| Oracle® Warehouse Builder Data Modeling, ETL, and Data Quality Guide 11g Release 2 (11.2) E10935-05 |
|
|
PDF · Mobi · ePub |
| Oracle® Warehouse Builder Data Modeling, ETL, and Data Quality Guide 11g Release 2 (11.2) E10935-05 |
|
|
PDF · Mobi · ePub |
Oracle Warehouse Builder enables you use mappings to extract data from disparate sources such as flat files and SAP. Code Template (CT) mappings help in open connectivity and enable customizing of how data is moved.
This chapter describes the steps used to create SAP and CT mappings. It also includes examples of performing ETL on SAP systems and other heterogeneous databases.
This chapter contains the following topics:
"Creating SQL*Loader Mappings to Extract Data from Flat Files"
"Setting Options for Code Templates in Code Template Mappings"
"Using Code Template Mappings to Perform Change Data Capture (CDC)"
"Moving Data from Heterogeneous Databases to Oracle Database"
Use the Flat File operator in a mapping to extract data from and load data into flat files. You can use Flat File operators as either sources or targets, but not a combination of both.
Define mappings to extract data from flat files as described in "Extracting Data from Flat Files".
Define mappings to load data into flat files as described in "Loading Data into a Flat File".
See Also:
"Best Practices for Designing SQL*Loader Mappings" for more information about best practices to follow while using SQL*Loader mappings.After you design a mapping and generate its code, you can create a process flow or proceed directly with deployment followed by execution.
Use process flows to interrelate mappings. For example, you can design a process flow such that the completion of one mapping triggers an e-mail notification and starts another mapping. For more information, see Chapter 8, "Designing Process Flows".
Deploy the mapping, and any associated process flows you created, and then run the mapping as described in Chapter 12, "Deploying to Target Schemas and Executing ETL Logic".
To extract data from a flat file, use a Flat File operator as a source in a mapping.
Alternatively, you can define an external table based on the flat file definition and use an External Table operator as a source. If you are loading large volumes of data, then loading from a flat file enables you to use the DIRECT PATH SQL*Loader option, which results in better performance. If you are not loading large volumes of data, then you can benefit from many of the relational transformations available when using external tables.
See Also:
Oracle Warehouse Builder Sources and Targets Guide for a comparison of external tables and flat files.As a source, the Flat File operator acts as a row set generator that reads from a flat file using the SQL*Loader utility. The targets in a flat file mapping can be relational objects such as tables. An External Table operator cannot be a target, because external tables are read-only.
When you design a mapping with a Flat File source operator, you can use the following operators:
Note:
If you use the Sequence, Expression, or Transformation operators, you cannot use the SQL*Loader Direct Load setting as a configuration parameter.When you use a flat file as a source, ensure that a connector is created from the flat file source to the relational target. It the connector is not created, the mapping cannot be deployed successfully.
Defining a Mapping that Extracts Data from Flat Files
Import the flat file metadata into Oracle Warehouse Builder workspace.
See Also:
Oracle Warehouse Builder Sources and Targets Guide for more information about importing flat file metadata.In the Projects Navigator, create a mapping as described in "Steps to Define a Mapping".
From the Projects Navigator, drag and drop the flat file from which data is to be extracted onto the Mapping Editor canvas.
On the Mapping Editor canvas, add the operators that represent the target objects into which data extracted from the flat file is to be loaded. Also add the transformation operators needed to transform the source data.
See Also:
"Adding Operators to Mappings" for information about adding operators.On the Mapping Editor canvas, create the data flows between the source, transformation, and target operators.
Validate the mapping by selecting Validate from the File menu. Rectify validation errors, if any.
To load data into a flat file, use a Flat File operator as a target in a mapping.
A mapping with a flat file target generates a PL/SQL package that loads data into a flat file instead of loading data into rows in a table.
Note:
A mapping can contain a maximum of 50 Flat File target operators.You can use an existing flat file with either a single record type or multiple record types. If you use a multiple-record-type flat file as a target, then you can only map to one of the record types. To load all of the record types in the flat file from the same source, then you can drop the same flat file into the mapping as a target again and map to a different record type. For an example of this usage, see "Using Direct Path Loading to Ensure Referential Integrity in SQL*Loader Mappings". Alternatively, create a separate mapping for each record type to load.
Use one of the following methods to create a Flat File target operator:
Import an existing flat file definition into the repository and use this flat file as a target in a mapping.
Define a flat file using the Create Flat File Wizard and use this as a target in the mapping.
Create a new flat file as described in "Creating a New Flat File Target".
Defining a Mapping That Loads Data into a Flat File
Use the following steps to define a mapping that loads data into a flat file.
In your target module, define the flat file into which you want to load data using one of the methods described in "Creating Flat File Targets".
In the Projects Navigator, create a mapping as described in "Steps to Define a Mapping".
From the Projects Navigator, drag and drop the flat file into which data is to be loaded onto the Mapping Editor canvas.
On the Mapping Editor canvas, add operators representing the source objects from which data is to be loaded into the flat file. Also add the transformation operators used to transform the source data.
See Also:
"Adding Operators to Mappings" for information about adding operators.On the Mapping Editor canvas, create the data flows between the source, transformation, and target operators.
Validate the mapping by selecting Validate from the File menu. Rectify validation errors, is any.
If you have not done so, create a flat file module.
A flat file module is necessary to enable you to create the physical flat file later in these instructions.
Define a mapping as described in "Defining Mappings".
Drag and drop a Flat File operator onto the canvas.
On the Add Flat File Operator dialog box, select Create Unbound Operator with No Attributes and assign a name to the new target operator.
Edit the new operator as described in "Editing Operators".
Thus far, you have defined an operator that represents a flat file but have not created the actual flat file target.
To create the flat file in the database, right-click the operator and select Create and Bind.
The dialog box prompts you to select a flat file module and enables you to assign a unique name to the flat file. When you click OK, Oracle Warehouse Builder displays the new target in the Files node, under the module that you specified.
Continue to define your mapping as described in "Steps to Perform Extraction, Transformation, and Loading (ETL) Using Mappings".
After importing metadata from SAP tables, you must define the extraction mapping to retrieve data from the SAP system.
Use the Mapping Editor to create a mapping containing SAP tables. Creating a mapping with SAP tables is similar to creating mappings with other database objects. However, there are restrictions on the operators that can be used in the mapping. You can only use Table, Filter, Joiner, and Mapping Input Parameter mapping operators in a mapping containing SAP tables.
A typical SAP extraction mapping consists of one or more SAP source tables (transparent, cluster, or pooled), one or more Filter or Joiner operators, and a non-SAP target table (typically an Oracle Database table) to store the retrieved data.
Note:
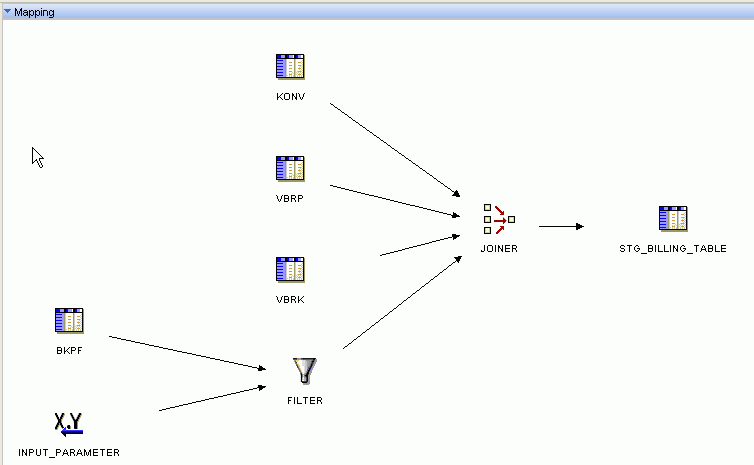
You cannot have both SAP and non-SAP (Oracle Database) source tables in a mapping. However, you can use an Oracle Database table as a staging table.Figure 7-1 displays a mapping that extracts data from an SAP source.
In this example, the Input Parameter holds a Date value, and the data from table BKPF is filtered based on this date. The Joiner operator enables you to join data from multiple tables, and the combined data set is stored in a staging table.
This section contains the following topics:
To add an SAP table to a mapping:
On the Mapping Editor, drag and drop the required SAP table onto the Mapping Editor canvas.
The editor places a Table operator on the mapping canvas to represent the SAP table.
Use the Property Inspector to set the SQL*Loader properties for the tables in the mapping.
To set the loading type for an SAP source table:
On the Mapping Editor, select the SAP source table. The Property Inspector displays the properties of the SAP table.
Select a loading type from the Loading Type list. With ABAP code as the language for the mapping, the SQL*Loader code is generated as indicated in Table 7-1.
Perform the following steps to configure a mapping containing SAP tables:
Use the Configuration tab to define the code generation language as described in "Setting the Language Parameter".
Set ABAP specific parameters, and the directory and initialization file settings in the Configuration tab as described in "Setting the Runtime Parameters".
Setting the Language Parameter
The Language parameter enables you to choose the type of code you want to generate for a mapping. For mappings containing SAP source tables, Oracle Warehouse Builder automatically sets the language parameter to ABAP. Verify that this parameter has been set to ABAP.
Setting the Runtime Parameters
With the Language set to ABAP, expand the Runtime Parameters node in the Configuration tab to display settings specific to ABAP code generation.
Some of these settings come with preset properties that optimize code generation. Oracle recommends that you retain these settings, as altering them may slow the code generation process.
The following Runtime parameters are available for SAP mappings:
Background Job: Select this option to run the ABAP report as a background job in the SAP system. Enable this option for the longer running jobs. Foreground batch jobs that run for a long duration are considered hanging in SAP after a certain time. Therefore, it is ideal to run a background job for such extracts.
File Delimiter for Staging File: Specifies the column separator in a SQL data file.
Data File Name: Specifies the name of the data file that is generated when the ABAP code for the mapping is run in the SAP system.
SQL Join Collapsing: Specifies the following hint, if possible, to generate ABAP code.
SELECT < > INTO < > FROM (T1 as T1 inner join T2 as T2) ON <condition >
The default setting is TRUE.
Primary Foreign Key for Join: Specifies the primary key to be used for a join.
ABAP Report Name: Specifies the name of the ABAP code file generated by the mapping. This is required only when you run a custom function module to run the ABAP code.
SAP System Version: Specifies the SAP system version number to which you want to deploy the ABAP code. For MySAP ERP and all other versions, select SAP R/3 4.7. Different ABAP code is required for versions before 4.7.
Staging File Directory: Specifies the location of the directory in the SAP system where the data file generated by ABAP code resides.
SAP Location: Specifies the location of the SAP instance from where the data can be extracted.
Use Select Single: Indicates whether Select Single is generated, if possible.
Nested Loop: Specifies a hint to generate nested loop code for a join, if possible.
You must set the Join Rank parameter only if the mapping contains the Joiner operator, and you want to explicitly specify the driving table. Unlike SQL, ABAP code generation is rule-based. Therefore, you must design the mapping so that the tables are loaded in the right order. Or you can explicitly specify the order in which the tables must be joined. From the Configuration tab, expand Table Operators, and then for each table, specify the Join Rank. The driving table must have the Join Rank value set to 1, with increasing values for the subsequent tables.
You can also let Oracle Warehouse Builder decide the driving table and the order of joining the other tables. In such cases, do not enter values for Join Rank.
