| Oracle® Warehouse Builder Data Modeling, ETL, and Data Quality Guide 11g Release 2 (11.2) E10935-05 |
|
|
PDF · Mobi · ePub |
| Oracle® Warehouse Builder Data Modeling, ETL, and Data Quality Guide 11g Release 2 (11.2) E10935-05 |
|
|
PDF · Mobi · ePub |
After you create data object definitions in Oracle Warehouse Builder, you can design extract, transform, and load (ETL) operations that move data from sources to targets. In Oracle Warehouse Builder, you design these operations in a mapping.
You can also use the Mapping Debugger to debug data flows created in mappings.
This chapter contains the following topics:
"Steps to Perform Extraction, Transformation, and Loading (ETL) Using Mappings"
"Example: Using the Mapping Editor to Create Staging Area Tables"
"Locating Operators, Groups, and Attributes in Mappings and Pluggable Mappings"
A mapping is an Oracle Warehouse Builder object that you use to perform extract, transform, and load (ETL). A mapping defines the data flows for moving data from disparate sources to your data warehouse.
You can extract data from sources that include, but are not limited to, flat files, Oracle databases, SAP, or other heterogeneous databases such as SQL Server and IBM DB2. Use mapping operators or transformations to transform the data, according to your requirements, and to load the transformed data into the target objects.
See Also:
"Defining Mappings" for information about defining mappings.
Chapter 26, "Data Flow Operators" for information about mapping transformation operators and how to use them.
Chapter 28, "Oracle Warehouse BuilderTransformations Reference" for more information about predefined Oracle Warehouse Builder transformations.
As with other Oracle Warehouse Builder objects, after you define a mapping, you must validate, generate, and deploy the mapping. Once you define and deploy a mapping, you can run the mapping using the Control Center Manager, schedule it for later execution, or incorporate it in a process flow.
See Also:
"Deploying Objects" for information about deploying mappings.
"Scheduling ETL Jobs" for information about scheduling ETL objects.
"Designing Process Flows" for information about defining process flows.
Oracle Warehouse Builder mappings can be classified according to the supported data extraction technologies used in the mapping. The code generated by Oracle Warehouse Builder depends on the sources and targets used in the mapping.
The different types of mappings include:
Oracle Warehouse Builder generates ETL code in different languages for the different mapping types. The generated code is deployed to a target location, where it runs. By selecting the appropriate data extraction technology for each mapping, you can access a wide range of data source types, and satisfy different technical requirements, such as performance and security.
Note:
Mappings other than PL/SQL mappings do not support all Oracle Warehouse Builder data transformation capabilities. If you use one of the non-PL/SQL mapping types, you must perform complex transformations supported only in PL/SQL mappings, use the non-PL/SQL mapping to load a staging table, and then use a PL/SQL mapping to perform the rest of the required transformation.PL/SQL mappings are the default mapping type in Oracle Warehouse Builder and is necessary in most situations. For PL/SQL mappings, Oracle Warehouse Builder generates PL/SQL code that is deployed to an Oracle Database location, where it runs.
Data extraction from other locations is primarily performed through database links to other Oracle Databases or through Oracle Database gateways for non-Oracle data sources. PL/SQL mappings offer the full range of Oracle Warehouse Builder data transformation capabilities.
For SQL*Loader mappings, Oracle Warehouse Builder generates SQL*Loader control files. The control file is deployed to the target database, where SQL*Loader runs, loading the source data into the database.
Note:
SQL*Loader mappings support only a subset of transformations available in PL/SQL mappings. For information about the limitations on the transformations available in SQL*Loader mappings, see Chapter 26, "Data Flow Operators".ABAP mappings are the only supported method of extracting data from SAP R/3 source systems. For ABAP mappings, Oracle Warehouse Builder generates ABAP code. This code can then be deployed to an SAP R/3 instance automatically or manually by an administrator, depending upon security and other administrative requirements specific to the SAP environment. The ABAP code runs, generating a flat file as output, which is then transparently moved to the target database system and loaded into the Oracle target database.
Note:
ABAP mappings support only a subset of transformations available in PL/SQL mappings. For information about the limitations on the transformations available in ABAP mappings, see Chapter 26, "Data Flow Operators".Code templates provide a general framework for implementing data extraction, movement, and loading mechanisms. For Code Template (CT) mappings, Oracle Warehouse Builder generates data extraction or other mapping code based on the contents of a code template. This code is then deployed to a remote agent on a target system, where it runs. The technology used to load data into the target database depends upon the contents of the code template. Oracle Warehouse Builder provides a collection of code templates that implement common data extraction methods. Other code templates use bulk data extraction and loading tools for faster and more flexible data movement.
Choose CT mappings when you must:
Access a data source without using Oracle Database gateways or ODBC, or you have a specific need for JDBC connectivity. Oracle Warehouse Builder provides code templates that support access to any JDBC data source or target.
Load data from an XML source file.
Perform bulk data unloads and loads for maximum data movement performance. Oracle Warehouse Builder provides code templates to support bulk data movement from some common databases. You can write your own code templates for sources not supported by Oracle Warehouse Builder-provided code templates.
Implement ETL processes where data moves from a non-Oracle database source directly to a non-Oracle database target. For example, you can define an ETL process that extracts from an IBM DB2 source and loads a Microsoft SQL Server target directly.
Implement new data integration patterns without requiring changes to Oracle Warehouse Builder itself. Code templates provide maximum data integration flexibility for business and technical requirements beyond those supported by Oracle Warehouse Builder out of the box.
Note:
CT mappings support only a subset of transformations available in PL/SQL mappings. For information about the limitations on the transformations available in CT mappings, see "Mapping Operators Only Supported in Oracle Target CT Execution Units".Chunking enables you to parallelize the processing of large updates by dividing the source data in a mapping into smaller chunks. The chunks are defined by user-defined chunking criteria. At run time, the chunks are run in parallel and each chunk is loaded separately into the target object.
Note:
Chunking can be performed for PL/SQL mappings only.When you define chunking, Oracle Warehouse Builder creates a chunking task in the target schema at deployment time. During execution, the DML represented by each chunk is run in parallel.
For a PL/SQL mapping that uses chunking, you can configure the following parameters using the Mapping Configuration Editor:
Code Generation Parameters
You can set code generation parameters for chunking either while defining the mapping or later, by editing the mapping. Use the Mapping Configuration Editor to set code generation parameters. These parameters are used to generate the code required to run the logic defined in the mapping.
Runtime Parameters
Runtime chunking parameters can be configured at design-time, by using the Mapping Configuration Editor, or while executing the mapping. When you set run-time chunking parameters both at design-time and execution time, the values set at execution time override the ones defined at design-time.
See Also:
Oracle Warehouse Builder enables you to perform the following types of chunking:
Serial chunking
Serial chunking is useful in scenarios where it is not possible to process all source data in one set. The primary use case for serial chunking is loading Type 2 SCDs, where multiple updates to a single target row must be processed separately.
To configure serial chunking parameters for a mapping, use the "SCD Updates" and "Runtime Parameters" nodes in the Mapping Configuration Editor.
Parallel chunking
Parallel chunking enables you to update table data in parallel with incremental commit in two high-level steps. In the first step, the rows in a table are grouped into smaller sized chunks. In the second step, a user-specified statement is run in parallel on these chunks and a commit is issued after the processing is complete.
Parallel chunking is used for parallel DML operations. To configure parallel chunking parameters for a mapping, use the "Chunking Options" and "Runtime Parameters" nodes in the Mapping Configuration Editor.
You can perform parallel chunking in one of the following ways:
Chunking by number column
The data in the source table is divided into chunks by defining the size of each chunk.
Chunking by ROWID
The data in the source table is divided into chunks based on the ROWID value of each row in the table.
Chunking by SQL statement
Uses a SQL statement to return two columns that define the range of each chunk, either by ROWID or column number.
Operators are the basic design elements for mapping. Operators are used to represent sources and targets in the data flow, and to define the method to transform the data from source to target.
See Also:
Oracle Warehouse Builder Concepts for more information about operators.
The Mapping Editor is built around the Mapping Editor canvas, on which the operators and connections in a mapping are displayed graphically and can be manipulated. Several other Design Center panels are context-sensitive and display mapping-related items when a mapping is open in the Mapping Editor. These include the following:
Component Palette: Displays operators that you can use in a mapping. Select an object, either from the canvas or Projects Navigator, and Oracle Warehouse Builder displays the object properties in the Property Inspector.
Use the filter at the top of the palette to limit the display of operators to a particular type. For example, select Transformation Operators in the filter to display only operators that transform data.
Structure View: Displays a hierarchical view of the operators, attribute groups, and attributes in the mapping.
Bird's Eye View: Displays the layout of the entire mapping. Enables you to move the view of the canvas with a single mouse dragging operation. You can thus reposition your view of the canvas without using the scroll bars.
The Bird's Eye View displays a miniature version of the entire canvas. It contains a blue box that represents the portion of the canvas that is currently in focus. For mappings that span more than the canvas size, click the blue box and drag it to the portion of the canvas to focus on.
Property Inspector: Displays the properties of the mapping, operators, attribute groups, or attributes currently selected in the Mapping Editor canvas.
Mapping Debug Toolbar: Displays icons for each command used in debugging mappings. When you are debugging mappings, the Debug toolbar is displayed at the top of the Mapping Editor canvas.
Diagram Toolbar: Displays icons for each command used to navigate the canvas and change the magnification of objects on the canvas.
The Mapping Editor canvas is the area that you use to graphically design your mappings. Mappings define how data extracted from the source is transformed before being loaded into the targets.
The Mapping Editor canvas contains two tabs: "Logical View" and "Execution View".
The Logical view of the Mapping Editor enables you to design the data flows that define your mapping. You first drag and drop operators representing the source objects, the target objects, and the transformations. Next you establish a data flow between these operators that represents the data transformation by drawing data flow connections between operators.
See Also:
"Adding Operators to Mappings" for information about adding source, target, and transformation operators
"Connecting Operators, Groups, and Attributes" for information about connecting operators in the mapping
Use the Execution View of the Mapping Editor to define execution units for Code Template (CT) mappings. The Execution View is available only when you create CT mappings.
An execution unit represents the set of related tasks that are to be performed using a code template. A code template contains the logic to perform a particular ETL processing on a particular platform during run time, such as moving data between two Oracle Database instances, or unloading data from a DB2 database into a flat file. An execution unit can be implemented by a single generated script such as a PL/SQL package or by a code template.
Execution units enable you to break up your mapping execution into smaller related units. Each execution unit may be associated with a code template that contains the template to perform the required data integration task on the specified platform. An execution unit can be implemented by a single generated script such as a PL/SQL package or by a code template.
