| Oracle® Streams Extended Examples 11g Release 2 (11.2) E12862-05 |
|
|
Mobi · ePub |
| Oracle® Streams Extended Examples 11g Release 2 (11.2) E12862-05 |
|
|
Mobi · ePub |
This chapter illustrates an example of a simple single-source replication environment that can be constructed using Oracle Streams.
This chapter contains these topics:
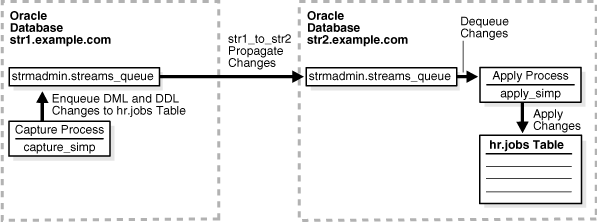
The example in this chapter illustrates using Oracle Streams to replicate data in one table between two databases. A capture process captures data manipulation language (DML) and data definition language (DDL) changes made to the jobs table in the hr schema at the str1.example.com Oracle database, and a propagation propagates these changes to the str2.example.com Oracle database. Next, an apply process applies these changes at the str2.example.com database. This example assumes that the hr.jobs table is read-only at the str2.example.com database.
Figure 1-1 provides an overview of the environment.
Figure 1-1 Simple Example that Shares Data from a Single Source Database
The following prerequisites must be completed before you begin the example in this chapter.
Set the following initialization parameters to the values indicated:
GLOBAL_NAMES: This parameter must be set to TRUE at each database that is participating in your Oracle Streams environment.
COMPATIBLE: This parameter must be set to 10.2.0 or higher at each database that is participating in your Oracle Streams environment.
STREAMS_POOL_SIZE: Optionally set this parameter to an appropriate value for each database in the environment. This parameter specifies the size of the Oracle Streams pool. The Oracle Streams pool stores messages in a buffered queue and is used for internal communications during parallel capture and apply. When the MEMORY_TARGET, MEMORY_MAX_TARGET, or SGA_TARGET initialization parameter is set to a nonzero value, the Oracle Streams pool size is managed automatically.
See Also:
Oracle Streams Replication Administrator's Guide for information about other initialization parameters that are important in an Oracle Streams environmentAny database producing changes that will be captured must be running in ARCHIVELOG mode. In this example, changes are produced at str1.example.com, and so str1.example.com must be running in ARCHIVELOG mode.
See Also:
Oracle Database Administrator's Guide for information about running a database inARCHIVELOG modeConfigure your network and Oracle Net so that the str1.example.com database can communicate with the str2.example.com database.
Create an Oracle Streams administrator at each database in the replication environment. In this example, the databases are str1.example.com and str2.example.com. This example assumes that the user name of the Oracle Streams administrator is strmadmin.
See Also:
Oracle Streams Replication Administrator's Guide for instructions about creating an Oracle Streams administratorComplete the following steps to create queues and database links for an Oracle Streams replication environment that includes two Oracle databases.
Note:
If you are viewing this document online, then you can copy the text from the "BEGINNING OF SCRIPT" line after this note to the next "END OF SCRIPT" line into a text editor and then edit the text to create a script for your environment. Run the script with SQL*Plus on a computer that can connect to all of the databases in the environment./************************* BEGINNING OF SCRIPT ******************************
Run SET ECHO ON and specify the spool file for the script. Check the spool file for errors after you run this script.
*/ SET ECHO ON SPOOL streams_setup_simple.out /*
Connect as the Oracle Streams administrator at the database where you want to capture changes. In this example, that database is str1.example.com.
*/ CONNECT strmadmin@str1.example.com /*
Run the SET_UP_QUEUE procedure to create a queue named streams_queue at str1.example.com. This queue will function as the ANYDATA queue by holding the captured changes that will be propagated to other databases.