After designing the extraction mapping, you must validate, generate, and deploy the mapping, as you do with all mappings in Oracle Warehouse Builder.
To generate the script for the SAP mapping:
Right-click the SAP mapping and select Generate.
The generation results are displayed in the Log window, under the Scripts node.
Expand the Scripts node, select the script name, and click View Script on the Log window toolbar.
The generated code is displayed in the Code Viewer.
You can edit, print, or save the file using the code editor. Close the Code Viewer to return to the Design Center.
To save the script, right-click the script and click Save Script As on the Log window toolbar.
After you generate the SAP mapping, you must deploy the mapping to create the logical objects in the target location. To deploy an SAP mapping, right-click the mapping and select Deploy. You can also deploy the mapping from the Control Center Manager.
For detailed information about deployment, see Chapter 12, "Deploying to Target Schemas and Executing ETL Logic".
When an SAP mapping is deployed, an ABAP mapping is created and stored in the Oracle Warehouse Builder run time schema. Oracle Warehouse Builder also saves the ABAP file under OWB_HOME\owb\deployed_files directory, where OWB_HOME is the location of the Oracle Database home directory of your Oracle Warehouse Builder installation. If you are using Oracle Warehouse Builder installation that comes with Oracle Database, then this equals the database home.
Depending on whether data retrieval from the SAP system is fully automated, semiautomated, or manual, you must perform the subsequent tasks. This section consists of the following topics:
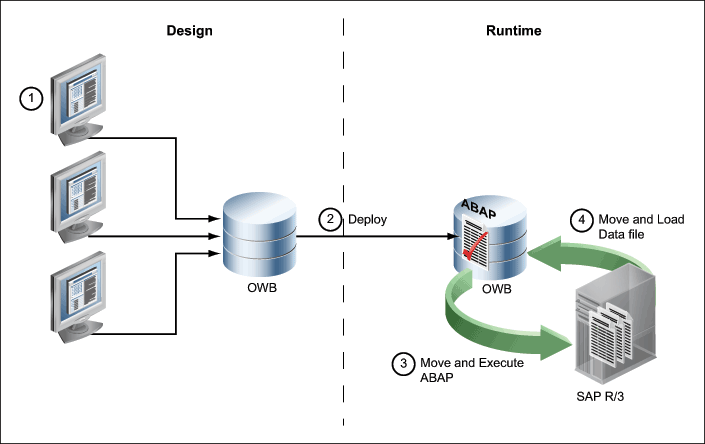
In a completely automated system, as an Oracle Warehouse Builder user you have access to the predefined function module in the SAP system. It enables you to run any ABAP code and retrieve data directly from the SAP system without being dependent on the SAP administrator.
Figure 7-2. displays a diagrammatic representation of the automated data retrieval mechanism.
Because there is no dependence, you can automate the process of sending the ABAP code to the SAP system and retrieving the data file from the SAP system. Oracle Warehouse Builder uses FTP to transfer the data file to Oracle Warehouse Builder system, and load the target file with the retrieved data using SQL*Loader.
An automated system works as follows:
You design the extraction mapping and generate the ABAP code for this mapping.
Before deploying the mapping, ensure that you have set the following configuration parameters for the mapping:
ABAP Report Name: The file that stores the ABAP code generated for the mapping.
SAP Location: The location on the SAP system from where data is retrieved.
Data File Name: Name of the data file to store the data generated by the execution of ABAP code.
Also ensure that you have provided the following additional connection details for the SAP location:
Execution Function Module: Provide the name of the predefined SAP function module. Upon execution, this function module takes the ABAP report name as the parameter, and run the ABAP code.
FTP Directory: The directory on Oracle Warehouse Builder system. The data file generated upon the execution of the function module is sent using FTP to this directory.
Also provide a user name that has write permissions on the FTP directory.
You then start the mapping. The following which the following tasks are automatically performed:
Oracle Warehouse Builder deploys the ABAP and uses RFC_ABAP_INSTALL_AND_RUN to both load the ABAP and run it in SAP.
The ABAP code is sent to the SAP system using a Remote Function Call (RFC).
In the SAP system, the code retrieves data from the source tables and creates a data file.
This data file is stored in the location specified by Runtime parameter Staging File Directory.
Oracle Warehouse Builder uses FTP to transfer this data file back to Oracle Warehouse Builder system.
The file is stored in the location specified in the FTP Directory field.
Using SQL*Loader, Oracle Warehouse Builder loads the target table in the mapping with the data from the data file.
The advantage of this system is that you can create a fully automated end-to-end solution to retrieve SAP data. As a user, you just create the extraction mapping and run it from Oracle Warehouse Builder, which then creates the ABAP code, sends it to the SAP system, retrieves the resultant data file, and loads the target table with the retrieved data.
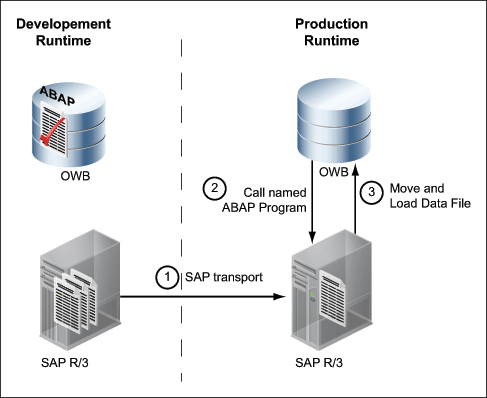
In a semiautomated system, as an Oracle Warehouse Builder user, you do not have access to the predefined function module, and therefore cannot use this function module to run ABAP code. You create an extraction mapping, deploy it, and then send the ABAP code to the SAP administrator who verifies the code before enabling you to run it in the SAP system.
Figure 7-3 displays a diagrammatic representation of a semi automated system.
A semiautomated system works as follows:
You design the extraction mapping and generate the ABAP code for this mapping.
You then transport the ABAP code to the test system to test the code.
You then send the ABAP code to the SAP administrator, who loads it to the SAP repository.
The SAP administrator creates a new ABAP report name.
You can then call this ABAP report name to run the ABAP code in the production environment.
Before you run the mapping in the SAP system, ensure that you have set the following configuration parameters for the mapping:
ABAP Report Name: The SAP administrator provides the report name after verifying the ABAP code. You run this ABAP file.
SAP Location: The location on the SAP system from where data is retrieved.
Data File Name: Name of the data file to store the data generated during execution of ABAP code.
Also ensure that you have provided the following additional connection details for the SAP location:
Execution Function Module: Provide the name of the custom function module created by the SAP administrator. On execution, this function module takes the ABAP report name as the parameter, and run the ABAP code. You must obtain the function module name from the SAP administrator.
FTP Directory: A directory on Oracle Warehouse Builder system. The data file generated by the execution of the ABAP code is sent using FTP to this directory.
Also provide a user name that has Write permissions on the FTP directory.
In the production environment, when you run the mapping, Oracle Warehouse Builder generates the ABAP code and sends it to the SAP system using a Remote Function Call (RFC).
In the SAP system, the ABAP code is run using the customized function module and a data file is generated.
This data file is stored in the location specified by the Runtime parameter Staging File Directory.
Oracle Warehouse Builder uses FTP to transfer this data file back to Oracle Warehouse Builder system.
The file is stored in the location specified in the FTP Directory field.
Oracle Warehouse Builder uses SQL*Loader to load the target table with data from the data file.
In a manual system, your role as an Oracle Warehouse Builder user is restricted to generating the ABAP code for the mapping, and sending the ABAP code to the SAP administrator. The tasks involved in this system are:
You create an extraction mapping, and generate the ABAP code for the mapping.
While designing the mapping, ensure that you specify the Data File Name to store the data file.
You send the ABAP code to the SAP administrator.
The SAP administrator runs the ABAP code in the SAP system.
On execution of the code, a data file is generated.
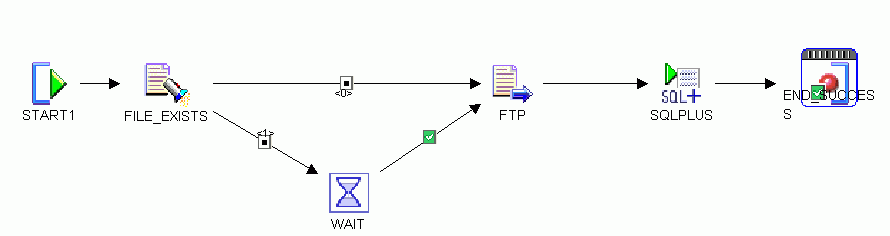
On Oracle Warehouse Builder end, you can create a Process Flow to retrieve the data file. The process flow must contain the following activities.
A File Exists activity to check for the presence of the data file.
If the file exists, then an FTP activity transfers the file to Oracle Warehouse Builder system.
If the file does not exist, then it must wait till the file is made available, and then perform an FTP.
Using SQL*Loader, the target table is loaded with data from the data file.
Figure 7-4 displays the process flow that retrieves the data file.
Figure 7-4 Process Flow to Retrieve SAP Data
In certain environments, the SAP administrator may not enable any other user to access the SAP system. In such cases, implementing the manual system may be the only viable option.
Once you create or import a code template and deploy it, the template to perform a certain task on a certain platform is available in the workspace. To use this template to load or transform your data, you must create a mapping that uses this code template.
Some of the tasks that you can perform using code templates are:
Integrate with heterogeneous databases such as DB2 or SQL Server by extracting data from these databases
Leverage functionality beyond that of the current Code Template library. For example, you can construct new code templates to use Oracle Database functionality such as Data Pump to move data between Oracle systems at high speed.
You can also use code templates in situations where the code generated for PL/SQL mappings does not meet the requirements of your application.
What are Code Template (CT) Mappings?
Mappings that contain an association with code templates are called Code Template (CT) mappings. Typically, they are used to extract or load data (both with and without transformations) from non-Oracle databases such as IBM DB2 and Microsoft SQL Server. You can also use Oracle Gateways to extract from and write to non-Oracle systems.
To extract data from an Oracle Database and transform and load it into another Oracle Database, you can either use Code Template mappings or create mappings under the Mappings node of the Oracle target module.
When Can I Use Code Template (CT) Mappings?
Use Code Template mappings to extract data from, transform, or load data into Oracle and non-Oracle databases using code templates.
When moving data between Oracle databases, the main reason to use CT mappings is moving data using technologies other than database links. You can use Code templates to implement bulk data movement based on functionality such as Data Pump.
Where Are Code Template Mappings Defined?
To create a Code Template mapping, use the Template Mappings node under a project in the Projects Navigator. This node is used to include non-Oracle mappings (not PL/SQL, SQL*Loader, or ABAP).
When you create a CT mapping, the Mapping Editor contains two tabs: "Logical View" and "Execution View". Use the Logical View to define the mapping by adding mapping operators and creating data flows between operators. Use the Execution View to define execution units that specify how the mapping should be run. For more information about execution units, see "Defining Execution Units".
What Operators Can Be Used in Code Template Mappings?
You can use any mapping operator, except the ones listed in "Mapping Operators Only Supported in Oracle Target CT Execution Units", in CT mappings.
You can also use pluggable mappings in CT mappings. However, ensure that the pluggable mappings do not contain any of the operators listed in "Mapping Operators Only Supported in Oracle Target CT Execution Units".
What are the Types of Code Templates?