The Execution View tab of the Mapping Editor displays the operators and data flows from the Logical View in an iconized form. You cannot edit operators or create data flows in the Execution View. You can only perform these tasks using the Logical View.
The contents of the Execution Unit view are based on the selected configuration. Thus, you can use different code templates for different configurations. For example, if you have two configurations, Development and QA, you can use one set of code templates for Development and another for QA.
When you select the Execution View tab, the Execution menu is displayed in the Design Center and an Execution toolbar is displayed at the top of the Mapping Editor canvas. Use the options in the Execution menu or the Execution toolbar to:
Create and delete execution units
Define default execution units
Associate code templates with execution units
You can control how the editor displays the mappings on the canvas by selecting Graph from the menu bar and then selecting Options. Oracle Warehouse Builder displays the Options dialog box that enables you to set display options for the Mapping Editor canvas.
The Options dialog box contains the following options. You can either select or deselect any of these options.
Input Connector: Select this option to display an arrow icon on the left of attributes that you can use as input attributes.
Key Indicator: Select this option to display a key icon to the left of the attribute that is a foreign key attribute in an operator.
Data Type: Select this option to display the data type of attributes in all operators.
Output Connector: Select this option to display an arrow icon on the right of attributes that you can use as output attributes.
Enable Horizontal Scrolling: Select this option to enable horizontal scrolling for operators.
Automatic Layout: Select this option to use an automatic layout for the mapping.
This section describes the creation of a basic PL/SQL mapping that loads data from a source table to a target table. The purpose of this example is to illustrate the use of mappings and help you understand the objective achieved by creating mappings. Because the example is very basic, it does not perform any transformation on the source data. However, in a typical data warehousing environment, transformations are an integral part of mappings.
The SALES table contains the sales data of an organization. This table is located in the SRC schema in an Oracle Database. You must load this sales data into the target table SALES_TGT, located in the TGT schema in your data warehouse. Both source and target tables contain the same number of columns with the same column names.
You define a PL/SQL mapping that defines how data from the source table is loaded into the target table.
To define a mapping that loads data from a source Oracle Database table to a target Oracle Database table:
If you have not done so, in the Projects Navigator, create an Oracle module corresponding to the source. This module, called SRC_MOD, is associated with a location SRC_LOC that corresponds to the SRC schema. Also, import the SALES table into the SRC_MOD module.
In the Projects Navigator, create the target module whose location corresponds to the data warehouse schema in which your target table is located.
Create the WH_TGT Oracle module, with its associated location TGT_LOC corresponding with the TGT schema.
In the Projects Navigator, expand the WH_TGT module.
Right-click the Mappings node and select New Mapping.
The Create Mapping dialog box is displayed.
Provide the following information about the mapping and click OK.
Name: Enter the name of the mapping.
Description: Enter an optional description for the mapping.
The Mapping Editor is displayed. Use this interface to define the data flow between source and target objects.
Expand the Tables node under the SRC_MOD module.
Drag and drop the SALES table from the Projects Navigator to the Mapping Editor canvas.
The operator representing the SALES table is added to the canvas. The operator name appears in the upper-left corner. Below the operator name is the name of the group. The name and number of groups depend on the type of operator. Table operators have one group called INOUTGRP1. Below the group, the attribute names and their data types are listed.
From the Projects Navigator, drag and drop the SALES_TGT table, under the WH_TGT module, to the Mapping Editor canvas.
The operator representing the SALES_TGT table is added to the canvas. You can view each attribute name and data type.
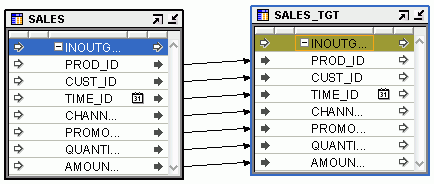
Connect the attributes of the source table SALES to the corresponding attributes in the target table SALES_TGT.
To connect all attributes in the operator, click and hold down your left mouse button on the group INOUTGRP1 of the SALES operator, drag, and release the mouse button on the group INOUTGRP1 of the SALES_TGT operator.
The Connect dialog box is displayed.
See Also:
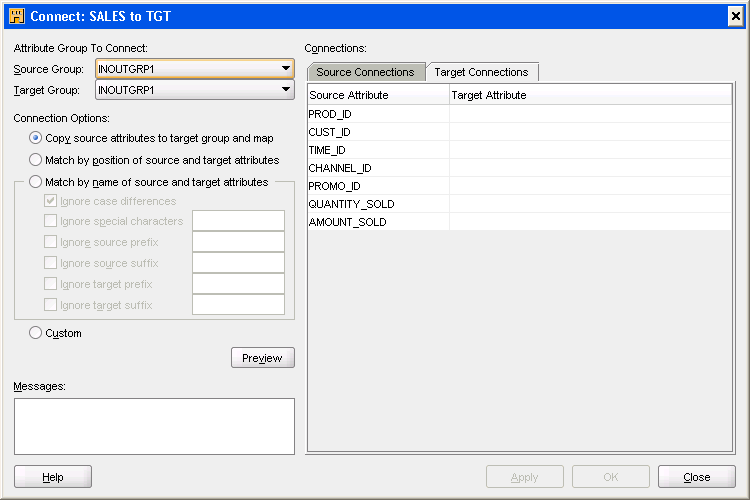
"Connecting Operators, Groups, and Attributes" for details about connecting attributes.In the Connection Options section, select Match by name of source and target operators and click Preview.
The Connections section displays the association between the source and target attributes. The Source Attribute column lists the source table attributes and the Target Attribute column lists the attributes in the target table to which the source attributes are loaded.
Click OK to close the Connect dialog box.
The completed mapping looks as shown in Figure 5-1.
Figure 5-1 Mapping that Loads Data from Source Table to Target Table
Validate the mapping by selecting the mapping in the Projects Navigator and clicking Validate. Or, right-click the mapping in the Projects Navigator and select Validate.
Validation runs tests to verify the metadata definitions and configuration parameters in the mapping. Resolve validation errors, if any.
Generate the mapping by selecting the mapping in the Projects Navigator and clicking Generate. Or, right-click the mapping in the Projects Navigator and select Generate.
Generation creates the scripts that must be used to create the mapping in the target schema. Resolve generation errors, if any, and regenerate the mapping. Oracle Warehouse Builder creates the scripts for this mapping.
You have now defined a mapping that extracts data from a source table called SALES and loads it into a target table called SALES_TGT. The metadata for this mapping is stored in the repository. And, after successful generation, the scripts to create this mapping in the target schema are ready.
To perform ETL and transfer the data from the source table to the target table, you must first deploy the mapping to the target schema, and then run the mapping as defined in "Starting ETL Jobs".
First verify that your project contains a target module or a Template Mappings module with a defined location. You must create your mapping in this module.
Also import any existing data you intend to use as sources or targets in the mapping.
To define mappings that perform ETL:
In the Projects Navigator, define the mapping that contains the logic for performing ETL.
See "Defining Mappings" for more information about defining mappings and "Creating Code Template (CT) Mappings" for information about creating CT mappings.
In the Mapping Editor, add the required operators to the mapping. Operators enable you to perform ETL.
See "Adding Operators to Mappings" for more information about adding operators.
Connect the operators in the mapping to define how data from the source objects should be transformed before loading it into the target objects.
See "Connecting Operators, Groups, and Attributes" for information about establishing connections between operators.
(Optional) Edit the operators in the mapping to set operator, group, or attribute properties. You must edit operators to specify how a certain transformation is to be performed. For example, if you use the Filter operator to restrict the rows loaded into the target, edit the Filter operator and specify the condition that is necessary to filter rows.
See "Editing Operators" for more information about editing operators in mappings.
Configure the mapping.
For PL/SQL mappings, see "Configuring Mappings". For CT mappings, see "Setting Options for Code Templates in Code Template Mappings".
Validate the mapping by right-clicking the mapping in the Projects Navigator and selecting Validate.
Validation verifies the metadata definitions and configuration parameters of the mapping to check if they conform to the rules defined by Oracle Warehouse Builder for mappings.
Generate the mapping by right-clicking the mapping in the Projects Navigator and selecting Generate.
Generation uses the metadata definitions and configuration settings to create the code that is used to create the mapping in the target schema.
When you generate a mapping, the generated code contains comments that help you identify the operator for which the code is generated. It enables you to debug errors that you may encounter when you deploy the mapping.
Deploy the mapping to the target schema to create the PL/SQL code generated for the mapping to the target schema.
For more information about deployment, see "Deploying Objects".
Run the mapping to extract data from the source table and load it into the target table.
For more information about executing ETL objects, see "Starting ETL Jobs".
After you design a mapping and generate its code, you can create a process flow or proceed directly with deployment followed by execution.
Use process flows to interrelate mappings. For example, you can design a process flow such that the completion of one mapping triggers an email notification and starts another mapping. For more information, see Chapter 8, "Designing Process Flows".
After you design mappings, generate code for them, and deploy them to their targets, you can:
Run the mappings immediately as described in "Starting ETL Jobs".
Schedule the mappings for later execution as described in "Scheduling ETL Jobs".
Create process flows, to orchestrate the execution of one or more mappings, along with other activities as described in "Designing Process Flows".
A mapping is an Oracle Warehouse Builder object that contains the metadata regarding the transformation performed by the mapping. The metadata includes details of the sources from which data is extracted, the targets into which the transformed data is loaded, and the settings used to perform these operations.
In the Projects Navigator, expand the project, the Databases node, the Oracle node, and then the Oracle module in which you want to define the mapping.
Right-click the Mappings node and select New Mapping.
Oracle Warehouse Builder opens the Create Mapping dialog box.
Enter a name and an optional description for the new mapping.
For rules on naming and describing mappings, see "Rules for Naming Mappings".
Click OK.
Oracle Warehouse Builder stores the definition for the mapping and inserts its name in the Projects Navigator. Oracle Warehouse Builder opens a Mapping Editor for the mapping and displays the name of the mapping in the title bar.
Steps to Open a Previously Created Mapping
In the Projects Navigator, expand the project, the Databases node, the Oracle node, and then the Oracle module in which the mapping is defined.
Expand the Mappings node.
Open the Mapping Editor in one of the following ways:
Double-click a mapping.
Select a mapping and then from the File menu, select Open.
Select a mapping and press Ctrl + O.
Oracle Warehouse Builder displays the Mapping Editor.
Note:
When you open a mapping that was created using OMB*Plus, although the mapping has multiple operators, it may appear to contain only one operator. To view all the operators, click Auto Layout on the toolbar.The rules for naming mappings depend on the naming mode that you select in the Naming Preferences section of the Preferences dialog box. Oracle Warehouse Builder maintains a business and a physical name for each object in the workspace. The business name is a unique descriptive name that makes sense to a business-level user of the data. The physical name is the name Oracle Warehouse Builder uses when generating code.