Running the SET_UP_QUEUE procedure performs the following actions:
Creates a queue table named streams_queue_table. This queue table is owned by the Oracle Streams administrator (strmadmin) and uses the default storage of this user.
Creates a queue named streams_queue owned by the Oracle Streams administrator (strmadmin).
Starts the queue.
*/ EXEC DBMS_STREAMS_ADM.SET_UP_QUEUE(); /*
Create the database link from the database where changes are captured to the database where changes are propagated. In this example, the database where changes are captured is str1.example.com, and these changes are propagated to str2.example.com.
*/ ACCEPT password PROMPT 'Enter password for user: ' HIDE CREATE DATABASE LINK str2.example.com CONNECT TO strmadmin IDENTIFIED BY &password USING 'str2.example.com'; /*
Connect as the Oracle Streams administrator at str2.example.com.
*/ CONNECT strmadmin@str2.example.com /*
Run the SET_UP_QUEUE procedure to create a queue named streams_queue at str2.example.com. This queue will function as the ANYDATA queue by holding the changes that will be applied at this database.
Running the SET_UP_QUEUE procedure performs the following actions:
Creates a queue table named streams_queue_table. This queue table is owned by the Oracle Streams administrator (strmadmin) and uses the default storage of this user.
Creates a queue named streams_queue owned by the Oracle Streams administrator (strmadmin).
Starts the queue.
*/ EXEC DBMS_STREAMS_ADM.SET_UP_QUEUE(); /*
Check the streams_setup_simple.out spool file to ensure that all actions finished successfully after this script is completed.
*/ SET ECHO OFF SPOOL OFF /*************************** END OF SCRIPT ******************************/
Complete the following steps to specify the capture, propagation, and apply definitions for the hr.jobs table using the DBMS_STEAMS_ADM package.
Note:
If you are viewing this document online, then you can copy the text from the "BEGINNING OF SCRIPT" line after this note to the next "END OF SCRIPT" line into a text editor and then edit the text to create a script for your environment. Run the script with SQL*Plus on a computer that can connect to all of the databases in the environment./************************* BEGINNING OF SCRIPT ******************************
Run SET ECHO ON and specify the spool file for the script. Check the spool file for errors after you run this script.
*/ SET ECHO ON SPOOL streams_share_jobs.out /*
Connect to str1.example.com as the strmadmin user.
*/ CONNECT strmadmin@str1.example.com /*
Configure and schedule propagation of DML and DDL changes to the hr.jobs table from the queue at str1.example.com to the queue at str2.example.com.
*/
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_PROPAGATION_RULES(
table_name => 'hr.jobs',
streams_name => 'str1_to_str2',
source_queue_name => 'strmadmin.streams_queue',
destination_queue_name => 'strmadmin.streams_queue@str2.example.com',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'str1.example.com',
inclusion_rule => TRUE,
queue_to_queue => TRUE);
END;
/
/*
Configure the capture process to capture changes to the hr.jobs table at str1.example.com. This step specifies that changes to this table are captured by the capture process and enqueued into the specified queue.
This step also prepares the hr.jobs table for instantiation and enables supplemental logging for any primary key, unique key, bitmap index, and foreign key columns in this table. Supplemental logging places additional information in the redo log for changes made to tables. The apply process needs this extra information to perform certain operations, such as unique row identification and conflict resolution. Because str1.example.com is the only database where changes are captured in this environment, it is the only database where supplemental logging must be enabled for the hr.jobs table.
*/
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_RULES(
table_name => 'hr.jobs',
streams_type => 'capture',
streams_name => 'capture_simp',
queue_name => 'strmadmin.streams_queue',
include_dml => TRUE,
include_ddl => TRUE,
inclusion_rule => TRUE);
END;
/
/*
This example assumes that the hr.jobs table exists at both the str1.example.com database and the str2.example.com database, and that this table is synchronized at these databases. Because the hr.jobs table already exists at str2.example.com, this example uses the GET_SYSTEM_CHANGE_NUMBER function in the DBMS_FLASHBACK package at str1.example.com to obtain the current SCN for the source database. This SCN is used at str2.example.com to run the SET_TABLE_INSTANTIATION_SCN procedure in the DBMS_APPLY_ADM package. Running this procedure sets the instantiation SCN for the hr.jobs table at str2.example.com.