Code templates in Oracle Warehouse Builder are classified into the following categories:
Load Code Template (Load CT)
Integration Code Template (Integration CT)
Control Code Template (Control CT)
Change Data Capture Code Template (CDC CT)
Oracle Target Code Template (Oracle Target CT)
Function Code Template (Function CT)
For more details about the types of code templates, see Chapter 29, "Oracle Warehouse Builder Code Template Tools and Substitution Methods Reference".
Oracle Warehouse Builder includes some prebuilt code templates that you can use in CT mappings to perform data transformations. These code templates, defined to perform certain ETL tasks on the specified source or target, are available under the BUILT_IN_CT node under the Public Code Templates node of the Globals Navigator.
Table 7-2 provides a brief description of the code templates supplied by Oracle Warehouse Builder and details any restrictions in their usage. Use specific Load CTs for your target staging area whenever possible as they are more optimized for performance. For example, if you are loading to an Oracle database, use LCT_FILE_TO_ORACLE_SQLLDR or LCT_FILE_TO_ORACLE_EXTER_TABLE instead.
For more details about these code templates, see the Oracle Data Integrator (ODI) documentation set. In ODI, code templates are called knowledge modules.
Table 7-2 Prebuilt Code Templates Supplied by Oracle Warehouse Builder
| Code Template Name | Code Template Type | Description |
|---|---|---|
|
LCT_FILE_TO_ORACLE_EXTER_TABLE |
Load CT |
Loads data from a file to an Oracle Database staging area using the EXTERNAL TABLE SQL command. This CT is more efficient than the LCT_FILE_TO_SQL when dealing with large volumes of data. However, the loaded file must be accessible from the Oracle Database computer. |
|
LCT_FILE_TO_ORACLE_SQLLDR |
Load CT |
Loads data from a file to an Oracle Database staging area using the native SQL*LOADER command line utility. Because it uses SQL*LOADER, this CT is more efficient than LCT_FILE_TO_SQL when dealing with large volumes of data. |
|
LCT_FILE_TO_SQL |
Load CT |
Loads data from an ASCII or EBCDIC file to any SQL-compliant database used as a staging area.Consider using this Load CT if one of your source data stores is an ASCII or EBCDIC file. |
|
LCT_ORACLE_TO_ORACLE_DBLINK |
Load CT |
Loads data from an Oracle database to an Oracle staging area database using the native database links feature. |
|
LCT_SQL_TO_ORACLE |
Load CT |
Loads data from any Generic SQL source database to an Oracle staging area. This Load CT is similar to the standard LCT_SQL_TO_SQL, except that you can specify some additional specific Oracle Database parameters. |
|
LCT_SQL_TO_SQL |
Load CT |
Loads data from a SQL-compliant database to a SQL-compliant staging area. |
|
LCT_SQL_TO_SQL_ROW_BY_ROW |
Load CT |
Loads data from a SQL-compliant database to a SQL-compliant staging area. This CT uses Jython scripting to read selected data from the source database and write the result into the staging temporary table created dynamically. |
|
ICT_ORACLE_INCR_UPD |
Integration CT |
Loads your Oracle target table, in incremental update mode, to insert missing records and to update existing ones. Inserts and updates are done in bulk set-based processing to maximize performance. You can also perform data integrity checks by invoking the Control CT. Note: When you use this Integration CT, the following restrictions apply:
|
|
ICT_ORACLE_INCR_UPD_MERGE |
Integration CT |
Loads your Oracle target table, in incremental update mode, to insert missing records and to update existing ones. Inserts and updates are performed by the bulk set-based Note: When you use this Integration CT, the following restrictions apply:
|
|
ICT_ORACLE_INCR_UPD_PL_SQL |
Integration CT |
Loads your Oracle target table to insert missing records and to update existing ones. Use this CT if your records contain long or binary long object (BLOB) data types. Avoid using this CT to load large volumes of data because inserts and updates are performed in row-by-row PL/SQL processing. Note: When you use this Integration CT, the following restrictions apply:
|
|
ICT_ORACLE_SCD |
Integration CT |
Loads a Type 2 Slowly Changing Dimension. This CT relies on the Slowly Changing Dimension metadata set on the target table to determine which records should be inserted as new versions or updated as existing versions. |
|
ICT_SQL_CONTROL_APPEND |
Integration CT |
Loads your SQL-compliant target table in replace/append mode, with or without data integrity check. When flow data must be checked using a Control CT, this CT creates a temporary staging table before invoking the Control CT. |
|
ICT_SQL_INCR_UPD |
Integration CT |
Loads your SQL-compliant target table, in incremental update mode, to insert missing records and to update existing ones. You can also perform data integrity checks by invoking the Control CT. Because not all databases support the same bulk update syntax, updates are done row by row. Note: When you use this Integration CT, the following restrictions apply:
|
|
ICT_SQL_TO_FILE_APPEND |
Integration CT |
Integrates data in a target file from any SQL-compliant staging area in replace mode. |
|
ICT_SQL_TO_SQL_APPEND |
Integration CT |
Enables you to use a staging area different from the target. It integrates data in a target SQL-compliant table from any SQL-compliant staging area in replace mode. |
|
CCT_Oracle |
Control CT |
Checks for data integrity against constraints defined on an Oracle table. Rejects invalid records in the error table created dynamically. Can be used for static controls and flow controls. |
|
CCT_SQL |
Control CT |
Checks for data integrity against constraints defined on a SQL-compliant database. Rejects invalid records in the error table created dynamically. Can be used for static controls and flow controls. |
|
JCT_DB2_UDB_CONSISTENT |
CDC CT |
Creates the infrastructure required for consistent Change Data Capture on IBM DB2 UDB tables using triggers. |
|
JCT_DB2_UDB_SIMPLE |
CDC CT |
Creates the infrastructure required for simple Change Data Capture on IBM DB2 UDB tables using triggers. |
|
JCT_MSSQL_CONSISTENT |
CDC CT |
Creates the journalizing infrastructure for consistent journalizing on Microsoft SQL Server tables using triggers. Enables consistent Change Data Capture on Microsoft SQL Server. |
|
JCT_MSSQL_SIMPLE |
CDC CT |
Creates the journalizing infrastructure for simple journalizing on Microsoft SQL Server tables using triggers. Enables simple Change Data Capture on Microsoft SQL Server. |
|
JCT_ORACLE_10G_CONSISTEN_MINER |
CDC CT |
Enables consistent Change Data Capture on Oracle tables. Creates the journalizing infrastructure for consistent journalizing on Oracle 10g tables. Changed data is captured by the Oracle 10g LogMiner-specific utility. |
|
JCT_ORACLE_11G_CONSISTEN_MINER |
CDC CT |
Enables consistent Change Data Capture on Oracle tables. Creates the journalizing infrastructure for consistent journalizing on Oracle 11g tables. Changed data is captured by the Oracle 11g LogMiner-specific utility. |
|
JCT_ORACLE_9I_CONSISTENT_MINER |
CDC CT |
Enables consistent Change Data Capture on Oracle tables. Creates the journalizing infrastructure for consistent journalizing on Oracle 9i tables. Changed data is captured by the Oracle 9i LogMiner-specific utility. |
|
JCT_ORACLE_CONSISTENT |
CDC CT |
Enables consistent Change Data Capture on Oracle tables. Creates the journalizing infrastructure for consistent Change Data Capture on Oracle tables using triggers. |
|
JCT_ORACLE_CONSISTENT_UPD_DATE |
CDC CT |
Enables consistent Change Data Capture on Oracle tables. Creates the infrastructure for consistent Change Data Capture on Oracle tables using a source tables column that indicates the last update date. |
|
JCT_ORACLE_SIMPLE |
CDC CT |
Enables simple Change Data Capture on Oracle tables. Creates the journalizing infrastructure for simple Change Data Capture on Oracle tables using triggers. |
When you use ICT_ORACLE_INCR_UPD_MERGE, sequences are not supported.
When you use ICT_SQL_CONTROL_APPEND in a mapping, an ORDER BY clause associated with this CT does not work. No error message is displayed during the execution of a CT mapping containing this CT. However, the rows are not ordered as specified in the ORDER BY property.
When you use Incremental Update Integration CTs, the Loading Type property of the target Table operator should be set to either INSERT_UPDATE or UPDATE_INSERT. Also, the target Table operator must have Unique key or Primary key defined on it.
ICT_SQL_TO_SQL_APPEND uses two different credentials (one credential to the source schema and another credential to the target schema as defined in the location) to perform the loading. As a result, the map can be run successfully without a permission problem.
ICT_SQL_CONTROL_APPEND uses a single credential (the credential to connect to the target schema) to perform the loading. In other words, the security behavior is similar to existing Oracle Warehouse Builder PL/SQL mapping. As a result, if the target schema has not been granted the permission to access the source schema, an "Insufficient privileges" error is reported.
In general, Oracle Data Integrator Knowledge Modules (KMs) with "multiple connections" property set to true in its KM falls into the first category described above. Please refer to Oracle Data Integrator documentation for details.
Certain transformation operators are designed to leverage functionality provided by the Oracle Database. This functionality is not available in other heterogeneous databases. Thus, you cannot assign execution units that contain these operators directly to Load CTs or Integration CTs. These operators are only supported if you add them to an execution unit that has an Oracle Target CT assigned to it.
The list of operators that you cannot use directly in CT mappings, if the execution unit containing these operators is associated with an Integration CT or Load CT, is as follows:
Anydata Cast
Construct Object
Cube
Dimension
Expand Object
LCR Cast
LCR Splitter
Lookup
Mapping Input Parameter
Mapping Output Parameter
Match Merge
Name and Address
Pivot
Post-Mapping Process
Pre-Mapping Process
Queue
Set Operation
Sorter
Splitter
Table Function
Unpivot
Varray Iterator
Using Restricted Mapping Operators in Code Template Mappings
Execution units that are associated with Oracle Target CTs enable you to use restricted mapping operators in CT mappings. You can use the operators listed in "Mapping Operators Only Supported in Oracle Target CT Execution Units" in execution units, if the execution unit containing these operators is associated with an Oracle Target CT. Hybrid mappings can be constructed which leverage flexible integration capabilities using the loading code templates in addition with the powerful transformation capabilities supported with the use of the Oracle Target CTs.
Certain operations that cannot be performed using CT mappings can be performed using traditional Oracle Warehouse Builder mappings that are deployed as PL/SQL packages. You can perform such mappings as separate execution units.
Performing ETL using CT mappings involves the following steps:
(Optional) "Creating Template Mapping Modules"
If you have not done so, create a Mappings module that contains the mapping.
Note:
After you define execution units, you can optionally configure the CT mapping parameters as described in the following sections:After you run the CT mapping, you can view the execution results as described in "Viewing Execution Results for Code Template Mappings".
You can also audit errors caused during the execution of the CT mapping as described in "Auditing the Execution of Code Template Mappings".
A template mapping module is a container for the mappings that use code templates. You can create a mapping that contains a code template only from the Template Mappings node of the Design Center. Similar to other modules in Oracle Warehouse Builder, each template mapping module is associated with a location that specifies where the mappings in this module should be deployed. Mappings containing code templates are deployed to Oracle Warehouse Builder Control Center Agent.
To create a template mapping module:
In the Projects Navigator, expand the project node under which you want to create a template mapping module.
Right-click the Template Mappings node and select New Mapping Module.
The Create Module Wizard is displayed.
On the Welcome page, click Next.
On the Name and Description page, enter values for the following fields and click Next.
Name: Enter the name of the template mapping module. The name should conform to Oracle Warehouse Builder naming conventions.
Description: Enter an optional description for the template mapping module.
Select the Module Status: Select the status as Development, Quality Assurance, or Production.
On the Connection Information page, specify the details of the location pointing to the Control Center Agent (CCA) to which the CT mappings are deployed. Click Next.
If you previously created a location corresponding to the Control Center Agent, select this location using the Location list. You can also use the default location corresponding to the CCA, DEFAULT_AGENT, that is created by Oracle Warehouse Builder.
To create a location, enter the following details for the Control Center Agent.
Username: User name for the OC4J user that you use to deploy to the CCA. To deploy to the Control Center Agent that is installed with Oracle Warehouse Builder, use oc4jadmin as the user name.
Password: Password for the OC4J user that you use to deploy to the CCA.
Host: The host name of the computer on which the Control Center Agent is installed.
Port: The value of the RMI port used by the OC4J server.
Port Type: To deploy to the agent location associated with the CCA that is installed along with Oracle Warehouse Builder, use RMI as the port type.
The other options you can choose for port type are OPMN and RMIS.
Instance: Name of the OC4J instance corresponding to the CCA. To deploy to the default CCA installed with Oracle Warehouse Builder, leave this field blank.
Application Name: Name of the application to which CT mappings should be deployed. To deploy to the default CCA installed with Oracle Warehouse Builder, use jrt as the application name.
On the Summary page, review the information that you entered in the wizard. Click Finish to create the template mapping module. Click Back to modify any entered values.
The Template mapping module is created and added to the navigator tree under the project.
To use the functionality defined by code templates in your environment, you create a Code Template (CT) mapping. The process to create a CT mapping is similar to a regular PL/SQL mapping, except for the additional step of defining execution units and associating them with code templates.
Every CT mapping must belong to a mapping module.
Note:
Do not use CT mappings with Joiner Input Roles if the join is performed on 2 or more tables.To create a CT mapping:
In the Projects Navigator, expand the project node and then the Template Mappings node under which you want to create a CT mapping.
Right-click the mapping module in which you want to create the CT mapping and select New Mapping.
The Create Mapping dialog box is displayed.
Enter the name and an optional description for the CT mapping and click OK.
The Mapping Editor for the CT mapping is displayed.
On the Logical View tab, add the required operators and establish data flows that perform the required data transformation.
For more information about how to add operators and establish data flows between them, see Chapter 5, "Creating PL/SQL Mappings".
The Execution View tab of the Mapping Editor enables you to define execution units. Use execution units to break up your mapping execution into smaller, related units and to associate a part of your mapping with a code template. Oracle Warehouse Builder generates code separately for each execution unit that you define.
The Execution View tab of the Mapping Editor displays the operators and data flows from the Logical View in an iconized form. You cannot edit operators or create data flows in the Execution View. You must perform these operations using the Logical View. Create execution units as defined in "Creating Execution Units".
Note:
If you do not explicitly assign a code template to an execution unit, Oracle Warehouse Builder assigns a default code template to the execution unit. For more details about default code templates, see "Default Code Template for An Execution Unit".When you select the Execution View tab, the Design Center displays an additional menu called Execution and an Execution toolbar. Use these to:
Create and delete execution units
Define default execution units
Associate code templates with execution units
Create an execution unit for a group of operators for which code generation and execution are controlled by a specific code template.
To create an execution unit:
In the Execution View of the mapping, select the operators to group into an execution unit.
You can do this by drawing a rectangle around the operators. Hold down the mouse button at the top of the first operator, drag the mouse so that you cover the required operators and then release the mouse button. Alternatively, hold down the Ctrl key and click the headers of all the operators to include in an execution unit.
From the Execution menu, select Create Execution Unit. Or click Create Execution Unit on the Execution View toolbar.
Oracle Warehouse Builder creates an execution unit for the selected operators and assigns a default name to it. To rename the execution unit, right-click the name and select Open Details. In the Edit Execution Unit dialog box, enter the new name for the execution unit.
To associate a code template with an execution unit:
If the Code Template panel is not displayed, from the View menu, select Code Template.
The Code Templates tab is displayed in the Log window panel.
In the Execution View tab of the Mapping Editor, select the execution unit with which you want to associate a code template.
In the Code Templates tab, use the list to select the code template with which the selected execution unit should be associated.
The code templates displayed in the list depend on the source and target platforms of the operators in the selected execution unit. They also depend on the nature of the execution unit. For example, you can associate a Load CT with an execution unit that does not contain any operators bound to data objects. You can associate an Integration CT with an execution unit that contains one target operator bound to a repository data object.
To add operators to an execution unit:
In the Execution View of the Mapping Editor, select both the execution unit and the operators to add to the execution unit.
You can select multiple objects by holding down the Ctrl key while selecting objects.
From the Execution menu, select Add Operator to Execution Unit. Or click Add Operator to Execution Unit on the Execution View toolbar.
An operator may appear in multiple execution unit, such as when it is a target in one execution unit and a source in another.
For example, you have a Table operator cust_tab in the execution unit CUST_EXEC_UNIT. You can copy cust_tab to another execution unit EX_UNIT_2 (which exists) by selecting both cust_tab and EX_UNIT_2 and then clicking Add Operator to Execution Unit. A copy of cust_tab is added to EX_UNIT_2.
Consider the Table operator cust_tab, which is a target in the execution unit CUST_EXEC_UNIT. Select cust_tab and then click Create Execution Unit to create an execution unit containing a copy of cust_tab. The label of this copy must be <cust_tab>, using the angle brackets as a visual cue that the operator appears in multiple execution units.
To remove operators from an execution unit:
In the Execution View of the Mapping Editor, select the operator or operators to remove from an execution unit.
From the Execution menu, select Remove Operator from Execution Unit. Or click Remove Operator from Execution Unit on the Mapping Editor toolbar.
The selected operators are removed from the execution unit and displayed separately in the Execution View.
Note:
You cannot remove an operator from an execution unit when it is the only operator in the execution unit.When you remove an existing execution unit, the operators that were part of the execution unit are not associated with any execution unit. You must associate these operators with other execution units, if required.
If you remove execution units, you must regenerate and deploy updated code for the mapping before your changes take effect.
To remove an execution unit:
In the Execution View of the Mapping Editor, select the execution unit to remove.
From the Execution menu, select Remove Execution Unit. Or click Remove Execution Unit on the Execution View toolbar.
The execution unit is removed. Any operators that were contained in this execution unit are displayed individually, instead of grouped under the execution unit.
You can create a default set of execution units by clicking Default Execution Units or by selecting Default Execution Units from the Execution menu. Oracle Warehouse Builder first removes all existing execution units and then creates a new set of execution units such that all operators are assigned to some execution unit.
The operators are assigned to execution units based on factors such as their location. Operators that are at a different location are assigned to different execution units. If all operators are at the same location, then the default may consist of a single execution unit containing all operators.
The names of the default execution units depend on whether the location associated with the operators in the execution units is known. When the execution unit location (location associated with operators in the execution unit) is known, the name of the default execution unit is set to the location name followed by "_EU". If the location associated with the execution unit is not known, then the execution unit name starts with "MAP_EX_UNIT_",
If you do not explicitly associate a code template with an execution unit, during code generation, Oracle Warehouse Builder assigns a default code template. The default code template depends on the platform of the target operators. You can define default code templates for each platform.
For example, you can define a default Load CT, Integration CT, and Oracle Target CT for the Oracle Database platform. When you do not assign a code template to an execution unit that contains operators referencing Oracle Database objects, Oracle Warehouse Builder Code Generator performs the following steps:
Identifies the type of code template that is necessary for that particular execution unit
Retrieves the default code template that should be assigned to the execution unit using the platform of the location with which the execution unit is associated
Assigns the retrieved code template to the execution unit
Note:
You can define default code templates for a platform only using OMB*Plus. For more information about OMB*Plus, see Oracle Warehouse Builder API and Scripting Reference.If no default code templates are defined for a particular platform, Oracle Warehouse Builder picks a code template from the available code templates and assigns it to the execution unit. It then updates the platform definition and assigns the selected code template as the default code template definition for that platform.
A default code template can be assigned to an execution unit only if the CT mapping containing the code template and the default code template belong to the same project.
When associating a CT with execution units, the CTs displayed in the UI list are filtered by the source and the target platforms. For example, if the execution unit containing your source tables is an Oracle database, the CTs available for selection for this execution unit are ones that can be used for Oracle sources.
In certain simple mappings, you may create a single execution unit that contains the source and target operators. In this case, the list of available Integration CTs is limited by the following:
Source Platform
Platform
The value set for the Multi-Connections property of the CT
The Control Center Agent is the agent that runs the code templates in the OC4J server. You must start the Control Center Agent before you deploy code templates or CT mappings.
Starting the Control Center Agent (CCA)
On Windows, start the Control Center Agent by running the ccastart.bat script located in the OWB_HOME/owb/bin/win32 directory.
On UNIX, start the Control Center Agent by running the ccastart file located in the OWB_HOME/owb/bin/unix directory.
Note:
It is recommended that you not runccastart.bat or ccastart multiple times to start multiple CCA instances. You must run multiple CCA instances, then install separate CCA instances on the Application Server using the installation steps required to install a CCA on the Application Server.Stopping the Control Center Agent (CCA)
On Windows, stop the Control Center Agent by running the ccashut.bat script located in the OWB_HOME/owb/bin/win32 directory. This script takes the password of the oc4jadmin user as an input parameter.
On UNIX, stop the Control Center Agent by running the ccashut file located in the OWB_HOME/owb/bin/unix directory. This script takes the password of the oc4jadmin user as an input parameter.
Validating a Code Template (CT) mapping verifies the metadata definitions and configuration parameters to ensure that they are valid according to the rules defined by Oracle Warehouse Builder. As part of validation, Oracle Warehouse Builder verifies the assignment of operators to execution units. It also ensures that the code generated to perform the ETL task defined in the CT mapping can be generated correctly.
During validation, Oracle Warehouse Builder checks the following rules:
An operator cannot be connected to two or more downstream operators in different execution units.
An execution unit cannot contain non-Oracle source or target operators and other restricted mapping operators.
Only Oracle Target CTs can be assigned to an execution unit with restricted operators.
A transformation or data target operator containing multiple incoming connection cannot exist in multiple execution unit.
An execution unit cannot have outgoing connections to multiple execution unit.
Generating a Code Template (CT) mapping creates the scripts necessary to perform the ETL task in Oracle Warehouse Builder workspace. For CT mappings, Tcl scripts are generated.
When you generate a CT mapping, Oracle Warehouse Builder first validates it. After the validation is successful, the CT mapping is generated. Generation produces the following scripts, which are part of an .ear file:
Variable script, var.tcl
This script contains the variables that must be substituted in the substitution method calls of the code template script. The script collects all the defined mapping variables into a single Tcl variable that contains a map of name to value.
This script stores all metadata, as described by the mapping, and this metadata is used by the code template (through its substitution methods). During execution of the CT mapping, the substitution methods in the code template are run in the Control Center Agent and their return values are computed from the appropriate metadata in the variable script. The metadata variable names do not directly match the names or patterns defined in the substitution methods; the implementation of the substitution methods performs that translation.