When you name objects while working in one naming mode, Oracle Warehouse Builder creates a default name for the other mode. Therefore, when working in the business name mode, if you assign a name to a mapping that includes mixed cases, special characters and spaces, Oracle Warehouse Builder creates a default physical name for you. For example, if you save a mapping with the business name My Mapping (refer to doc#12345), the default physical name is MY_MAPPING_REFER_TO_DOC#12345.
When you name or rename objects in the Mapping Editor, use the following naming rules.
Naming and Describing Mappings
In the physical naming mode, a mapping name can be from 1 to 30 alphanumeric characters, and blank spaces are not enabled. In the business naming mode, the limit is 200 characters and blank spaces and special characters are enabled. In both naming modes, the name should be unique across the project.
Note for scheduling mappings: If you intend to schedule the execution of the mapping, there is an additional consideration. For any ETL object to schedule, the limit is 25 characters for physical names and 1995 characters for business names. Follow this additional restriction to enable Oracle Warehouse Builder to append, to the mapping name, the suffix _job and other internal characters required for deployment and execution.
After you create the mapping definition, you can view its physical and business name in the Property Inspector.
Edit the description of the mapping as necessary. The description can be up to 4,000 alphanumeric characters and can contain blank spaces.
Rules for Naming Attributes and Groups
You can rename groups and attributes independent of their sources. Attribute and group names are logical. Although attribute names of the object are often the same as the attribute names of the operator to which they are bound, their properties remain independent of each other.
Business names for the operators must meet the following requirements:
The length of the operator name can be any string of 200 characters.
The operator name must be unique within its parent group. The parent group could be either a mapping or its parent pluggable mapping container.
Physical names for operators must meet the following requirements:
The length of the operator name must be between 1 and 30 characters.
The operator name must be unique within its parent group. The parent group could be either a mapping or its parent pluggable mapping container.
The operator name must conform to the syntax rules for basic elements as defined in the Oracle Database SQL Language Reference.
In addition to physical and business names, some operators also have bound names. Every operator associated with a workspace object has a bound name. During code generation, Oracle Warehouse Builder uses the bound name to reference the operator to its workspace object. Bound names have the following characteristics:
Bound names need not be unique.
Bound names must conform to the general Oracle Warehouse Builder physical naming rules, except if the object was imported and contains restricted characters such as spaces.
Typically, you do not change bound names directly. Instead, you change these by synchronizing with a workspace object outside the mapping.
In physical naming mode, when you modify the physical name of an operator attribute, Oracle Warehouse Builder propagates the new physical name as the bound name when you synchronize.
Binding is the process of associating an operator with an object in the workspace.For more information about binding and methods of binding, see "Binding" in Chapter 3, "Defining Dimensional Objects."
Operators enable you to perform data transformations. Some operators are bound to workspace objects while others are not. Many operators that represent built-in transformations (such as Joiner, Filter, and Aggregator) do not directly refer to underlying workspace objects, and therefore are not bound. Other operators, such as Table, View, Dimension, and Cube, do refer to objects in the workspace, and therefore can be bound.
As a general rule, when you add a data source or target operator such as a Table operator to a mapping, that operator refers to a table defined in the workspace, although it is a different object as the table itself. Source and target operators in mappings are said to be bound to underlying objects in the workspace. It is possible for multiple operators in a single mapping to be bound to the same underlying object. For example, to use a table EMP as a source for two different operations in a mapping, you can add two table operators named EMP_1 and EMP_2 to the mapping and bind them to the same underlying EMP table in the workspace.
To distinguish between the two versions of operators, this chapter refers to objects in the workspace either generically as workspace objects or specifically as workspace tables, workspace views, and so on. This chapter refers to operators in the mapping as Table operators, View operators, and so on. Therefore, when you add a dimension to a mapping, refer to the dimension in the mapping as the Dimension operator and refer to the dimension in the workspace as the workspace dimension.
Oracle Warehouse Builder maintains separate workspace objects for some operators. It enables you to work on these objects independently. You can modify the workspace object without affecting the logic of the mapping. After modification, you can decide how to synchronize the discrepancy between the workspace object and its corresponding operator. This provides maximum flexibility during your warehouse design.
For example, when you reimport a new metadata definition for the workspace table, you may want to propagate those changes to the Table operator in the mapping. Conversely, as you make changes to a Table operator in a mapping, you may want to propagate those changes back to its associated workspace table. You can accomplish these tasks by a process known as synchronizing.
See Also:
"Synchronizing Operators and Workspace Objects" for more information about synchronizing mapping operators and workspace objectsOperators that Bind to Workspace Objects
The operators that you can bind to associated objects in the workspace are as follows:
To add an operator to a mapping:
Open the Mapping Editor.
From the Component Palette, drag an operator icon and drop it onto the canvas. Alternatively, from the Graph menu, select Add, the type of operator you want to add, and then the operator.
If the Component Palette is not displayed, select Component Palette from the View menu.
If you select an operator that you can bind to a workspace object, the Mapping Editor displays the Add operator_name Operator dialog box. For details on how to use this dialog box, see "Using the Add Operator Dialog Box to Add Operators".
If you select an operator that you cannot bind to a workspace object, Oracle Warehouse Builder may display a wizard or dialog box to help you create the operator.
Follow any prompts that are displayed by Oracle Warehouse Builder and click OK.
The Mapping Editor displays the operator maximized on the canvas. The operator name appears in the upper-left corner. You can view each attribute name and data type.
To minimize the operator, click the arrow in the upper-right corner and the Mapping Editor displays the operator as an icon on the canvas. To maximize the operator, double-click the operator on the canvas.
The Add Operator dialog box enables you to add operators to a mapping. When you add an operator that you can bind to a workspace object, the Mapping Editor displays the Add operator_name Operator dialog box.
Select one of the following options on this dialog box:
Select Create unbound operator with no attributes to define a new workspace object that is not bound to a workspace object, such as a new staging area table or a new target table.
In the New Operator Name field, enter a name for the new operator. Oracle Warehouse Builder displays the operator on the canvas without any attributes.
You can now add and define attributes for the operator as described in "Editing Operators". Next, to create the new workspace object in a target module, right-click the operator and select Create and Bind.
For an example of how to use this option in a mapping design, see "Example: Using the Mapping Editor to Create Staging Area Tables".
Click Select from existing repository object and bind to add an operator based on an existing workspace object. The object may have been previously defined or imported into the workspace.
Either type the prefix to search for the object or select from the displayed list of objects within the selected module.
To select multiple items, press the Ctrl key as you click each item. To select a group of items located in a series, click the first object in your selection range, press the Shift key, and then click the last object.
You can add operators based on workspace objects within the same module as the mapping or from other modules. If you select a workspace object from another module, then the Mapping Editor creates a connector, if one does not exist. The connector establishes a path for moving data between the mapping location and the location of the workspace object.
You can use the pseudocolumns ROWID and ROWNUM in mappings. The ROWNUM pseudocolumn returns a number indicating the order in which a row was selected from a table. The ROWID pseudocolumn returns the rowid (binary address) of a row in a database table.
You can use the ROWID and ROWNUM pseudocolumns in Table, View, and Materialized View operators in a mapping. These operators contain an additional column called COLUMN USAGE that is used to identify attributes used as ROWID or ROWNUM. For normal attributes, this column defaults to TABLE USAGE. To use an attribute for ROWID or ROWNUM values, set the COLUMN USAGE to ROWID or ROWNUM respectively.
You can map a ROWID column to any attribute of data type ROWID, UROWID, or VARCHAR2. You can map ROWNUM column to an attribute of data type NUMBER or to any other data type that enables implicit conversion from NUMBER.
ROWID and ROWNUM pseudocolumns are not displayed in the object editors since they are not real columns.
After you select mapping source operators, operators that transform data, and target operators, you are ready to connect them. Data flow connections graphically represent how the data flows from a source, through operators, and to a target. The Mapping Connection dialog box assists you in creating data flows between operators.
You can connect operators by any of the following methods:
"Connecting Operators": Define criteria for connecting groups between two operators.
"Connecting Groups": Define criteria for connecting all the attributes between two groups.
"Connecting Attributes": Connect individual operator attributes to each other, one at a time.
Using an Operator Wizard: For operators such as the Pivot operator and Name and Address operator, you can use the wizard to define data flow connections.
"Using the Mapping Connection Dialog Box": Define criteria for connecting operators, groups, or attributes.
To display the Mapping Connection dialog box, right-click an operator, group, or attribute, select Connect To and then the name of the operator to which you want to establish a connection. The Mapping Connections dialog box is displayed.
For more information about using this dialog box, see "Using the Mapping Connection Dialog Box".
After you connect operators, data flow connections are displayed between the connected attributes.
Figure 5-2 displays a mapping with attributes connected.
Figure 5-2 Connected Operators in a Mapping
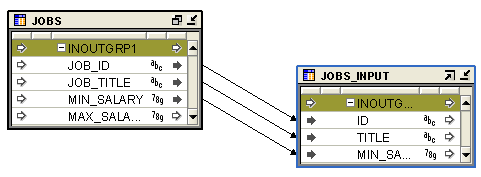
You can connect one operator to another if there are no existing connections between the operators. Both of the operators to connect must be displayed in their icon form.
You can also connect from a group to an operator. Hold down the left-mouse button on the group, drag and then drop on the title of the operator.
To connect one operator to another:
Select the operator from which you want to establish a connection.
Click and hold down the left mouse button while the pointer is positioned over the operator icon.
Drag the mouse away from the operator and toward the operator icon to which you want to establish a connection.
As you drag, a line appears indicating the connection.
Release the mouse button over the target operator.
The Mapping Connection dialog box is displayed. Use this dialog box to specify connections between groups and attributes within these groups as described in "Using the Mapping Connection Dialog Box".
When you connect groups, the Mapping Editor assists you by either automatically copying the attributes or prompts you for more information as described in "Using the Mapping Connection Dialog Box".
To connect one group to another:
Select the group from which you want to establish a connection.
Click and hold down the left mouse button while the pointer is positioned over the group.
Drag the mouse away from the group and toward the group to which you want to establish a connection.
As you drag, a line appears indicating the connection.
Release the mouse button over the target group.
If you connect from an operator group to a target group containing attributes, the Mapping Connection Dialog Box is displayed. Use this dialog box to specify connections between attributes as described in "Using the Mapping Connection Dialog Box".
If you connect from one operator group to a target group with no existing attributes, the Mapping Editor automatically copies the attributes and connects the attributes. This is useful for designing mappings such as the one shown in "Example: Using the Mapping Editor to Create Staging Area Tables".