The SET_TABLE_INSTANTIATION_SCN procedure controls which LCRs for a table are ignored by an apply process and which LCRs for a table are applied by an apply process. If the commit SCN of an LCR for a table from a source database is less than or equal to the instantiation SCN for that table at a destination database, then the apply process at the destination database discards the LCR. Otherwise, the apply process applies the LCR.
In this example, both of the apply process at str2.example.com will apply transactions to the hr.jobs table with SCNs that were committed after SCN obtained in this step.
Note:
This example assumes that the contents of thehr.jobs table at str1.example.com and str2.example.com are consistent when you complete this step. Ensure that there is no activity on this table while the instantiation SCN is being set. You might want to lock the table at each database while you complete this step to ensure consistency. If the table does not exist at the destination database, then you can use export/import for instantiation.
*/
DECLARE
iscn NUMBER; -- Variable to hold instantiation SCN value
BEGIN
iscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER();
DBMS_APPLY_ADM.SET_TABLE_INSTANTIATION_SCN@STR2.EXAMPLE.COM(
source_object_name => 'hr.jobs',
source_database_name => 'str1.example.com',
instantiation_scn => iscn);
END;
/
/*
Connect to str2.example.com as the strmadmin user.
*/ CONNECT strmadmin@str2.example.com /*
Configure str2.example.com to apply changes to the hr.jobs table.
*/
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_RULES(
table_name => 'hr.jobs',
streams_type => 'apply',
streams_name => 'apply_simp',
queue_name => 'strmadmin.streams_queue',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'str1.example.com',
inclusion_rule => TRUE);
END;
/
/*
Set the disable_on_error parameter to n so that the apply process will not be disabled if it encounters an error, and start the apply process at str2.example.com.
*/
BEGIN
DBMS_APPLY_ADM.SET_PARAMETER(
apply_name => 'apply_simp',
parameter => 'disable_on_error',
value => 'N');
END;
/
BEGIN
DBMS_APPLY_ADM.START_APPLY(
apply_name => 'apply_simp');
END;
/
/*
Connect to str1.example.com as the strmadmin user.
*/ CONNECT strmadmin@str1.example.com /*
Start the capture process at str1.example.com.
*/
BEGIN
DBMS_CAPTURE_ADM.START_CAPTURE(
capture_name => 'capture_simp');
END;
/
/*
Check the streams_share_jobs.out spool file to ensure that all actions finished successfully after this script is completed.
*/ SET ECHO OFF SPOOL OFF /*************************** END OF SCRIPT ******************************/
Complete the following steps to make DML and DDL changes to the hr.jobs table at str1.example.com and then confirm that the changes were captured at str1.example.com, propagated from str1.example.com to str2.example.com, and applied to the hr.jobs table at str2.example.com.
Make the following changes to the hr.jobs table.
CONNECT hr@str1.example.com
Enter password: password
UPDATE hr.jobs SET max_salary=9545 WHERE job_id='PR_REP';
COMMIT;
ALTER TABLE hr.jobs ADD(duties VARCHAR2(4000));
After some time passes to allow for capture, propagation, and apply of the changes performed in the previous step, run the following query to confirm that the UPDATE change was propagated and applied at str2.example.com:
CONNECT hr@str2.example.com
Enter password: password
SELECT * FROM hr.jobs WHERE job_id='PR_REP';
The value in the max_salary column should be 9545.
Next, describe the hr.jobs table to confirm that the ALTER TABLE change was propagated and applied at str2.example.com:
DESC hr.jobs
The duties column should be the last column.
|
Copyright © 2008, 2013, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|