Driver script, driver.tcl
The driver script first invokes the variable script to load the metadata variable values into the Jacl interpreter of the Control Center Agent. Next, for each execution unit, it invokes the main method of the code template associated with that execution unit.
The order of execution of the code templates is automatically derived from the topology of the mapping in the Execution View.
If any errors occurred during generation, use the Mapping Editor to correct them and then regenerate the CT mapping.
The results of the generation are displayed in a Results tab in the Log window. The Results tab displays a parent node that indicates whether the generation was successful. Under this node is one that uses the same name as the CT mapping that you generated. This node contains the validation results under the Validation node and the generated scripts under the Scripts node. Expand the node containing the results you want to view.
The Scripts node under the generation results contains the var.tcl and driver.tcl scripts that contain the code generated to create the CT mapping.
To view the generated code, expand the Scripts node. Right-click var.tcl or driver.tcl and click View Script. Or double-click the .tcl files to display their contents in a new tab in the Mapping Editor.
Note:
If the Mapping Editor displays a tab that contains generated code for a CT mapping, ensure that you close this tab before you view the generated code for another CT mapping. If you do not close the tab containing previous generated code, then you may see conflicting results for the generated code.Following are some code examples from a code template and its associated metadata script, showing the substitution. The following code block displays a single procedural step of a code template, creating a temporary flow table.
proc 3_CREATE_FLOW_TABLE_I__main { }
{
# Input Flow Parameters
variable SRC_LOCATION
variable TGT_LOCATION
variable KM_PARAMS
variable LOG_LEVEL
variable INSERT
variable UPDATE
variable COMMIT
variable SYNC_JRN_DELETE
variable FLOW_CONTROL
variable RECYCLE_ERRORS
variable STATIC_CONTROL
variable TRUNCATE
variable DELETE_ALL
variable CREATE_TARG_TABLE
variable FLOW_TABLE_OPTIONS
variable ANALYZE_TARGET
variable OPTIMIZER_HINT
# Output parameters
variable EXIT_CODE
variable RETURN_VALUE {}
# Global variables
global errorInfo
global g_iud
set g_iud ""
set tgt_stmt [process "create table <%=snpRef.getTable(\"L\", \"INT_NAME\", \"W\")%>\n(\n<%=snpRef.getColList(\"\", \"\\t\[COL_NAME\]\\t\[DEST_WRI_DT\] NULL\", \",\\n\", \"\", \"\")%>,\n\tIND_UPDATE \tchar(1)\n)\n<%=snpRef.getUserExit(\"FLOW_TABLE_OPTIONS\")%>"]
puts $tgt_stmt
execjdbc $tgt_stmt "TGT_AC" "$TGT_LOCATION" "" "true" "false" "false"
}
Notice that a target SQL statement, variable tgt_stmt, is assigned an actual SQL statement which is then run using the execjdbc procedure call. The execjdbc tcl procedure makes a Java call to run the statement through JDBC. The target statement is a string produced by the process procedure. The <%...%> delimiters require special processing to substitute required components into the SQL string. The snpRef tag is the prefix for a substitution method callout. snpRef.getTable is replaced by the actual table name. snpRef.getColList is another universal method to retrieve the list of table columns participating in the DML. In addition to snpRef, odiRef is supported (as in Oracle Data Integrator 10.2).
The substitution method (snpRef) calls are completed by an Oracle Warehouse Builder Tcl module which extracts the associated data from a variable of the metadata script. The following is an example of a metadata script section showing the table name and column list:
set M1_params {
{CKM_CALL ""}
{COLUMN_GENERIC_DATATYPE "NUMERIC VARCHAR"}
{COLUMN_LIST "EMPLOYEES.EMPLOYEE_ID EMPLOYEES.LAST_NAME"}
{COLUMN_LIST_ALIAS "EMPLOYEE_ID LAST_NAME"}
{COLUMN_LIST_DATATYPE "NUMBER(6) VARCHAR2(25)"}
{EXECUTION_UNIT_NAME "EX_UNIT_2"}
{FROM_LIST "EMPLOYEES"}
{FROM_LIST_ALIAS "EMPLOYEES"}
{HAS_JRN "0"}
{INSERT_COLUMN_LIST "EMPID ENAME"}
{IS_DISTINCT "FALSE"}
{JOURNAL_IN_CURRENT_SCHEMA "false"}
{JOURNAL_IN_SOURCE_SCHEMA "false"}
{JOURNAL_IN_STAGING_AREA "false"}
{JRN_FILTER ""}
{JRN_METHOD "NONE"}
{JRN_TABLE "."}
{KM_NAME "KM_IKM_ORACLE_INCREMENTAL_UPD"}
{MAP_NAME "MAPPING_2"}
{SELECT_STATEMENT "SELECT EMPLOYEES.EMPLOYEE_ID EMPLOYEE_ID,
EMPLOYEES.LAST_NAME LAST_NAME
FROM
EMPLOYEES EMPLOYEES"}
{SQL_STATEMENT "INSERT INTO TGT(EMPID, ENAME)
(SELECT EMPLOYEES.EMPLOYEE_ID EMPLOYEE_ID,EMPLOYEES.LAST_NAME LAST_NAME
FROM
EMPLOYEES EMPLOYEES
)
;"}
{TARGET_COLUMN_DATATYPE "NUMBER(15) VARCHAR2(100)"}
{TARGET_COLUMN_LIST "EMPID ENAME"}
{TARGET_GENERIC_DATATYPE "NUMERIC VARCHAR"}
{TARGET_NAME "TGT"}
}
To deploy a Code Template (CT) mapping, use the Control Center Manager. In the Control Center navigation tree, CT mappings are listed under the agent location that is associated with the mapping module containing the CT mappings.
Deploying a CT mapping copies the generated scripts to the CCA.
Before you deploy a CT mapping, ensure that you deploy all the code templates associated with it.
To deploy a code template mapping:
From the Design Center, open the Control Center by selecting Control Center Manager from the Tools menu.
In the Control Center navigation tree, expand the project node under which you created the CT mapping. Then expand the location node associated with the mapping module that contains the CT mapping.
Expand the mapping module node that contains the CT mapping.
Select the CT mapping to be deployed and, in the Object Details panel, select Create as the Deploy Action.
Click Deploy.
The Control Center Jobs panel contains a new entry for to the deployment job corresponding to the deployed CT mapping. If the deployment is successful, then the status displays a success message. If the deployment fails, then double-click the error message to view the details of the error.
When you run a Code Template (CT) mapping, the code template is used to perform the data integration task defined in the CT mapping. Before you run a CT mapping, ensure that the CT mapping is deployed as described in "Deploying Code Template Mappings".
To run a CT mapping, in the Control Center Manager, select the CT mapping and click Start.
Or, from the Projects Navigator, right-click the CT mapping and select Start.
The CT mapping is run and the ETL defined by it is performed.
J2EE Runtime environment referred to as the CCA (Control Center Agent) controls the execution of CT mappings. The CCA is separate from the Runtime Platform. The CCA runs a mapping by executing Tcl/Java (Jacl) scripts. Because the execution is performed entirely by the CCA, it can be invoked separately from Service Oriented Architecture (SOA) interfaces.
Note:
While executing complex CT mappings that could take more than a day to run, it is recommended that you split the job into smaller ones. The default transaction timeout for the OC4J is set to one day. If your job execution takes more than a day, then the execution times out and unexpected errors may be encountered.You can view execution results for a Code Template (CT) mapping by using the Results tab or Audit Information panel.
Note:
The number of rows selected is not audited during CT mapping execution. Thus, the execution results do not contain the number of rows selected.When you run a CT mapping using the Design Center, a new Results tab is created in the Log window to display the CT mapping execution results. The Results tab contains a node called Execution that contains the execution results. This displays details about the number of rows inserted, updated, and deleted during the CT mapping execution.
The Audit Information panel enables you to view additional details about the CT mapping execution. You can also view results for previous executions of the CT mapping. To display the Audit Information panel, from the View menu, select Audit Information.
Expand the location node to which the CT mapping is deployed to view the jobs for this CT mapping. Because you can run a CT mapping multiple times, each execution is represented by a job. Each job contains a node for execution units, which in turn contains a node for steps. Details such as number of rows inserted, updated, deleted, and selected are displayed. Use the Execute Statement tab to view the statement used to run a step.
While running the CT mapping or Change Data Capture process, the Audit Information panel displays the job and its child nodes, such as Execution Units (for CT mapping only), Tasks, and Steps, as they are being run. The status for each job is also displayed. You can filter tasks for a Job in the Audit Information panel based on the status (such as Skipped, Warnings, and so on). The default is set to Filter None, which means that no filtering is performed. You can also sort Jobs by Timestamps.
Use the Message tab to view any message during the execution of the steps, such as an exception from the JDBC driver during the execution of a JDBC task.
Modes of Operation for the Audit Information Panel
The Audit Information panel can display audit information in the following modes:
If a CT mapping is selected in the Projects Navigator, only the execution audit for that CT mapping is displayed.
If you select a Function CT in the Projects Navigator, only execution audit information for the selected CT is displayed.
If you select a module containing CDC tables in the Projects Navigator, the audit information for CDC is displayed.
If you select an agent in the Locations Navigator, the execution audits for all the jobs run in that agent (including CT mapping, CDC execution, and CT function deployment) are displayed.
When you use a code template in a CT mapping, the options that you can set for the code template depends on the type of code template.
Oracle Warehouse Builder is not aware of the options that work with each platform or database. Thus, validating and generating your CT mappings does not automatically verify if the option that you set works with the platform or database associated with the code template. For example, Teradata does not support the TRUNCATE statement. Thus, if you set the Truncate property to true for a code template associated with a Teradata source or target, you encounter errors while executing the CT mapping.
Table 7-3 describes the options that you can set for each type of code template in a CT mapping. You can add new options to code templates and use them in CT mappings.
Table 7-3 Options for Code Templates in Code Template Mappings
| Option Name | Description | Option applicable for Code Template Types |
|---|---|---|
|
After ICT |
Set to True to clean up work tables after the ICT has completed integration in the target. This property enables you to decide to keep work tables after the mapping completes (primarily for debugging purposes). |
Load CT |
|
Commit |
Set to True to indicate that a commit should be performed after the integration task is completed. |
Integration CT |
|
Create_targ_table |
Set to True to create the target table. Set to False if the table exists. |
Integration CT |
|
Delete_all |
Set to True to delete all rows from the target table. |
Integration CT |
|
Delete_temporary_objects |
Set to True to delete temporary objects created during the Integration CT execution, if any. |
Integration CT Load CT |
|
Drop_check_table |
Set to True to drop the check table. The check table contains statistics about the errors found. |
Control CT |
|
Drop_error_table |
Set to True to delete the error table containing information about specific errors detected. |
Control CT |
|
Flow_Control |
Set to True to activate flow control. Flow control detects errors before inserting data into the target table. |
Integration CT Control CT |
|
Flow_table_options |
Specify the options for flow table creation. |
Integration CT |
|
Insert |
Set to True to indicate that the code template can insert new rows into the target table. |
Integration CT |
|
Deploy_files |
Indicates if the CT always deploys the associated PL/SQL code. Set to False to only deploy the PL/SQL code if the mapping does not exist in the database or if the mapping is different version as the deployed mapping. Set to True if a previous code template is creating the tables for this mapping. In general this should be set to false. |
Oracle Target CT |
|
Log_level |
Represents the level of log reporting when the code template is run. Valid values are between 0 and 5, with 5 representing the most detailed logging. |
Integration CT Load CT CDC CT Oracle Target CT |
|
Static_control |
Used for postintegration control. Detects errors on the target table after integration has been completed. |
Integration CT |
|
Target_location |
Represents the Oracle location to which the PL/SQL mapping is to be deployed. |
Oracle Target CT |
|
Truncate |
Set to True to truncate the target table before loading data. |
Integration CT |
|
Update |
Set to True to indicate that the code template can update rows in the target table. |
Integration CT |
For operators in CT mappings that are bound to data objects, you can set properties for the operator attributes. These attribute values are used in the substitution methods when the CT mapping is run.
Operators, in CT mappings, that are bound to data objects have the following additional properties. These operators are listed under the Code Template Metadata Tags node in the Property Inspector.
Use the SCD property to specify the role played by the attribute when using the Slowly Changing Dimension code template. The values you can set for this property are:
Surrogate Key: The attribute is used as a unique record identifier (primary key) in the target table. You must map a sequence to this attribute.
Natural Key: The attribute is mapped from the unique record identifier (business key of the record) in the source table.
Current Record Flag: The attribute is used to identify the current active record. The current record has the flag set to 1 and old records have the flag set to 0. The attribute must be numeric and is loaded automatically, you should not map it.
Update Row on Change: If a new value is loaded for this attribute, the value of its corresponding column is overwritten, for the record with the same natural key.
Add Row on Change: If a new value is loaded for this attribute, a row with a new surrogate key but with the same natural key is inserted into the target table. The inserted record is marked as current.
Starting Timestamp: The start time of the time period when the record is current. If the new row is inserted, then the Starting Timestamp of new record and Ending Timestamp of the old record are set to SYSDATE.
Ending Timestamp: The end time of the time period when the record is current. For the current record, the ending timestamp column value is usually 01-01-2400.
Set this property to True to include this attribute in code template functions using the UD1 tag.
Set this property to True to include this attribute in code template functions using the UD2 tag.
Set this property to True to include this attribute in code template functions using the UD3 tag.
Set this property to True to include this attribute in code template functions using the UD4 tag.
Set this property to True to include this attribute in code template functions using the UD5 tag.
This property controls which columns are updated when Update Code Templates, such as ICT_SQL_ INCR_UPD or ICT_ORACLE_INCR_UPD_MERGE are used.
To specify which constraint to use for matching, use the Match by Constraint property of the target operator. If the UPD property is not set, then the operator's match by constraint key is used.
You can set certain configuration properties for operators that are used in CT mappings. This section describes the configuration properties.
You can set the Source File Operator configuration property for Flat File operators that are used in CT mappings. This property identifies the Flat File operator with which the data file is associated.
For CT mappings that contain multiple Flat File operators, you must set the Source File Operator property. When your CT mapping contains only one Flat File operator, setting this property is optional.
Use the following steps to set the Source File Operator configuration property:
Right-click the CT mapping that contains the Flat File operators and select Configure.
The Configuration tab for the CT mapping is displayed.
Click the Ellipsis on the SQL Loader Data Files property.
The SQL Loader Data Files dialog box is displayed.
Select the file name on the left of the dialog box and, on the right, set the Source File Operator property.
The Audit Information panel in the Design Center provides detailed information about each task that was run as part of a CT mapping execution. You can use this information to audit errors caused during the execution of CT mappings.
However, for the Audit Information panel to display execution details, you must set certain properties as described in "Prerequisites for Auditing Code Template Mappings".
Figure 7-5 displays the Audit Information panel for a CT mapping execution.
Figure 7-5 Audit Information Panel with Details about Executed Tasks
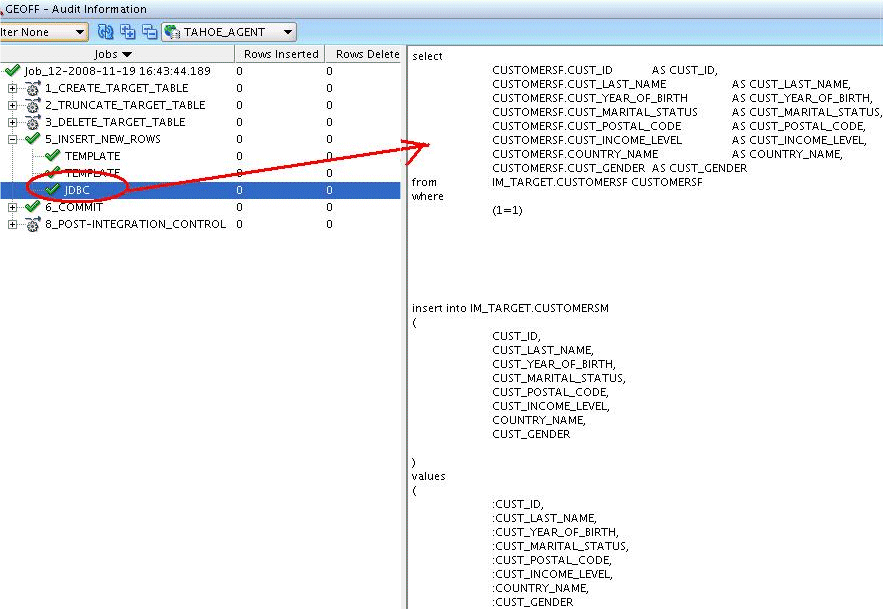
The Audit Information panel displays the individual steps that are run as part of the CT mapping execution. The details displayed for each step include the name of the task, the number of rows inserted, updated, or deleted for the task, and its status.
Detailed information about the steps within the CT mapping is displayed. For each step, you can see error messages, if any. You can also view the statements that are run for each task. Expand the node representing each task to view details of the task execution.
Not all tasks are listed in the Audit Information panel. If the settings of a task exclude it from the audit, then the task is not displayed. For more information about including a code template task in audits, see "Prerequisites for Auditing Code Template Mappings".
For example, in the Audit Information panel displayed in Figure 7-5, the CT mapping contains the following tasks: CREATE_TARGET_TABLE, TRUNCATE_TARGET_TABLE, DELETE_TARGET_TABLE, INSERT_NEW_ROWS, COMMIT, and POST_INTEGRATION_CONTROL. The statements that are run as part of the INSERT_NEW_ROWS task are displayed in the panel on the right. Notice that task 4 is not listed in the Audit Information panel. This is because the settings of this task exclude it from the audit.
Prerequisites for Auditing Code Template Mappings
For Oracle Warehouse Builder to provide detailed information about the execution of a CT mapping, you must set the following properties:
Log Audit Level
Every task in a code template contains a property called Log Audit Level. You can set a value between 0 and 5 for this property. Setting a value of 0 means that the details of this task are not included in the audit. Set this property to a value between 1 and 5 to include the details for this task execution in the audit log.
Log Level
Every execution unit in a CT mapping contains a property called Log Level. This property represents the level of logging performed for the execution unit. You can set a value between 0 and 5 for this property. Set a value of 0 to exclude this execution unit from being logged. Set this property to a value between 1 and 5 to specify the level of detail used to log the execution of this execution unit.
In the Projects Navigator, select the CT mapping whose execution must be audited.
From the View menu, select Audit Information.
The Audit Information panel is displayed in the Log window.
Expand the node that represents the CT mapping execution job.
Separate nodes are displayed for each task in the CT mapping that is included in the audit.
Expand a task node to view the list of steps performed as part of this task.
To view the statements that are run as part of a particular step, select the step and then select Executed Statement.
The statements that are run are displayed on the right.
In a typical data warehousing environment, you extract data from source systems, transform data, and then load it into the data warehouse. However, when the data in the source system changes, you must update the data warehouse with these changes. Change Data Capture (CDC) quickly identifies and processes only data that has changed and then makes this changed data available for further use. Oracle Warehouse Builder enables you to perform CDC by using CDC CTs.
Oracle Warehouse Builder enables you to perform the following types of CDC:
Consistent
Consistent Change Data Capture ensures the consistency of the captured data. For example, you have the ORDER and ORDER_LINE tables (with a referential integrity constraint because an ORDER_LINE record should have an associated ORDER record). When the changes to ORDER_LINE are captured, the associated ORDER change is also be captured, and vice versa.
The set of available changes for which consistency is guaranteed is called the Consistency Window. Changes in this window should be processed in the correct sequence (ORDER followed by ORDER_LINE) by designing and sequencing integration interfaces into packages.Although consistent Change Data Capture is more powerful, it is more difficult to set up. Use this method when referential integrity constraints must be ensured while capturing the data changes. For performance reasons, consistent Change Data Capture is also recommended when a large number of subscribers are required.
Note: You cannot journalize a model (or data stores within a model) using both consistent set and simple journalizing.
Simple
Simple Change Data Capture enables you to journalize one or more data stores. Each journalized data store is treated separately when capturing the changes.
This approach has a limitation, illustrated in the following example: You must process changes in the ORDER and ORDER_LINE tables (with a referential integrity constraint because an ORDER_LINE record should have an associated ORDER record). If you have captured insertions into ORDER_LINE, then you have no guarantee that the associated new records in ORDERS have also been captured. Processing ORDER_LINE records with no associated ORDER records may cause referential constraint violations in the integration process.
Consistent Change Data Capture uses the following module commands: "Start", "Drop", "Subscribe", "Unsubscribe", "Extend Window", "Lock Subscriber", "Unlock Subscriber", and "Purge Data".
Simple Change Data Capture provides the following commands for modules and tables: "Start", "Drop", "Subscribe", and "Unsubscribe". The commands Lock Subscriber and Unlock Subscriber are available but not used.
The Start command sets up the Change Data Capture infrastructure.
The Drop command removes the Change Data Capture infrastructure.
The Subscribe command adds a subscriber to this Change Data Capture
The Unsubscribe command removes a subscriber from this Change Data Capture
The Consistency Window is a range of available changes in all the tables of the consistency set for which the insert/update/delete are possible without violating referential integrity. The Extend Window operation computes this window to consider new changes captured since the latest Extend Window operation.
Although the extend window is applied to the entire consistency set, subscribers consume the changes separately. The Lock Subscriber operation performs a subscriber-specific snapshot of the changes in the consistency window. This snapshot includes all the changes within the consistency window that have not yet been consumed by the subscriber.
The Unlock Subscriber command commits the use of the changes that where locked during the Lock Subscribers operations for the subscribers. This operation should be processed only after all the changes for the subscribers have been processed.
After all subscribers have consumed the changes they have subscribed to, entries still remain in the capture tables and must be deleted. This deletion is performed by the Purge Data command.
Scenario for Performing Change Data Capture
The ORDERS table, in the source schema SRC, stores order details. Data from this table is loaded into the WH_ORDERS table in the data warehouse target schema WH_TGT. The data in the ORDERS table changes when an order status or dispatch date is updated. The data in the data warehouse must be updated based on changes made to the source data.
You can set up Change Data Capture using CDC CTs and load only the changed data to the target table in the data warehouse.
Performing Change Data Capture includes the following steps:
You can perform Change Data Capture for any source or target for which code templates are available. The first step in performing CDC is to identify and select the objects for which you want to capture changes.
To specify the objects for which data changes must be captured:
If you have not done so, create a module and import the source objects whose data changes you want to capture.
In this example, the source schema SRC contains the ORDERS table whose changes you want to capture. Create an Oracle module called SRC_MOD, whose location points to the SRC schema, and import the ORDERS table into this module.
Double-click the SRC_MOD module to display the Edit Module dialog box.
In the left panel, click CDC Code Template. On the CDC Code Template page, in the Code Template list, select the code template that you imported to perform Change Data Capture.
In this example, select PUBLIC_PROJECT/BUILT_IN_CT/JCT_ORACLE_SIMPLE.
In the left panel, click CDC Tables. On the CDC Tables page, use the buttons to move tables whose changes must be captured from the Available section to the Selected section.
In this example, move the ORDERS table from the Available list to the Selected list.
The ORDERS table is now set up for Change Data Capture.
Use the following steps to create the CT mapping that loads changes.
If you have not done so, create a template mapping module to contain the CT mapping that performs Change Data Capture.
Ensure that the location of this template mapping module is associated with the agent to which the CT mapping must be deployed.
In this example, the template mapping module called CDC_MAP_MOD is associated with the DEFAULT_AGENT location. This location represents the OC4J server installed with Oracle Warehouse Builder.
Under the template mapping module created in Step 1, create a CT mapping that contains the ETL logic for performing CDC.
The mapping created in this example is called CDC_LOAD_ORDERS_MAP.
Drag and drop the source object whose changes you want to capture.
In this example, drag and drop the ORDERS table from the SRC_MOD module onto the Mapping Editor canvas.
Select the operator representing the source object. In the Property Inspector, under the Change Data Capture node, select Enable.
Notice that the ORDERS Table operator contains three additional attributes: JRN_SUBSCRIBER, JRN_FLAG, and JRN_DATE.
In the Property Inspector, under the Change Data Capture node, set the Change Data Capture Filter property to define the condition that is used to select changed data for a particular subscriber.
Drag and drop the table that stores the changed data onto the canvas.
In this example, the table ORDERS_CHANGE in the SRC_MOD module stores the changes to the ORDERS table.
Map the attributes from the source table, whose changes you want to capture, to the corresponding attributes in the target table that stores changed data.
In this example, map the order_Id, order_status, order_mode, and JRN_DATE attributes from the ORDERS table to order_id, order_status, order_mode, and change_date attributes, respectively, in the ORDERS_CHANGE table.
In the Execution View of the CT mapping, create the execution units to associate with code templates.
In this example, select the ORDERS and ORDERS_CHANGE operators and click Create Execution Unit on the Execution View toolbar.
Or, select ORDERS and ORDERS_CHANGE and select Create Execution Unit from the Execution menu.
If the Code Templates panel is not displayed in the Log window, from the View menu, select Code Templates.
Select the Integration/Load Code Template tab in the Code Templates panel.
In the Code Template for EX_UNIT1 field, select the code template to be used.
In this example, select JCT_ORACLE_SIMPLE as the code template used to perform the ETL.
Validate the mapping and rectify any errors.
After you set up the tables for Change Data Capture and create the CT mapping that loads changes from the source table, deploy the Change Data Capture solution using the following steps:
If you have not done so, start the Control Center Agent as described in "Starting the Control Center Agent (CCA)".
Deploy the target table that stores the changed data.
In this example, deploy the ORDERS_CHANGE table using either the Design Center or Control Center Manager.
Deploy the CT mapping that loads changed data into the target table using the Design Center or Control Center Manager.
If you get an error saying application exists, go to the Control Center Manager, select Replace as the Deployment Option, and deploy the mapping.
In this example, deploy the CDC_ORDERS_LOAD_MAP mapping using the Design Center or Control Center Manager.
When you start the Change Data Capture process, Oracle Warehouse Builder creates triggers on the source table for which you want to capture changes and on the target table. For your CT mapping to run successfully, ensure that you grant the required privileges on the source schema to the user performing CDC.
To start the capture process, in the Projects Navigator, right-click the module containing the source table for which you want to capture changes, select Change Data Capture, then Start.
In this example, right-click SRC_MOD, select Change Data Capture, then Start.
A new tab is displayed in the Message Log containing messages about the CDC operation. During this process, Oracle Warehouse Builder generates DDL scripts to create triggers on the source table and deploys the DDL scripts.
After you start the Change Data Capture process, you must add a subscriber to the capture system. The subscriber consumes the changes generated by the Change Data Capture process.
To add a subscriber:
In the Projects Navigator, right-click the module containing the source table, select Change Data Capture, then Subscribe.
The Add Subscriber dialog box is displayed containing the list of current subscribers.
In this example, right-click SRC_MOD, select Change Data Capture, then Subscribe.
In the Subscriber Name column of the Subscriber to add section, enter a subscriber name.
In this example, enter Ord_subscriber in the Subscriber Name column.
Click OK to close the Add Subscriber dialog box.
The Log window displays a new panel for the Subscribe action that lists the actions being performed for the Subscribe action and the results of the actions. If this log displays errors, rectify them and then run the steps to add a subscriber.
After you set up your Change Data Capture process, you can optionally test this system to verify that changes to the source are being captured and made available to the subscriber.
To test your Change Data Capture system:
In SQL*Plus, log in to the schema that contains the source table for which you want to capture changes.
In this example, log in to the SRC schema.
Insert a row into the source table.
In this example, insert a row into the ORDERS table.
In the Control Center Manager, select the CT mapping that performs Change Data Capture and click Start.
In this example, start the CDC_LOAD_ORDERS_MAP mapping.
The row that you just added should be inserted into the target table.
The Job Details panel displays the details about each operation being performed in the CT mapping.
After you set up your Change Data Capture solution, you manage the change capture process using predefined actions. If you publish the module or table with CDC tracking as a Web service, then the actions defined in these objects are contained in the generated Web service.
To perform these actions, you right-click the module or table with CDC tracking, select Change Data Capture, and use the following actions available here: Start, Drop, Subscribe, Unsubscribe, Extend Window, Purge Data, Lock Subscriber, and Unlock Subscriber. This section describes the CDC actions that you can perform.
Actions applicable depend on the type of Change Data Capture you are performing.
See Also:
"Change Data Capture Commands" for information about the Change Data Capture commands.Starting the Change Data Capture
After you set up the source object for Change Data Capture, right-click the object and select Start to begin capturing changed data. For more details, see "Starting the Change Data Capture Process".
Stopping a Change Data Capture System
The "Drop" action stops the Change Data Capture process and drops the capture objects.
To stop a Change Data Capture process, in the Projects Navigator, right-click the data object or module, select Change Data Capture, then Drop. Oracle Warehouse Builder displays a prompt asking to stop the capture and drop capture objects. Click Yes.
Subscribing to a Change Data Capture System
The "Subscribe" action enables you to add a subscriber to the Change Data Capture system. For more information about adding subscribers, see "Adding a Subscriber to the Change Data Capture Process".
Removing a Subscriber from a Change Data Capture System
The "Unsubscribe" action enables you to remove a subscriber from the Change Data Capture system. Once you remove a subscriber, change data that is being captured is not available to the subscriber.
To remove a subscriber:
In the Projects Navigator, right-click the data object or module from which you want to remove a subscriber and, from the Change Data Capture menu, select Unsubscribe.
The Remove Subscriber dialog box is displayed. The Current Subscribers section contains the list of current subscribers of the Change Data Capture system.
Select the subscriber you want to remove from the Current Subscriber section and use the buttons to move the subscriber to the section titled Subscribers to remove.
Click OK.
The Log window displays the details of the action being performed. Check this log to verify that the Unsubscribe action succeeded.
Extending the Change Data Capture Window
Use the "Extend Window" action to extend the subscription window to receive a new set of change data. To extend the window and receive the latest changed data, right-click the module or table in the Projects Navigator, select Change Data Capture, and then Extend Window. Oracle Warehouse Builder displays a prompt asking to extend the window. Click Yes.
After subscribers consume the change data that they subscribed to, use the "Purge Data" action to remove the change data from the capture tables. To purge capture data, right-click the module or table in the Projects Navigator, select Change Data Capture, and then Purge Data. Oracle Warehouse Builder displays a prompt asking to purge all capture data. Click Yes.
The "Lock Subscriber" operation enables you to lock a subscriber so that a subscriber-specific snapshot of the changes in the consistency window can be taken. The snapshot includes all the changes within the consistency window that have not yet been consumed by the subscriber.
To lock a subscriber:
In the Projects Navigator, right-click the data object or module from which you want to lock a subscriber, select Change Data Capture, then Lock Subscriber.
The Lock Subscriber dialog box is displayed. The Current Subscribers section contains the list of current subscribers of the Change Data Capture system.
Select the subscriber you want to lock from the section titled Current Subscriber and use the buttons to move the subscriber to the section titled Subscribers to lock.
Click OK.
The Log window displays the details of the action being performed. Check this log to verify that the Lock Subscriber action succeeded.
Use the "Unlock Subscriber" action to commit the changes that where locked during the Lock Subscriber operation for the subscriber.
To unlock a subscriber:
In the Projects Navigator, right-click the data object or module from which you want to unlock a subscriber, select Change Data Capture, then Lock Subscriber.
The Unlock Subscriber dialog box is displayed. The Current Subscribers section contains the list of current subscribers of the Change Data Capture system.
Select the subscriber you want to unlock from the section titled Current Subscriber and use the buttons to move the subscriber to the section titled Subscribers to lock.
Click OK.
The Log window displays the details of the action being performed. Check this log to verify that the Unlock Subscriber action succeeded.
Control Code Templates (Control CTs) enable you to maintain data integrity by checking if the records in a data object are consistent with defined constraints. Use Control CTs when you want to ensure that data that violates constraints specified for a data object is not loaded into the data object.
The constraints checked by a Control CT are Check constraints, Primary Key, Alternate Key, and Not Null.
Use Control CTs to check the following:
Consistency of existing data
Set the STATIC_CONTROL property to True to check the data currently in the data object.
Consistency of the incoming data, before loading the records to a target.
Set the FLOW_CONTROL property to True. The Control CT simulates the constraints of the target data object on the resulting flow before writing to the target.
Control CTs can check either an existing table or the temporary table created by an Integration CT.
A Control CT accepts a set of constraints and the name of the table to check. It either creates an error table to which all rejected records are written or removes the erroneous records from the checked result set.
In both cases, a Control CT usually performs the following tasks:
Creates the error table. The error table contains the same columns as the target table and additional columns to trace error messages, check origin, and check date.
Isolates the erroneous records in the error table for each primary key, alternate key, foreign key, condition, and mandatory column that must be checked.
If required, remove erroneous records from the table that has been checked.
Control CTs can operate in the following modes:
STATIC_CONTROL
The Control CT reads the constraints of the table and checks them against the data of the table. Records that do not match the constraints are written to the error table.
FLOW_CONTROL
The Control CT reads the constraints of the target table and checks these constraints against the data contained in the "I$" flow table of the staging area. Records that violate these constraints are written to the error table.
Employee data is stored in a file called EMP.dat. You must load this data into the target table EMP_TGT. During the load, any records that violate constraints defined on the target table are written to the error table associated with the target table.
The target table exists in an Oracle module called WH_TGT.
Checking data constraints using Control CTs includes the following steps:
Because the source is a flat file, you create a flat file module in the Design Center and import the flat file into this module.
To create a source module and import the source flat file:
In the Projects Navigator, right-click the Files node and select New Flat File Module.
The Create Module Wizard is displayed. Use this wizard to create a flat file module.
For more information about creating flat file modules, see Oracle Warehouse Builder Sources and Targets Guide.
Right-click the flat file module that you created and select New File.
The Create Flat File Wizard is displayed. Use this wizard to define and sample the source flat file.
For more information about creating flat files and sampling them, see Oracle Warehouse Builder Sources and Targets Guide.
If you have not done so, create a template mapping module to contain the CT mapping that performs the data integrity check.
Ensure that you set the location details of this mapping module to the Agent to which the mapping must be deployed.
This example uses a mapping module called CKM_MAP_MOD that is associated with the DEFAULT_AGENT location. This location points to the OC4J server installed with Oracle Warehouse Builder.
Create a CT mapping that contains the logic for extracting, checking, and loading data.
In this example, create a CT mapping called EMP_LOAD_CKM_MAP.
Drag and drop the source file from the source File source module onto the Mapping Editor canvas.
In this example, drag and drop the file EMP.dat from the File module onto the canvas.
Drag and drop the target table onto the canvas.
In this example, drag and drop the EMP_TGT operator onto the canvas.
The Table operator properties, in the Property Inspector, contain a node called Control CT. All existing constraints and data rules are displayed in the properties under this section. Use the properties in this group to define how data rules and integrity constraints should be applied.
Map the source attributes to the corresponding target attributes.
In the Execution View of the mapping, perform the following tasks:
Create an execution unit for Flat File operator and associate this execution unit with the LCT_FILE_TO_ORACLE_EXTER_TABLE code template.
Create an execution unit containing the target table. Associate this execution unit with the CCT_ORACLE code template.
Validate and generate the CT mapping. In the Projects Navigator, right-click the CT mapping and select Generate.
Deploy the CT mapping. In the Projects Navigator, right-click the CT mapping and select Deploy.
Run the CT mapping. In the Projects Navigator, right-click the CT mapping and select Start.
The records that violate constraints defined on the EMP_TGT table are not loaded into the target. These records are written to the error table associated with the target table.
Oracle Target CTs provide a method for using operators that are otherwise only supported in Oracle Warehouse Builder PL/SQL mappings. You can use these operators to define your data transformation, create an execution unit containing these transformation operators, and then associate the execution unit with an Oracle Target CT.
You want to aggregate source data available in two different sources and then load it into the target table. The first source is an Oracle module that contains the source tables CUSTOMERS, TIMES, and SALES. The second source is an XML module that contains the tables CHANNEL and COUNTRY.
The transformation required on the source data is to join data from all the source tables, aggregate it, and then load the aggregated data into the target table SUMMARY_SALES. Use the Joiner operator to join data from the source tables. The aggregation is performed using the Aggregator operator that leverages the Oracle Database SQL function CUBE. The summarized data is loaded into the target table.
Steps to Transform Source Data Using Oracle Target CTs
Transforming source data using Oracle Target CTS involves the following tasks:
In the Projects Navigator, create a source module and its associated location. Import the source objects into this module.
In this example, create an XML module that represents the XML source data and import the CHANNEL and COUNTRY tables. The location associated with this XML module should point to the XML source. Create an Oracle module whose location points to the SH sample schema in the Oracle Database. Import the CUSTOMERS, TIMES, and SALES tables into this module.
For more information about creating modules, see Oracle Warehouse Builder Sources and Targets Guide.
If you have not done so, create an Oracle module to store the target table.
Under this Oracle module, create the target table that stores the transformed data. Right-click the Tables node, select New Table and use the Table Editor to define the table.
Generate the target table by right-clicking the table name and selecting Generate. Rectify generation errors, if any.
Deploy the target table by right-clicking the table name and selecting Deploy.
In this example, the module WH_TGT contains the target table SUMMARY_SALES.
If you have not done so, create a template mapping module to contain the CT mapping that performs the required data transformation.
Ensure that you set the location details of this mapping module to the agent to which the mapping must be deployed.
In this example, a mapping module called ETL_MAP_MOD is associated with the DEFAULT_AGENT location. This location points to the OC4J server installed with Oracle Warehouse Builder.
Create a CT mapping to contain the required ETL logic for extracting, transforming, and loading data.
In this example, create a mapping called LOAD_SUMMARY_SALES_MAP.
Drag and drop the source tables onto the Mapping Editor canvas.
In this example, drag and drop the CHANNEL and COUNTRY tables from the XML source module and the CUSTOMERS, TIMES, and SALES tables from the Oracle module.
Drag and drop the operators that you must use to perform the required data transformation. Connect the operator attributes.
In this example, you add the following operators:
A Joiner operator to join the data in the source tables. Set the Join Condition property for the Joiner operator to define how the source tables should be joined. In this example, you use the columns that are common between a pair of tables to join data from those tables.
An Aggregator operator to aggregate the output of the Joiner operator. Data is aggregated based on the CHANNEL_DESC and COUNTRY_ISO_CODE attributes and the SQL function CUBE is leveraged to perform aggregation.
Thus, in the Group by clause of the Aggregator operator, specify the following:
CUBE(INGRP1.CHANNEL_DESC,INGRP1.COUNTRY_ISO_CODE)
Drag and drop the target table onto the canvas.
In this example, drag and drop the SUMMARY_SALES table onto the canvas.
Create the data flows between the source and transformation operators. Map the transformed output to the target table.
In this example, the tables CHANNEL, CUSTOMERS, COUNTRY, TIMES, and SALES are mapped to the Input groups of the Joiner operator. The Output group of the Joiner operator is mapped to the Aggregator operator. The output of the Aggregator operator is mapped to the target table SUMMARY_SALES.
In the Execution View of the CT mapping, create the execution units required to perform the data transformation.
Your CT mapping should look like the one in Figure 7-6.
In this example, perform the following:
Create an execution unit for the CHANNEL table. Associate this execution unit with the LCT_SQL_TO_SQL code template.
Create an execution unit for the COUNTRY table. Associate this execution unit with the LCT_SQL_TO_SQL code template.
Create an execution unit containing the tables CUSTOMERS, SALES, and TIMES, the Joiner operator, the Aggregator operator, and the SUMMARY_SALES table. Associate this execution unit with the Oracle Target CT DEFAULT_ORACLE_TARGET_CT.
Validate and generate the CT mapping. In the Projects Navigator, right-click the CT mapping and select Generate.
Deploy the CT mapping. In the Projects Navigator, right-click the CT mapping and select Deploy.
Run the CT mapping to extract data from the XML and Oracle source, transform it, and load it into the Oracle target table. In the Projects Navigator, right-click the CT mapping and select Start.
Figure 7-6 displays the Execution View of the CT mapping that enables you to perform the required data transformation using Oracle Target CTs.
Figure 7-6 Mapping That Uses Oracle Target CTs to Transform Source Data
You can use code templates to extract data from heterogeneous databases such as SQL Server, DB2, and Teradata. The code templates used to perform the data transfer depends on the source and target database.
Oracle Warehouse Builder provides a set of code templates that you can use to transfer data between different databases. These code templates are located in the BUILT_IN_CT node under the Public Code Templates node of the Globals Navigator. Each code template performs a certain set of tasks on a certain platform.
The tables ORDERS and ORDER_DETAILS are stored in an IBM DB2 database. You must extract data from these two tables, transform it, and store it in a table called ORDERS_AGG_CUST in an Oracle database. The transformation consists of joining the data in these two tables and then aggregating the data for each customer.
Before You Extract Data from IBM DB2
Ensure that you have the drivers required to access an IBM DB2 database. The files that you need are db2jcc.jar and db2jcc_license_cu.jar. Copy these files to the OWB_HOME/owb/lib/ext directory.
In the script that starts the CCA, add the statement that loads the required libraries for the DB2 driver.
On UNIX, add the following statement to OWB_HOME/owb/bin/unix/ccastart:
-Dapi.ext.dirs=$OWB_HOME/owb/lib/ext
On Windows, add the following statement to OWB_HOME/owb/bin/win32/ccastart.bat:
-Dapi.ext.dirs=%OWB_HOME%\owb\lib\ext
See Also:
Oracle Warehouse Builder Sources and Targets Guide for more information about modifying the CCA start script.To extract data from IBM DB2, transform the data, and then load the data into an Oracle Database:
In the Projects Navigator, create a DB2 module that represents the source data. The location associated with this module should point to the DB2 database containing the source objects.
In this example, create a DB2 module whose location points to the DB2 database containing the ORDERS and ORDER_DETAILS tables.
For more information about creating a DB2 module, see Oracle Warehouse Builder Sources and Targets Guide.
Use the following steps to create the target module and the target table.
If you have not done so, create an Oracle module to store the target table.
Under this Oracle module, create the target table that stores the transformed data. Right-click the Tables node, select New Table, and use the Table Editor to define the table.
Generate the target table by right-clicking the table name and selecting Generate. Rectify generation errors, if any.
Deploy the target table by right-clicking the table name and selecting Deploy.
In this example, the module WH_TGT contains the target table ORDERS_AGG_CUST.
Use the following steps to create the CT mapping that extracts data from DB2 tables, transforms it, and then loads it into and Oracle Database table.
If you have not done so, create a template mapping module to contain the CT mapping that performs the required ETL.
Ensure that you set the location details of this mapping module to the agent to which the mapping must be deployed.
In this example, a mapping module called ETL_MAP_MOD is associated with the DEFAULT_AGENT location. This location points to the OC4J server installed with Oracle Warehouse Builder.
Create a mapping to contain the required ETL logic for extracting, transforming, and loading data.
In this example, create a mapping called LOAD_DB2_TO_ORACLE_MAP.
Drag and drop the source tables from the DB2 source module onto the Mapping Editor canvas.
In this example, drag and drop the ORDERS and ORDER_DETAILS tables from the DB2 module source module.
Drag and drop the operators that you must use to perform the required data transformation. Connect the operator attributes.
In this example, you add the following operators:
A Joiner operator to join the data in the ORDERS and ORDER_DETAILS tables. Set the Join Condition property for the Joiner operator.
An Aggregator operator to aggregate the output of the Joiner operator. Aggregate the data based on the CUSTOMER_ID attribute.
Drag and drop the target table onto the canvas.
In this example, drag and drop the ORDERS_TGT operator onto the canvas.
Map the transformed output to the target table.
In the Execution View of the mapping, perform the following:
Create an execution unit for the ORDERS and ORDER_DETAILS operators. Associate this execution unit with the LCT_SQL_TO_ORACLE code template.
Create an execution unit containing the Joiner, Aggregator, and ORDERS_AGG_CUST table. Associate this execution unit with the ICT_ORACLE_INCR_UPD code template.
Validate and generate the CT mapping. In the Projects Navigator, right-click the CT mapping and select Generate.
Deploy the CT mapping. In the Projects Navigator, right-click the CT mapping and select Deploy.
Run the CT mapping to extract data from the source DB2 tables, transform it, and load it into the Oracle target table. In the Projects Navigator, right-click the CT mapping and select Start.
Figure 7-7 displays the Execution View of the mapping LOAD_DB2_TO_ORACLE_MAP.
Figure 7-7 Mapping to Extract Data from IBM DB2, Transform Data, and Load it into Oracle Database
|
Copyright © 2000, 2011, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|