You can draw a line from a single output attribute of one operator to a single input attribute of another operator.
To connect attributes:
Click and hold down the left mouse button while the pointer is positioned over an output attribute.
Drag the mouse away from the output attribute and toward the input attribute to which you want data to flow.
As you drag the mouse, a line appears on the Mapping Editor canvas to indicate a connection.
Release the mouse over the input attribute.
Repeat Steps 1 through 3 until you create all the required data flow connections.
You can also select multiple attribute in Step 1. To select multiple attribute, hold down the Ctrl key and select attributes by clicking them. If you select multiple source attributes, then you can only release the mouse over a group and not over an output attribute. The Mapping Connection dialog box is displayed. Use this dialog box to define the data flow between the source attributes and target attributes.
As you connect attributes, remember the following rules:
You cannot connect to the same input or inout attribute twice.
You cannot connect attributes within the same operator.
You cannot connect out of an input-only attribute nor can you connect into an output-only attribute.
You cannot connect operators in such a way about contradicting an established cardinality. Instead, use a Joiner operator.
The Mapping Connection dialog box enables you to define connections between operators in the mapping. Typically, mappings contain numerous operators that implement the complex transformation logic required for your data loading process. The operators to connect may be situated far away from each other on the mapping and thus require scrolling. Oracle Warehouse Builder provides an efficient method to connect operators, groups, and attributes by using the Mapping Connection dialog box.
Figure 5-3 displays the Mapping Connection Dialog box.
Complete the following sections to define connections between operators:
Use this section to select the source and target groups between which you want to establish connections. This section is displayed only if you try to connect a source operator to a target group, a source group to a target operator, or a source operator to a target operator.
Source Group The Source Group corresponds to the group on the source operator from which data flows. The Source Group list contains all the output groups and I/O groups in the source operator. Select the group from which you want to create a data flow.
Target Group The Target Group corresponds to the group on the operator to which data flows. The Target Group list contains the input groups and I/O groups in the target operator. Select the group to which you want to create a data flow.
Once you select the Source Group and Target Group, you can specify connections between attributes in the source and target groups. Thus, you can establish data flows between all groups of the source and target operators at the same time.
Note:
If you have created any connections for the selected source or target group, when you select a different group, Oracle Warehouse Builder displays a warning asking to save the current changes.The Connection Options section enables you to use different criteria to automatically connect all the source attributes to the target attributes.
Select one of the following options for connecting attributes:
After you select the option that you use to connect attributes in the groups, click Preview to view the mapping between the source and target attributes in the Connections section. Review the mappings and click OK after you are satisfied that the mappings are what you wanted.
Copy Source Attributes to Target Group and Match
Use this option to copy source attributes to a target group that contains attributes. The Mapping Editor connects from the source attributes to the new target attributes based on the selections that you make in the Connect Operators dialog box. Oracle Warehouse Builder does not perform this operation on target groups that do not accept new input attributes, such as dimension and cube target operators.
Match By Position of Source and Target Attributes
Use this option to connect existing attributes based on the position of the attributes in their respective groups. The Mapping Editor connects all attributes in order until all attributes of the target are matched. If the source operator contains more attributes than the target, then the remaining source attributes are left unconnected.
Match By Name of Source and Target Attributes
Use this option to connect attributes with matching names. By selecting from the list of options, you connect between names that do not match. You can combine the following options:
Ignore case differences: Considers the same character in lower-case and upper-case a match. For example, the attributes FIRST_NAME and First_Name match.
Ignore special characters: Specify characters to ignore during the matching process. For example, if you specify a hyphen and underscore, the attributes FIRST_NAME, FIRST-NAME, and FIRSTNAME all match.
Ignore source prefix, Ignore source suffix, Ignore target prefix, Ignore target suffix: Specify prefixes and suffixes to ignore during matching. For example, if you select Ignore source prefix and enter USER_ into the text field, then the source attribute USER_FIRST_NAME matches the target attribute FIRST_NAME.
This section displays any informational messages that result from previewing the connection options. Information such as certain source or target attributes not connected due to unresolved conflicts is displayed in this section.
The Connections section displays the connections between the source attributes belonging to the Source Group and the target attributes belonging to the Target Group. Any existing connections between attributes of the Source Group and Target Group are displayed in this section.
This section contains two tabs: Source Connections and Target Connections. Both tabs display a spreadsheet containing the Source Attribute and Target Attribute columns. The Source Attribute column lists all attributes, or the attributes selected on the canvas, for the group selected as the Source Group. The Target Attribute column lists all the attributes of the group selected as the Target Group. Any changes that you make on the Source Connections tab or the Target Connections tab are immediately reflected in the other tab.
The Source Connections tab enables you to quickly establish connections from the "Source Group". The Target Attribute column on this tab lists the attributes from the "Target Group". Use this tab to specify the source attribute from which each target attribute is connected. For each target attribute, map zero or one source attribute. To connect a particular source attribute to the listed target attribute, for each target attribute, enter the name of the source attribute in the corresponding Source Attribute column.
As you begin typing an attribute name, Oracle Warehouse Builder displays a list containing the source attributes whose names begin with the letters you type. If you see the source attribute to connect in this list, then select the attribute by clicking it. You can use wild cards such as * and ? to search for the source attributes from which you want to create a data flow. You can also sort the columns listed under Target Attribute column. When the attribute name contains the space or comma characters, use double quotes to quote the name of the source attribute.
The Target Connections tab enables you to quickly establish connections to the "Target Group". The Source Attribute column displays the list of attributes from the "Source Group". Use this tab to specify the source attributes from which each target attribute is connected. For each source attribute, enter the name of one or more target attributes in the corresponding Target Attribute column. To connect a source attribute to multiple target attributes, type the names of the source attributes separated by a comma in the Target Attribute column.
As you begin typing an attribute name, Oracle Warehouse Builder displays a list containing the target attributes whose names begin with the letters you type. If the target attribute to connect to is displayed in this list, then select the attribute by clicking it. You can also use wild cards such as * and ? to search for target attributes to which you want to create a data flow. You can sort the columns listed under Source Attribute column.
Each operator has an editor associated with it. Use the operator editor to specify general and structural information for operators, groups, and attributes. In the operator editor you can add, remove, or rename groups and attributes. You can also rename an operator.
For attributes that can have an expression associated with them, such as attributes in the output group of a Constant, Expression, or Aggregator operator, you can also edit the expression specified.
Editing operators is different from assigning loading properties and conditional behaviors. To specify loading properties and conditional behaviors, use the properties windows as described in "Configuring Mappings".
To edit an operator, group, or attribute:
Select an operator from the Mapping Editor canvas.
Or select any group or attribute within an operator.
Right-click and select Open Details.
The Mapping Editor displays the operator editor with the "Name Tab", "Groups Tab", and "Input and Output Tabs" for each type of group in the operator.
Some operators include additional tabs. For example, the Match Merge operator includes tabs for defining Match rules and Merge rules.
Follow the prompts on each tab and click OK when you are finished.
The Name tab displays the operator name and an optional description. You can rename the operator and add a description. Name the operator according to the conventions listed in "Rules for Naming Mappings".
Edit group information on the Groups tab.
Each group has a name, direction, and optional description. You can rename groups for most operators but cannot change group direction for any of the operators. A group can have one of these directions: Input, Output, I/O.
Depending on the operator, you can add and remove groups from the Groups tab. For example, you add input groups to Joiners and output groups to Splitters.
The operator editor displays a tab for each type of group displayed on the Groups tab. Each of these tabs displays the attribute name, data type, length, precision, scale, seconds precision, and optional description. Certain operators such as the Table or View operators have only the I/O tab, instead of separate Input and Output tabs. Edit attribute information on these tabs.
Figure 5-4 shows an Output Attributes tab on the operator editor. In this example, the operator is an Aggregator, with separate Input and Output tabs.
Figure 5-4 Output Tab on the Operator Editor
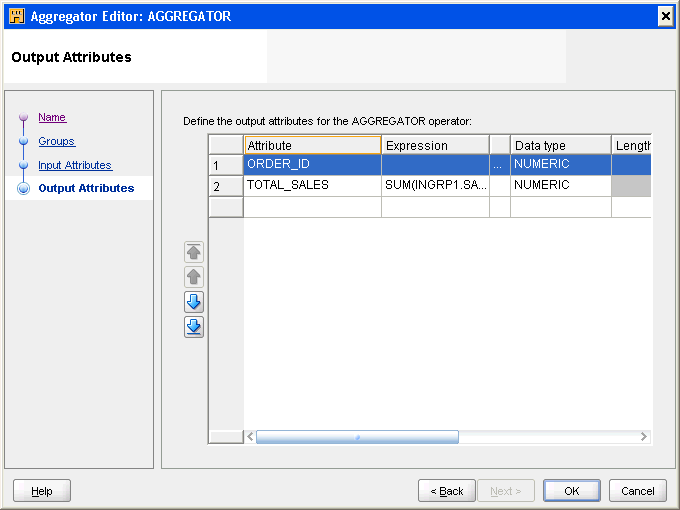
The tab contains a table that you can use to define output attributes. Each row on this tab represents an attribute. The Mapping Editor disables properties that you cannot edit. For example, if the data type is NUMBER, you can edit the precision and scale but not the length.
You can add, remove, and edit attributes. To add an attribute, click Attribute column of an empty row, enter the attribute name and then provide the other attribute details such as data type, length, and description. To delete an attribute, right-click the gray cell to the left of the attribute and select Remove.
To assign correct values for data type, length, precision, and scale in an attribute, follow PL/SQL rules. When you synchronize the operator, Oracle Warehouse Builder checks the attributes based on SQL rules.
You can also change the order of the attributes listed in the Input and Output tabs. Select the row representing the attribute and use the arrow buttons to the left of the attributes to reorder attributes in a group. Alternatively, hold down the left-mouse button until you see a cross-hair and then drag the row to the position you want.
Associating Expressions with Operator Attributes
Attributes in certain operators such as Expression, Joiner, Aggregator, and Lookup can have an expression associated with them. For such attributes, use the Expression column of the attribute to specify the expression used to create the attribute value. You can directly enter the expression in the Expression column. Figure 5-4 displays the Expression column for an output attribute in the Aggregator operator. To use the Expression Builder interface to define your expression, click the Ellipsis button to the right of the Expression column.
For example, in an Aggregator operator, you create output attributes that store the aggregated source columns. Use the Expression column for an output attribute to specify the expression used to create the attribute value.
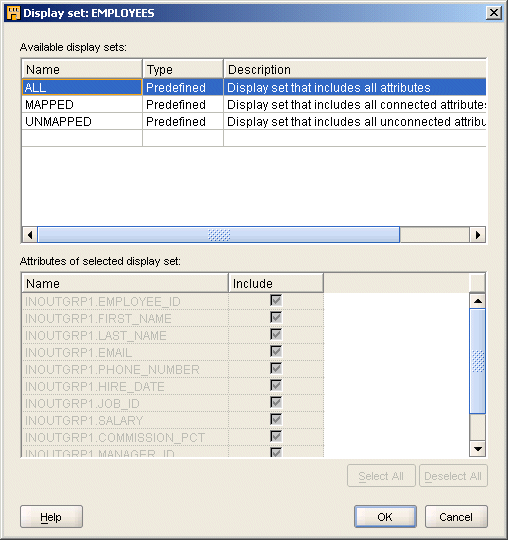
A display set is a graphical representation of a subset of attributes. Use display sets to limit the number of attributes visible in an operator and simplify the display of a complex mapping.
By default, operators contain three predefined display sets: ALL, MAPPED, and UNMAPPED. Table 5-1 describes the default display sets.
| Display Set | Description |
|---|---|
|
ALL |
Includes all attributes in an operator |
|
MAPPED |
Includes only those attributes in an operator that are connected to another operator |
|
UNMAPPED |
Includes only those attributes that are not connected to other attributes |
You can define display sets for any operator in a mapping.
To define a display set:
Right-click an operator, and select Define Display Set.
The Display Set dialog box is displayed as shown in Figure 5-5.
Click the row below UNMAPPED and enter a name and description for the new display set.
All available attributes for the operator appear in section called Attributes of selected display set. The Type column is automatically set to User defined.
You cannot edit or delete a Predefined attribute set.
In the Include column, select each attribute to include in the display set.
Click Select All to include all attributes and Deselect All to exclude all the attributes.
Click OK.
The group for the operator now lists only those attributes contained within the Attribute Set selected for display.
After you define a mapping, you can use the Property Inspector to set properties for the mapping.
You can set the following properties:
Mapping Properties: Properties that affect the entire mapping. For example, you can set the Target Load Order parameter defines the order in which targets are loaded when the mapping is run.
Operator Properties: Properties that affect the operator as a whole. The properties you can set depend upon the operator type. For example, the steps for using Oracle source and target operators differ from the steps for using flat file source and target operators.
Group Properties: Properties that affect a group of attributes. Most operators do not have properties for their groups. Examples of operators that do have group properties include the Splitter operator and the Deduplicator operator.
Attribute Properties: Properties that pertain to attributes in source and target operators. Examples of attribute properties are data type, precision, and scale.
Setting Operator, Group, and Attribute Properties
When you select an operator, group, or attribute on the Mapping Editor canvas, its associated properties are displayed in the Property Inspector. Set values for the required properties using the Property Inspector. The properties that you can set are documented in the chapters that discuss the operators.
See Also:
To set properties for a mapping, select the Mapping in the Projects Navigator. The Property Inspector displays the properties of the mapping.
You can set values for the following properties: Business Name, Physical Name, Description, Execution Type, and Target Load Order.
Use the Target Load Order configuration parameter to specify the order in which targets in the mapping are loaded as described in "Specifying the Order in Which Target Objects in a Mapping Are Loaded".
If your mapping includes only one target or is a SQL*Loader or ABAP mapping, target load ordering does not apply. Accept the default settings and continue with your mapping design.
When you design a PL/SQL mapping with multiple targets, Oracle Warehouse Builder calculates a default ordering for loading the targets. If you define foreign key relationships between targets, then Oracle Warehouse Builder creates a default order that loads the parent and then the child. If you do not create foreign key relationships or if a target table has a recursive relationship, then Oracle Warehouse Builder assigns a random ordering as the default.
You can override the default load ordering by setting the mapping property Target Load Order. If you make a mistake when reordering the targets, then you can restore the default ordering by selecting the "Reset to Default" option. Or you can select Cancel to discard your changes to the target order.
To specify the loading order for multiple targets:
Click whitespace in the mapping canvas to view the mapping properties in the Property Inspector.
If the Property Inspector is not displayed, select Property Inspector from the View menu.
Go to the Target Load Order property and click the Ellipsis button on the right of this property.
Oracle Warehouse Builder displays the Target Load Order dialog box in which TARGET2 is listed before TARGET1.
To change the loading order, select a target and use the buttons to move the target up or down on the list.
Use the Reset to Default button to instruct Oracle Warehouse Builder to recalculate the target loading order. You may want to recalculate if you made an error reordering the targets or if you assigned an order and later changed the mapping design such that the original order became invalid.
After you define mappings, you can configure them to specify the physical properties of the mapping and the operators contained in the mapping. Configuring a mapping enables you to control the code generation, so that Oracle Warehouse Builder produces optimized code for the mapping and for your particular environment.
Use the following steps to configure mappings.
In the Projects Navigator, right-click the mapping and select Configure.
Oracle Warehouse Builder displays the Configuration tab that contains configuration parameters for the mapping.
This tab contains the Deployable, Language, Generation Comments, and Referred Calendar parameters. It also contains the Run time Parameters and Code Generation Options nodes. Additionally, each operator on the mapping is listed under the node representing the object or operator type. For example, if your mapping contains two tables and a Filter operator, the Table Operators node displays the configuration parameters for the two tables and the Filter Operator node displays the configuration parameters for the Filter operator.
Set the Deployable parameter to True.
Set Language to the type of code to generate for the selected mapping.
The options from which you can choose depend upon the design and use of the operators in the mapping. Oracle Warehouse Builder provides the following options: PL/SQL, SQL*PLUS, SQL*Loader, and ABAP (for an SAP source mapping).
To schedule the mapping to run based on a previously defined schedule, click the Ellipsis button on the Referred Calendar parameter.
The Referred Calendar dialog box is displayed. Any schedules created are listed here. Select the schedule to associate with the current mapping.
For instructions on creating and using schedules, see Chapter 11, "Scheduling ETL Jobs".
Expand "Code Generation Options" to enable performance options that optimize the code generated for the mapping.
For a description of each option, see "Code Generation Options".
(Optional) To define chunking for a PL/SQL mapping, use one of the following:
To configure serial chunking, expand "SCD Updates" and set the parameters described in "SCD Updates".
To configure parallel chunking, expand "Chunking Options", then Details, and set the parameters depending upon the method of parallel chunking you plan to use. Also, ensure that serial chunking is not enabled for this mapping.
See Also:
"Chunking Options" for a description of the parallel chunking parameters.To set Run time parameters corresponding to parallel chunking, after you set values under Chunking Options, close the Mapping Configuration Editor and reopen it to display the parallel chunking-related Run time parameters.
Note:
You can perform chunking for PL/SQL mappings only.Expand "Runtime Parameters" to configure your mapping for deployment.
For a description of each run time parameter, see "Runtime Parameters".
Go to the node for each operator in the mapping to set their physical properties. The properties displayed under a particular node depend on the type of object. For example, for tables listed under the Table Operators node, you can configure the table parameters listed in "Configuring Tables".
See Also:
"Sources and Targets Reference" for information about configuring sources and targets in a mapping.
"Configuring Flat File Operators" for information about configuring mappings with flat file sources and targets.
Note:
In some environments, changing the location to host name instead of IP address causes performance downgrade.Many of the operators that you use in a mapping have corresponding definitions in Oracle Warehouse Builder workspace. This is true of source and target operators such as table and view operators. This is also true of other operators, such as sequence and transformation operators, whose definitions you may want to use across multiple mappings. As you make changes to these operators, you may want to propagate those changes back to the workspace object.
You have the following choices in deciding the direction in which to propagate changes:
Synchronizing a Mapping Operator with its Associated Workspace Object
It enables you to propagate changes in the definition of a workspace object to the mapping operator that is bound to the workspace object.
You can also synchronize all the operators in a mapping with their corresponding definitions in the workspace as described in "Synchronizing All Operators in a Mapping".
Synchronizing a Workspace Object with a Mapping Operator
It enables you to propagate changes made to a mapping operator to its corresponding workspace definition. You can select a single operator and synchronize it with the definition of a specified workspace object.
Synchronizing is different from refreshing. The refresh command ensures that you are up-to-date with changes made by other users in a multiuser environment. Synchronizing matches operators with their corresponding workspace objects.
After you begin using mappings in a production environment, changes may be made to the sources or targets that affect your ETL designs. Typically, the best way to manage these changes is through the Metadata Dependency Manager described in Chapter 14, "Managing Metadata Dependencies". Use the Metadata Dependency Manager to automatically evaluate the impact of changes and to synchronize all affected mappings .
The Mapping Editor enables you to manually synchronize objects as described in this section.
When Do You Synchronize from a Workspace Object to an Operator?
In the Mapping Editor, you can synchronize from a workspace object to an operator for any of the following reasons:
To manually propagate changes: Propagate changes you made in a workspace object to its associated operator. Changes to the workspace object can include structural changes, attribute name changes, or attribute data type changes.
To automatically propagate changes in a workspace object across multiple mappings, see Chapter 14, "Managing Metadata Dependencies".
To synchronize an operator with a new workspace object: You can synchronize an operator with a new workspace object if, for example, you migrate mappings from one version of a data warehouse to a newer version and maintain different object definitions for each version.
To create a prototype mapping using tables: When working in the design environment, you could choose to design the ETL logic using tables. However, for production, you may want to the mappings to source other workspace object types such as views, materialized views, or cubes.
Synchronizing Physical and Business Names
While synchronizing from a workspace object to an operator, you can specify if the physical and business names of the operator, groups, and attributes should be synchronized. By default, the bound name of the operator, groups and attributes must be derived from the physical name of the corresponding workspace object. Synchronize Name Changes listed under the Naming node of the Preferences dialog box controls the synchronization behavior.
If you select the Synchronize Name Changes preference under the Naming node of the Preferences dialog box, a synchronize operation on any operator synchronizes the physical and business names of the operator, groups, and attributes. If you deselect the Synchronize Name Changes preference, then the physical and business names of the operator, groups, and attributes are not synchronized.
See Also:
Oracle Warehouse Builder Concepts for more information about Oracle Warehouse Builder preferences.Steps to Synchronize from a Workspace Object to an Operator
Use the following steps to synchronize an operator with the workspace object to which it is bound.
On the Mapping Editor canvas, select the operator to synchronize. When the operator is displayed in maximized form, select the operator by clicking the operator name.
Right-click and select Synchronize.
The Synchronize dialog box is displayed.
In the Repository Object with which to Synchronize field, select the workspace object with which you want to synchronize the mapping operator.
By default, the workspace object to which the mapping operator was originally bound is displayed in this field.
Under Direction of Synchronization, select Inbound.
In the Matching Strategy field, select the matching strategy to be used during synchronization.
For more information about the matching strategy, see "Matching Strategies".
In the Synchronize strategy field, select the synchronization strategy.
Select Replace to replace the mapping operator definition with the workspace object definition. Select Merge to add any new metadata definitions and overwrite existing metadata definitions if they differ from the ones in the workspace object.
Click OK to complete the synchronization.
You can synchronize all operators in a mapping with their bound workspace objects using a single step. To synchronize the operators, open the mapping containing the operators to be synchronized. With the Mapping Editor canvas as the active panel, from the Edit menu, select Synchronize All. The Synchronize All panel is displayed. Use this panel to define synchronization options.
The Synchronize All panel displays one row for each mapping operator that is bound to a workspace object. Select the box to the left of all the object names which you want to synchronize with their bound workspace objects. For each operator, specify values in the following columns:
From Repository: Displays the workspace object to which the mapping operator is bound.
To modify the workspace object to which an operator is bound, click the Ellipsis button to the right of the workspace object name. The Source dialog box is displayed. Click the list on this page to select the new workspace object and click OK.
To Mapping: Displays the name of the mapping operator. This field is not editable.
Matching Strategy: Select the matching strategy used while synchronizing operators. For more information about matching strategies, see "Matching Strategies".
Synchronize Strategy: Select the synchronization strategy used while synchronizing operators. You can select Replace or Merge as the synchronize strategy.
As you make changes to operators in a mapping, you may want to propagate those changes to a workspace object. By synchronizing, you can propagate changes from the following operators: Table, View, Materialized View, Transformation, and Flat File.
Synchronize from the operator to a workspace object for any of the following reasons:
To propagate changes: Propagate changes that you made in an operator to its associated workspace object. When you rename the business name for an operator or attribute, Oracle Warehouse Builder propagates the first 30 characters of the business name as the bound name.
To replace workspace objects: Synchronize to replace an existing workspace object.
Synchronizing from an operator has no impact on the dependent relationship between other operators and the workspace object. Table 5-2 lists the operators from which you can synchronize.
Table 5-2 Outbound Synchronize Operators
| Mapping Object | Create Workspace Objects | Propagate Changes | Replace Workspace Objects | Notes |
|---|---|---|---|---|
|
External Table |
Yes |
Yes |
Yes |
Updates the workspace external table only and not the flat file associated with the external table. See Oracle Warehouse Builder Sources and Targets Guide for details. |
|
Flat File |
Yes |
Yes |
No |
Creates a new, comma-delimited flat file for single record type flat files only. |
|
Mapping Input Parameter |
Yes |
Yes |
Yes |
Copies input attributes and data types as input parameters |
|
Mapping Output Parameter |
Yes |
Yes |
Yes |
Copies output attributes and data types as return specification for the function |
|
Materialized View |
Yes |
Yes |
Yes |
Copies attributes and data types as columns |
|
Table |
Yes |
Yes |
Yes |
Copies attributes and data types as columns. Constraint properties are not copied |
|
Transformation |
No |
No |
No |
Not applicable. |
|
View |
Yes |
Yes |
Yes |
Copies attributes and data types as columns |
Use the following steps to synchronize from a mapping operator to a workspace object. Synchronization causes the workspace object to be updated with changes made to the mapping operator after the mapping was created.
On the Mapping Editor canvas, select the operator whose changes you want to propagate to the bound workspace object.
From the Edit menu, select Synchronize. Or, right-click the header of the operator and select Synchronize.
The Synchronize Operator dialog box is displayed.
In the Repository Object with which to Synchronize field, select the workspace object that should be updated with the mapping operator definition changes.
By default, Oracle Warehouse Builder displays the workspace object to which the mapping operator was initially bound.
In the Direction of Synchronization field, select Outbound.
(Optional) In the Matching strategy field, select the matching strategy used during synchronization. See "Matching Strategies".
(Optional) In the Synchronize Strategy field select the synchronization strategy.
Select Replace to replace the workspace object definition with the mapping operator definition. Select Merge to add any new metadata definitions and overwrite existing metadata definitions if they differ from the ones in the mapping operator.
Click OK.
Use the Synchronization Plan dialog box to view and edit the details of how Oracle Warehouse Builder synchronizes your selected objects. After you select from the "Matching Strategies", click Refresh Plan to view the actions that Oracle Warehouse Builder takes.
In the context of synchronizing, source refers to the object from which to inherit differences and target refers to the object to be changed.
For example, in Figure 5-6, the flat file PAYROLL_WEST is the source and the Flat File operator PAYROLL is the target. Therefore, Oracle Warehouse Builder creates new attributes for the PAYROLL operator to correspond to fields in the flat file PAYROLL_WEST.
Figure 5-6 Advanced Synchronizing Options
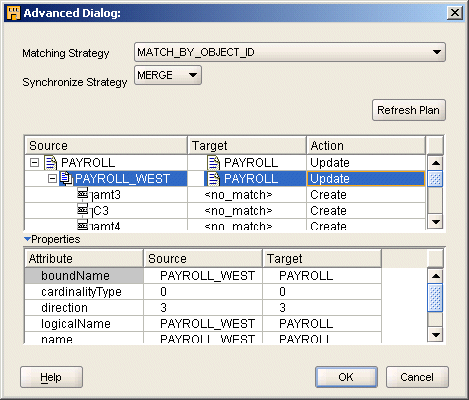
Set the matching strategy that determines how Oracle Warehouse Builder compares an operator to a workspace object. If synchronization introduces changes such as adding or deleting attributes in an operator, then Oracle Warehouse Builder refreshes the Mapping Editor. If synchronization removes an operator attribute, then data flow connections to or from the attribute are also removed. If synchronization adds an operator attribute, then the Mapping Editor displays the new attributes after the operator. Data flow connections between matched attributes are preserved. If you rename an attribute in the source object, then this is interpreted as if the attribute were deleted and a new attribute added.
You can specify the following strategies for synchronizing an object in a mapping:
This strategy compares the unique object identifier of an operator attribute with that of a workspace object. The Match by object identifier is not available for synchronizing an operator and workspace object of different types, such as a View operator and a workspace table.
Use this strategy if you want the target object to be consistent with changes to the source object and to maintain separate business names despite changes to physical names in the target object.
Oracle Warehouse Builder removes attributes from the target object that do not correspond to attributes in the source object. This can occur when an attribute is added to or removed from the source object.
This strategy matches the bound names of the operator attributes to the physical names of the workspace object attributes. Matching is case-sensitive.
Use this strategy if you want bound names to be consistent with physical names in the workspace object. You can also use this strategy with a different workspace object if there are changes in the workspace object that would change the structure of the operator.
Oracle Warehouse Builder removes attributes of the operator that cannot be matched with those of the workspace object. Attributes of the selected workspace object that cannot be matched with those of the operator are added as new attributes to the operator. Because bound names are read-only after you have bound an operator to a workspace object, you cannot manipulate the bound names to achieve a different match result.
This strategy matches operator attributes with columns, fields, or parameters of the selected workspace object by position. The first attribute of the operator is synchronized with the first attribute of the workspace object, the second with the second, and so on.
Use this strategy to synchronize an operator with a different workspace object and to preserve the names of the attributes in the operator. This strategy is most effective when the only changes to the workspace object are the addition of extra columns, fields, or parameters after the object.
If the target object has more attributes than the source object, then Oracle Warehouse Builder removes the excess attributes. If the source object has more attributes than the target object, then Oracle Warehouse Builder adds the excess attributes as new attributes.
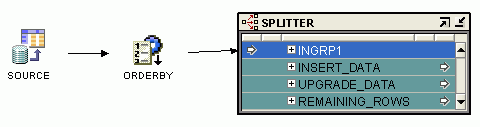
Your company records all its transactions as they occur, resulting in inserts, updates, and deletes, in a flat file called record.csv. These transactions must be processed in the exact order they were stored. For example, if an order was first placed, then updated, then canceled and reentered, this transaction must be processed exactly in the same order.
An example data set of the source file record.csv is defined as:
Action,DateTime,Key,Name,Desc I,71520031200,ABC,ProdABC,Product ABC I,71520031201,CDE,ProdCDE,Product CDE I,71520031202,XYZ,ProdXYZ,Product XYZ U,71620031200,ABC,ProdABC,Product ABC with option D,71620032300,ABC,ProdABC,Product ABC with option I,71720031200,ABC,ProdABC,Former ProdABC reintroduced U,71720031201,XYZ,ProdXYZ,Rename XYZ
You want to load the data into a target table such as the following:
SRC_TIMESTA KEY NAME DESCRIPTION ----------- --- ------- --------------------------- 71520031201 CDE ProdCDE Product CDE 71720031201 XYZ ProdXYZ Rename XYZ 71720031200 ABC ProdABC Former ProdABC reintroduced
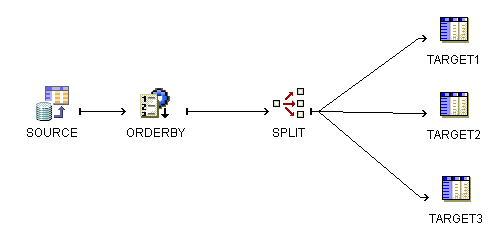
You must create ETL logic to load transaction data in a particular order using Oracle Warehouse Builder.
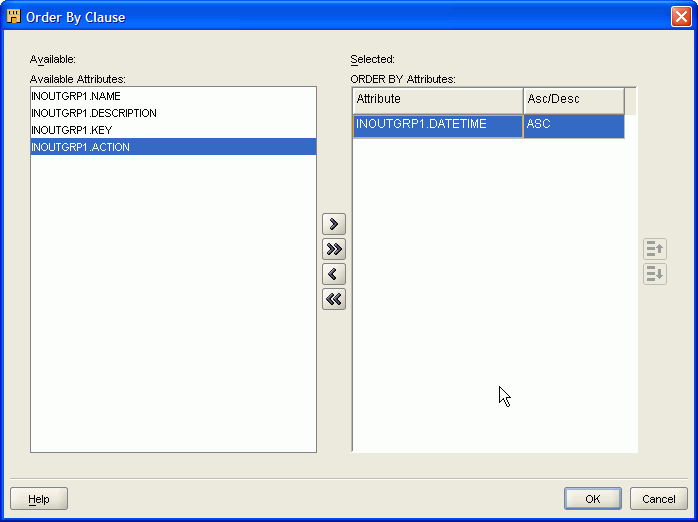
Oracle Warehouse Builder enables you to design ETL logic and load the data in the exact temporal order in which the transactions were stored at the source. To achieve this result, you design a mapping that orders and conditionally splits the data before loading it into the target. Then, you configure the mapping to generate code in row-based operating mode. In row-based operating mode, Oracle Warehouse Builder generates code to process the data row by row using if-then-else constructions, as shown in the following example.
CURSOR
SELECT
"DATETIME$1"
FROM
"JOURNAL_EXT"
ORDER BY "JOURNAL_EXT"."DATETIME" ASC
LOOP
IF "ACTION" = 'I' THEN
INSERT this row
ELSE
IF "ACTION" = 'U' THEN
UPDATE this row
ELSE
DELETE FROM
"TARGET_FOR_JOURNAL_EXT"
END LOOP;
This ensures that all consecutive actions are implemented in sequential order and the data is loaded in the order in which the transaction was recorded.
Step 1: Import and Sample the Source Flat File, record.csv
In this example, the flat file record.csv stores all transaction records and a timestamp. Import this flat file from your source system using the Metadata Import Wizard. Define the metadata for the flat file in Oracle Warehouse Builder using the Flat File Sample Wizard.
Note:
You can replace this flat file with a regular table if your system is sourced from a table. In this case, skip to "Step 3: Design the Mapping".Step 2: Create an External Table
To simplify the use of a sampled flat file object in a mapping, create an external table (JOURNAL_EXT) using the Create External Table Wizard, based on the flat file imported and sampled in "Step 1: Import and Sample the Source Flat File, record.csv".
The advantage of using an external table instead of a flat file is that it provides you direct SQL access to the data in your flat file. Hence, it is not required to stage the data.
In this mapping, you move the transaction data from an external source, through an operator that orders the data, followed by an operator that conditionally splits the data before loading it into the target table.
Figure 5-7 shows you how the source is ordered and split.
The Sorter operator enables you to order the data and process the transactions in the exact order in which they were recorded at the source. The Splitter operator enables you to conditionally handle all the inserts, updates, and deletes recorded in the source data by defining a split condition that acts as the if-then-else constraint in the generated code. The data is conditionally split and loaded into the target table. In this mapping, the same target table is used three times to demonstrate this conditional loading. The mapping tables TARGET1, TARGET2, and TARGET3 are all bound to the same workspace table TARGET. All the data goes into a single target table.
The following steps show you how to build this mapping.
Create a mapping called LOAD_JOURNAL_EXT using the Create Mapping dialog box. Oracle Warehouse Builder then opens the Mapping Editor where you can build your mapping.
Step 5: Add an External Table Operator
Drag and drop a mapping external table operator onto the Mapping Editor canvas and bind it to the external table JOURNAL_EXT.
Add the Sorter operator to define an order-by clause that specifies the order in which the transaction data must be loaded into the target.
See Also:
"Sorter Operator" for more information about using the Sorter operator.Figure 5-8 shows you how to order the table based on the timestamp of the transaction data in ascending order.
Step 7: Define a Split Condition
Add the Splitter operator to conditionally split the inserts, updates, and deletes stored in the transaction data. This split condition acts as the if-then-else constraint in the generated code.
Figure 5-9 shows how to join the SOURCE operator with the ORDERBY operator that is linked to the Splitter operator.
Define the split condition for each type of transaction. For outgroup INSERT_DATA, define the split condition as INGRP1.ACTION = 'I'. For UPGRADE_DATA, define the split condition as INGRP1.ACTION = 'U'. In Oracle Warehouse Builder, the Splitter operator contains a default group called REMAINING_ROWS that automatically handles all Delete ('D') records.
Step 8: Define the Target Tables
Use the same workspace target table three times for each type of transaction: for INSERT_DATA, once for UPDGRADE_DATA, and once for REMAINING_ROWS.
Step 9: Configure the Mapping LOAD_JOURNAL_EXT
After you define the mapping, you must configure the mapping to generate code. Because the objective of this example is to process the data strictly in the order in which it was stored, you must select row-based as the default operating mode. In this mode, the data is processed row by row and the insert, update, and delete actions on the target tables occur in the exact order in which the transaction was recorded at the source.
Do not select set-based mode as Oracle Warehouse Builder then generates code that creates one statement for all insert transactions, one statement for all update transactions, and a third one for all delete transactions. The code then calls these procedures one after the other, completing one action completely before following up with the next action. For example, it first handles all inserts, then all updates, and then all deletes.
To configure a mapping for loading transaction data:
From the Projects Navigator, right-click the LOAD_JOURNAL_EXT mapping and select Configure.
Expand the Run time parameters node and set the Default Operating Mode parameter to Row based.
In this example, accept the default value for all other parameters. Validate the mapping before generating the code.
After you generate the mapping, Oracle Warehouse Builder displays the results in the Log window.
When you inspect the code, you see that Oracle Warehouse Builder implements all consecutive actions in row-based mode. It means that the data is processed row by row and Oracle Warehouse Builder evaluates all conditions in sequential order using if-then-else constructions. The resulting target table thus maintains the sequential integrity of the transactions recorded at source.
You can use the Mapping Editor with an unbound table operator to quickly create staging area tables.
The following instructions describe how to create a staging table based on an existing source table. You can also use these instructions to create views, materialized views, flat files, and transformations.
To map a source table to a staging table:
In the Mapping Editor, add a source table.
From the menu bar, select Graph, then Add, then Data Sources/Targets, and then Table Operator. Alternatively, drag and drop the source table from the Projects Navigator onto the Mapping Editor canvas.
Use the Add Table Operator dialog box to select and bind the source table operator in the mapping. From the Add Table Operator dialog box, select Create unbound operator with no attributes.
The mapping should now resemble Figure 5-10, with one source table and one staging area table without attributes.
Figure 5-10 Unbound Staging Table without Attributes and Source Table
With the mouse pointer positioned over the group in the source operator, click and hold down the mouse button.
Drag the mouse to the staging area table group.
Oracle Warehouse Builder copies the source attributes to the staging area table and connects the two operators.
In the Mapping Editor, select the unbound table that you added to the mapping. Right-click and select Create and Bind.
Oracle Warehouse Builder displays the Create And Bind dialog box.
In the Create in field, specify the target module in which to create the table.
Oracle Warehouse Builder creates the new table in the target module that you specify.
You can reuse the data flow of a mapping by creating a pluggable mapping around the portion of the flow to reuse. A pluggable mapping is a reusable grouping of mapping operators that works as a single operator. It is similar to the concept of a function in a programming language and is a graphical way to define a function.
When defined, a pluggable mapping appears as a single mapping operator, nested inside a mapping. You can reuse a pluggable mapping more than once in the same mapping, or in other mappings. You can include pluggable mappings within other pluggable mappings.
Like any operator, a pluggable mapping has a signature consisting of input and output attributes that enable you to connect it to other operators in various mappings. The signature is similar to the input and output requirements of a function in a programming language.
See Also:
Oracle Warehouse Builder Concepts for more information about pluggable mappings.A pluggable mapping can be either reusable or embedded:
Reusable pluggable mapping: A pluggable mapping is reusable if the metadata it references can exist outside of the mapping in question. You can store reusable pluggable mappings either as standalone pluggable mappings, which are private for your use, or in folders (libraries). Users who have access to these folders can use the pluggable mappings as templates for their work.
Embedded pluggable mapping: A pluggable mapping is embedded if the metadata it references is owned only by the mapping or pluggable mapping in question. An embedded pluggable mapping is not stored as either a standalone mapping or in libraries on the Globals Navigator. It is stored only within the mapping or the pluggable mapping that owns it, and you can access it only by editing the object that owns it. To validate or generate the code for an embedded pluggable mapping, you must validate or generate the code for the object that owns it.
Pluggable mappings are usually predefined and used when required. You can create pluggable mappings either from within a mapping by using the Mapping Editor, or from the navigation tree by using the wizard. The wizard is the faster way to create a pluggable mapping because it makes some default choices and guides you through fewer choices. You can make additional choices later in the Pluggable Mapping Editor. The editor presents you with all the settings in a series of tabs.
The Pluggable Mappings node in the navigation tree contains the following two nodes:
Standalone: Contains standalone pluggable mappings
Pluggable Mapping Libraries: Contains a set of pluggable mappings providing related functionality that you would like to publish as a library.
You can create pluggable mappings under either of these nodes.
In the Projects Navigator, expand the project node and then the Pluggable Mappings node.
Right-click Standalone, and select New Pluggable Mapping.
The Create Pluggable Mapping Wizard is displayed.
On the Name and Description page, enter a name and an optional description for the pluggable mapping. Click Next.
On the Signature Groups page, one input signature group INGRP1 and one output signature group OUTGRP1 are displayed. Create any additional input or output signature groups as described in "Signature Groups". Click Next.
On the Input Signature page, define the input signature attributes for the pluggable mapping as described in "Input Signature". Click Next.
On the Output Signature page, define the output signature attributes for the pluggable mapping as described in "Output Signature". Click Next.
On the Summary page, review the options that you entered using the wizard. Click Back to modify an option. Click Finish to create the pluggable mapping.
Oracle Warehouse Builder opens the Pluggable Mapping Editor and displays the name of the pluggable mapping on the title bar.
Use the Pluggable Mapping Editor to add the required operators and create a data flow between the operators. For more information, see "Adding Operators to Mappings".
A pluggable mapping is considered as an operator by Oracle Warehouse Builder when it is used in a mapping. You can insert a pluggable mapping into any mapping. To use a pluggable mapping within a mapping, drag and drop the Pluggable Mapping operator from the Component Palette onto the canvas. The Add Pluggable Mapping dialog box is displayed. Select the required pluggable mapping and add it to the mapping.
The signature is a combination of input and output attributes flowing to and from the pluggable mapping. Signature groups are a mechanism for grouping the input and output attributes.
A pluggable mapping must have at least one input or output signature group. Most pluggable mappings are used in the middle of a logic flow and have input and output groups.
To create an additional signature group, click an empty cell in the Group column, enter the name of the group, and specify whether the group is an input or output group using the Direction column. You can enter an optional description for the column in the Description column.
To remove a signature group, right-click the gray cell to the left of the group name and select Delete.
Click Next to continue with the wizard.
The input signature is the combination of input attributes that flow into the pluggable mapping. Define the input attributes for each input signature group that you created.
If you defined multiple input signature groups, select the group to which you want to add attributes from the Group list box. To add an attribute, click an empty cell in the Attribute column and enter an attribute name. Use the Data Type field to specify the data type of the attribute. Also specify other details for the attribute such as length, precision, scale, and seconds precision by clicking the corresponding field and using the arrows on the field or typing in a value. Some of these fields are disabled depending on the data type you specify.
To remove an attribute, right-click the gray cell to the left of the attribute and select Delete.
Click Next to continue with the wizard.
The output signature is the combination of output attributes that flow out of the pluggable mapping. Define the output attributes for each output signature group that you created.
If you defined multiple output signature groups, select the group to which you want to add attributes from the Group list box. To add an attribute, click an empty cell in the Attribute column and enter the attribute name. Use the Data Type field to specify the data type of the attribute. Provide additional details about the attribute such as length, precision, and scale by clicking the corresponding field and using the arrows or typing the values. Some of these fields are disabled depending on the data type you specify.
To remove an attribute, right-click the gray cell to the left of the attribute name and select Delete.
Click Next to continue with the wizard.
You can also add an Input Signature or an Output Signature from the palette of the Pluggable Mapping Editor. A pluggable mapping can have only one Input Signature and one Output Signature. Also, pluggable mapping Input and Output signatures can only be added within pluggable mappings. They cannot be added to normal mappings.
A pluggable mapping folder is a container for a set of related pluggable mappings. You can keep your pluggable mappings private, or you can place them into folders and then publish the folders so that others can access them for their design work.
To create a pluggable mapping folder:
In the Projects Navigator, expand the project node and then the Pluggable Mappings node.
Right-click the Pluggable Mapping Folders node and select New Pluggable Mapping Folder.
The Create Pluggable Mapping Folder dialog box is displayed.
Enter a name and an optional description for the pluggable mapping folder.
To start the Create Pluggable Mapping wizard to create a pluggable mapping immediately after you create this pluggable mapping folder, select Proceed to Pluggable Mapping Wizard.
Click OK.
The library is displayed in the Projects Navigator. Create individual pluggable mappings within this library as described in "Creating Standalone Pluggable Mappings".
You can also move a pluggable mapping to any library on the tree.
Within a pluggable mapping library, you can create user folders to group pluggable mappings using criteria such as product line, functional groupings, or application-specific categories.
User folders can contain user folders and other pluggable mappings. There is no limit on the level of nesting of user folders. You can also move, delete, edit, or rename user folders.
You can move or copy a user folder and its contained objects to the same pluggable mapping library, to any user folder belonging to the same library, or to a user folder belonging to a different library.
Deleting a user folder removes the user folder and all its contained objects from the repository.
To create a user folder within a pluggable mapping library:
Right-click the pluggable mapping library or the user folder under which you want to create the user folder and select New.
The New Gallery dialog box is displayed.
In the Items section, select User Folder.
The Create User Folder dialog box is displayed.
Enter a name for the user folder and click OK.
The user folder is created and added to the tree.
To create a pluggable mapping within a user folder:
Right-click the user folder and select New.
The New Gallery dialog box is displayed.
In the Items section, select Pluggable Mapping.
To create a new user folder within this user folder, select User Folder.
Click OK.
If you selected Pluggable Mapping in Step 2, the Create Pluggable Mapping Wizard is displayed. If you selected User Folder in Step 2, then the Create User Folder dialog box is displayed.
You can move pluggable mappings from within a user folder or a pluggable mapping library to the Standalone node or to a different user folder or library. To move, right-click the pluggable mapping, select Cut. Right-click the user folder or pluggable mapping library to which you want to copy the pluggable mapping and select Paste.
Operators enable you to create user-defined transformation logic in a mapping or pluggable mapping. Sometimes, you may want to reuse an operator that you previously defined in another mapping or pluggable mapping. Oracle Warehouse Builder supports copy-and-paste reuse of existing transformation logic, defined using operators or operator attributes, in other mappings or pluggable mappings. In the remainder of this section, the term mappings includes both mappings and pluggable mappings.
You can reuse transformation logic by copying the operator or operator attributes from the source mapping and pasting them into the required mapping. You can also copy and paste operator groups (input, output, and I/O).
Steps to Copy Operators, Groups, or Attributes
Use the following steps to copy operators, groups, and attributes defined in a mapping to other mappings within the same project.
Open the mapping containing the operator, group, or attributes to copy. This is your source mapping.
Open the mapping into which you want to copy the operator, group, or attributes. This is your target mapping.
In the source mapping, select the operator, group, or attribute. From the Edit menu, select Copy. To select multiple attributes, hold down the Ctrl key while selecting attributes.
or
Right-click the operator, group, or attribute and select Copy. If you selected multiple attributes, then ensure that you hold down the Ctrl key while right-clicking.
Note:
If you do not require the operator, group, or attributes in the source mapping, you can choose Cut instead of Copy. Cutting removes the object from the source mapping.Cut objects can be pasted only once, whereas copied objects can be pasted multiple times.
In the target mapping, paste the operator, group, or attributes.
To paste an operator, select Paste from the Edit menu. Or, right-click any blank space on the canvas and select Paste from the shortcut menu.
To paste a group, first select the operator into which you want to paste the group and then select Paste from the Edit menu. Or, right-click the operator into which you want to paste the group and select Paste from the shortcut menu.
To paste attributes, select the group into which you want to paste the attribute and then select Paste from the Edit menu. Or, right-click the group into which you want to paste the group and select Paste from the shortcut menu.
When you copy and paste an operator, the new operator has a UOID that is different from the source operator.
If the target mapping contains an operator with the same name as the one that is being copied, an _n is appended to the name of the new operator. Here, n represents a sequence number that begins with 1.
Information Copied Across Mappings
When you copy an operator, group, or attribute to a target mapping, the following information is copied.
Object binding details
Display sets details
Physical and logical properties of operators and attributes
If there are multiple configurations defined for the object, details of all configurations are copied.
Note:
When you copy an attribute and paste it into an operator that is of a different type than the source operator, only the name and data type of the operator are copied. No other details are copied.Following are the limitations of copying operators, groups, and attributes:
You can copy operators, groups, or attributes from a mapping and paste them into another mapping within the same project only.
Any connections that existed between the operator, group, or attributes in the source mapping are not copied to the target mapping. Only the operator, group, or attributes are pasted into the target mapping.
For pluggable mappings, the connections between child operators within the source pluggable mapping are copied to the target mapping.
Group properties of the source operator are not copied to the group in the target operator. However, all the attributes contained in the group are copied.
Before you copy and paste a group from a source operator to a target operator, you must create the group in the target operator. The group is not created when you perform a paste operation.
Note:
Copying and pasting a large number of operators may take a considerable amount of time.Complex mappings and pluggable mappings contain many operators that are used to perform the required ETL task. Typically, each data transformation task may use one or more operators, which results in mappings that look cluttered and are difficult to comprehend. Trying to view all the operators at once means that each operator appears very small and the names are unreadable. Thus, grouping operators that perform related transformation tasks into separate folders helps reveal the overall transformation logic performed in the mapping. Oracle Warehouse Builder provides a method to group a set of operators into a folder so that unnecessary operators are hidden from the mapping canvas. In the remainder of this section, the term mappings refers to both mappings and pluggable mappings.
Grouping less interesting operators into a collapsible folder enables you to focus on the components that are important at a given time. It also uses less space on the canvas, thus enabling you to easily work on the mapping. When required, you can ungroup the folder to view or edit the operators that it contains.
Mappings can contain multiple grouped folder. You can also create nested folders in which one folder contains a set of mapping operators and one or more folders.
Use the following steps to group operators in mappings and pluggable mappings.
Open the mapping in which you want to group operators.
Select the operators to group.
To select multiple objects, hold down the Ctrl key while selecting objects. Or, hold down the left-mouse button and draw a rectangle that includes the objects you want to select.
In the toolbar at the top of the Mapping Editor canvas, click Group Selected Objects. Or, from the Graph menu, select Group Selected Objects.
The selected operators are grouped into a folder, and the collapsed folder is displayed in the Mapping Editor. A default name, such as Folder1, is used for the folder.
(Optional) Rename the folder so that the name is more intuitive and reflects the task that the group of operators performs.
To rename the folder:
Right-click the folder and select Open Details.
In the Edit Folder dialog box, enter the name of the folder in the Name field and click OK.
When you group operators to create a folder for the selected operators, you can view the operators contained in the folder using one of the following methods.
Use the tooltip for the folder
Position your mouse over the folder. The tooltip displays the operators contained in the folder.
Use Spotlighting to view folder contents
Select the folder and click Spotlight Selected Objects on the toolbar. Or, select the folder and choose Spotlight Selected Objects from the Graph menu. The folder is expanded, and the operators it contains are displayed. All other operators in the mapping are hidden. This is called spotlighting. For more information about spotlighting, see "Spotlighting Selected Operators".
Double-click the folder
Double-click the folder to expand it. All operators contained in the folder are displayed and the surrounding operators in the mapping are moved to accommodate the folder contents.
Use the following steps to ungroup operators.
Open the mapping in which you want to ungroup operators.
Select the folder to ungroup.
You can select multiple folders by holding down the Ctrl key and selecting all the folders.
In the toolbar, click Ungroup Selected Objects. Or, from the Graph menu, select Ungroup Selected Objects.
The operators that were grouped are now displayed individually on the Mapping Editor.
Spotlighting enables you to view only selected operators and their connections. All other operators and their connections are temporarily hidden. You can perform spotlighting on a single operator, a group of operators, a single folder, a group of folders, or any combination of folders and operators. When you select objects for spotlighting, the Mapping Editor layout is redisplayed such that the relationships between the selected objects are displayed clearly. The edges between spotlighted components are visible. However, edges between spotlighted components and other nonselected components are hidden.
To spotlight a folder containing grouped operators, in the Mapping Editor, select the folder and click Spotlight Selected Items on the toolbar. The folder is expanded and all the operators it contains are displayed. Click Spotlight Selected Objects again to toggle the spotlighting mode. The folder appears collapsed again and the operators it contains are hidden.
When in Spotlight mode, you can perform all normal mapping operations, such as moving or resizing operators, modifying operator properties, deleting spotlighted operators, creating new operators, and creating connections between operators. You can perform any operation that does not affect temporarily hidden operators.
If you create an operator in Spotlight mode, the operator must remain visible in the Mapping Editor when you toggle out of Spotlight mode.
Mappings and pluggable mappings contain numerous operators that are used to perform the required data transformation. Oracle Warehouse Builder provides a quick method of locating operators, groups, and attributes within mappings and pluggable mappings. When you search for objects, you can define the scope of the search and the search criteria. In the remainder of this section, the term mapping refers to both mappings and pluggable mappings.
You can perform the following types of search:
Regular Search
Oracle Warehouse Builder searches for the search string in all the operators within the mapping. The search string is matched with the display name of operators, group names, and attribute names.
Advanced Search
This is a more sophisticated method of locating objects in mappings. You can locate operators, groups, and attributes by specifying which objects should be searched, and the search criteria.
Use the Advanced Find dialog box to perform both regular and advanced searches.
Searching for Objects in Mappings and Pluggable Mappings
To locate an operator, group, or attribute in a mapping or pluggable mapping:
Open the mapping using the steps described in "Steps to Open a Previously Created Mapping".
From the Search menu, select Find.
The Advanced Find dialog box is displayed. