fast refresh is to occur whenever the database commits a transaction that operates on a master table of the materialized view. Specify DEMAND to indicate that the materialized view should be refreshed on demand. You can do this by using one of the refresh procedures of the DBMS_MVIEW package. The default setting is DEMAND.
Start With: Indicates the first automatic refresh time. Specify a datetime value for this parameter.
Using Constraints: The options that you can select for this parameter are TRUSTED or ENFORCED. Select TRUSTED to enable Oracle Database to use dimension and constraint information that has been declared trustworthy by the DBA but has not been validated by Oracle Database. ENFORCED is the default setting.
WITH: Select PRIMARY_KEY to create a primary key materialized view. Select ROWID to create a ROWID materialized view. The default setting is PRIMARY_KEY.
Buffer Cache: Indicates how the blocks retrieved for this table are placed in the buffer cache. The options you can select are CACHE or NOCACHE. When you select CACHE, the blocks are placed at the most recently used end of the least recently used (LRU) list in the buffer cache when a full table scan is performed. Setting the Buffer Cache parameter to CACHE is useful for frequently accessed tables, such as small lookup tables. When you select NOCACHE, the blocks are placed at the least recently used end of the LRU list in the buffer cache.
Data Segment Compression: Indicates if segments should be compressed on disk to reduce space usage. The options you can set for this parameter are COMPRESS, COMPRESS ALL, or NOCOMPRESS. The default is NOCOMPRESS. Set this parameter to COMPRESS to compress data only during a direct path INSERT, when it is productive to do so. Set this parameter to COMPRESS ALL compresses data during all DML operations on the table.
Logging Mode: Indicates whether the DML actions are logged in the redo log file. To improve performance, set this parameter to NOLOGGING. The default is LOGGING.
Error Table Name: Indicates the name of the error table that stores the rows that were not loaded into the table during a load operation.
Tablespace: Indicates the name of the tablespace in which the error table is stored.
Parallel Access Mode: Enables parallel processing when the table has been created. The default is PARALLEL.
Parallel Degree: Indicates the degree of parallelism. This is the number of parallel threads used in the parallel operation.
Deployable: Select TRUE to indicate to deploy this materialized view. Oracle Warehouse Builder generates scripts only for materialized views marked deployable.
Error Table Only: Select this option to perform generation or deployment actions only on the error table associated with the materialized view. Use this option to add an error table to an existing materialized view. This setting controls the actions of the Deployable parameter, but does not override it.
Deselect this option to deploy the error table along with the materialized view.
You can configure the following materialized view log parameters.
Record Primary Key: Select PRIMARY KEY to indicate that the primary key of all rows changed should be recorded in the materialized view log.
Record ROWID: Select ROWID to indicate that the row ID of all rows changed should be recorded in the materialized view log.
Record SEQUENCE: Select SEQUENCE to indicate that a sequence value providing additional ordering information should be recorded in the materialized view log.
Sequence numbers are necessary to support fast refresh after some update scenarios.
COLUMNS: Specify the columns whose values you want to be recorded in the materialized view log for all rows that are changed. Typically these columns are filter columns and join columns.
Generate Materialized View Log: Select YES to generate DDL for materialized view log. The default is YES.
New Values: Specify INCLUDING to save both new and old values in the log. Specify EXCLUDING to disable the recording of new values in the log. EXCLUDING is the default.
You can configure a materialized view to refresh incrementally. When you update the base tables for a materialized view, the database stores updated record pointers in the materialized view log. Changes in the log tables are used to refresh the associated materialized views.
To ensure incremental refresh of materialized views, verify the following conditions:
The Refresh parameter must be set to Fast and the Base Tables parameter must list all base tables.
Each base table must have a PK constraint defined. Oracle Warehouse Builder generates a create statement based on the PK constraint and utilizes that log to refresh the dependent materialized views.
The materialized view must not contain references to nonrepeating expressions such as SYSDATE, ROWNUM, and nonrepeatable PL/SQL functions.
The materialized view must not contain references to RAW and LONG RAW data types.
There are additional restrictions for materialized views with statements for joins, aggregations, and unions. For information about additional restrictions, see Oracle Database Data Warehousing Guide.
Oracle Warehouse Builder generates a script for each view defined in a target module. You can configure the parameters listed in the following categories.
Deployable: Set to TRUE to deploy this view.
Error Table Only: Select this option to perform generation or deployment actions only on the error table associated with the view. Use this option to add an error table to an existing view. This setting only controls the actions of the Deployable parameter, but does not override it. Deselect this option to deploy the error table along with the view.
Error Table Name: Indicates the name of the error table that stores the rows that were not loaded into the view during a load operation.
Tablespace: Indicates the name of the tablespace in which the error table is stored.
A script is generated for each sequence object. A sequence object has a Start With parameter and an Increment By parameter. Both parameters are numeric.
To configure the physical properties for a sequence:
Right-click the name of a sequence and select Configure.
The Configuration tab for the sequence is displayed.
Configure the following Sequence parameters:
Increment By: The number by which you want to increment the sequence.
Start With: The number at which you want the sequence to start.
Configure the following Identification parameter:
Deployable: Select this option to indicate to deploy this sequence. Oracle Warehouse Builder only generates scripts for sequences marked deployable.
Use the following steps to configure advanced queues.
From the Projects Navigator, expand the Databases node and then the Oracle node.
Expand the Oracle module containing the advanced queue, then the Queues node, and right-click the advanced queue name and select Configure.
Oracle Warehouse Builder displays the Configuration tab that contains configuration parameters for the advanced queue.
Choose the parameters you want to configure and click the space to the right of the parameter name to edit its value.
For each parameter, you can either select an option from a list, type a value, or click the Ellipsis button to display another properties dialog box.
Following are the parameters that you can configure.
Dequeue Enabled Set this parameter to true to enable dequeuing for the advanced queue.
Enqueue Enabled Set this parameter to true to enable enqueuing for the advanced queue.
Max Retries Represents the number of times a dequeue can be attempted on a message. The maximum value of max_retries is 2**31 -1.
Retention Time Represents the number of seconds for which a message is retained in the queue table after being dequeued from the queue.
Retry Delay Represents the delay time, in seconds, before this message is scheduled for processing again after an application rollback. The default value of this parameter is 0, which means the message can be retried as soon as possible. This parameter has no effect if Max Retires parameter is set to 0.
Use the following steps to configure queue tables.
From the Projects Navigator, expand the Databases node and then the Oracle node that contains the queue table.
Expand the Queues node and then the Queue Tables node.
Right-click the name of the queue table to be configured and select Configure.
Oracle Warehouse Builder displays the Configuration tab that contains configuration parameters for the queue table.
Choose the parameters you want to configure and click the space to the right of the parameter name to edit its value.
For each parameter, you can either select an option from a list, type a value, or click the Ellipsis button to display another properties dialog box.
The Generation Options node contains the Generate Queue Table parameter. Set this parameter to True to generate code to create the queue table that persists the message of this advanced queue. If the queue table exists in the database, then you need not create it and you may set Generate Queue Table to False.
Use the following steps to configure queue propagations.
From the Projects Navigator, expand the Databases node and then the Oracle node that contains the queue table.
Expand the Queues node and then the advanced queue that contains the queue propagation.
Right-click the name of the queue propagation to be configured and select Configure.
Oracle Warehouse Builder displays the Configuration tab that contains configuration parameters for the queue propagation.
Choose the parameters you want to configure and click the space to the right of the parameter name to edit its value.
For each parameter, you can either select an option from a list, type a value, or click the Ellipsis button to display another properties dialog box.
The configuration parameters are described in the following sections.
Rule Condition: Represents a rule condition to check whether the message can be propagated to the subscriber. This parameter is applicable only for non-streams queues.
Transformation: Represents the transformation that is applied before propagation to the target queue. This parameter is applicable only for non-streams queues.
Generate Database Link: Set this parameter to True to generate a script that creates the database link used for propagation.
Generate Queue Propagation: Set this parameter to True to generate code that creates the queue propagation.
Generate Ruleset and Rule for Replication: Set this parameter to true to generate the code for RULE and RULESET for replication purposes. This parameter is applicable only for streams queues.
Generate Schedule Propagation: Set this parameter to true to generate code for scheduling the queue propagation. This parameter is applicable only for non-streams queues.
Replication Options (Only for Streams Queues)
Not Permitted Tag Values: List of comma-delimited Tag values (in Hexadecimal numbers) that are not enabled for propagation.
Permitted Tag Values: List of comma-delimited Tag values (in Hexadecimal numbers) that are enabled for propagation.
Duration: Represents the duration of propagation to be performed. The default value is null. This parameter is applicable only for non-streams queue.
Latency: Represents the latency for the queue propagation. By default the value is 60. This parameter is applicable only for non-streams queue.
Next Time: Represents the next time when the propagation is performed. The default value is null. This parameter is applicable only for non-streams queue.
Start Time: Represents the start time for the propagation. The default value is SYSDATE. This parameter is applicable only for non-streams queue.
When you create a Microsoft SQL Server module or an IBM DB2 module, you can define data objects such as tables, views, and sequences in this module. Use the editors to define tables and views.
To define a table, view, or sequence in Microsoft SQL Server or IBM DB2 UDB module:
Expand the project node under which you want to create data objects and then expand the Databases node.
For SQL Server, expand the SQL Server module node and then the module in which the data objects are to be created.
For IBM DB2 UDB, expand the DB2 module node and then the module in which the data objects are to be created.
Right-click the node representing the type of object to create and select New <type of object>. The editor for the object is displayed.
For example, to create a table, right-click the Tables node and select New Table.
Based on the type of object being created, follow the instructions mentioned in one of the following sections:
Differences in the Object Editors for Heterogeneous Databases
The following differences exist when you define tables, views, and sequences in the SQL Server or DB2 module:
The Table Editor and View Editor do not contain the Indexes and Partitions tabs.
The types of constraints supported for SQL Server and DB2 tables are Primary Key, Foreign Key, Check Constraints, and Unique Keys.
On the Columns tab, the field Seconds Precision is not available.
On the Columns tab, the Datatypes list contains the data types that you can use. If you use native access, then the Datatypes list contains the data types native to that platform. If you use Gateways to access the heterogeneous database, then the Datatypes list contains Oracle data types.
You can use the following attributes in DB2 sequences: START_WITH, INCREMENT_BY, MINVALUE, MAXVALUE, CYCLE, and CACHE.
When you import data objects from DB2, the case used in object names is preserved. However, for all objects created using Oracle Warehouse Builder, the names are automatically converted to uppercase.
Following are the rules for naming objects in a DB2 module:
Object names and column names must be unique.
The maximum length for the object name is 128 characters.
The maximum length for each column name is 30 characters.
The following characters are illegal in names: `, *, +, |, [, ], :, ;, ", ', &, <, >, ?, /, and Space
Names cannot begin with a space, a digit, or with any of the following characters: _, `, &, *, +, |, [, ], :, ;, ", ', <, >, ?, and /.
Note:
Enclosed illegal characters are only enabled in names when you import objects. You cannot use illegal characters within Oracle Warehouse Builder.When you import data objects from SQL Server, the case used in object names is preserved. However, for all objects created using Oracle Warehouse Builder, the names are automatically converted to uppercase.
Following are the rules for naming objects in Microsoft SQL Server:
Object names and column names must be unique.
The maximum length for the object name is 128 characters.
The following characters are illegal in names: ~, `, !, %, ^, &, ;, *, (, ), {, }, [, ], |, \, :, ", /, ?, >, and <.
Names cannot contain spaces, periods, or mathematical symbols.
Names cannot begin with a space or with any of the following characters: ~, `, !, %, ^, &, *,( ,) {, }, [, ], |, \, :, ;, ", ', /, ?, <, >, and $.
Column names cannot begin with mathematical symbols or periods.
Note:
Enclosed illegal characters are only enabled in names when you import objects. You cannot use illegal characters within Oracle Warehouse Builder.
|
Copyright © 2000, 2011, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|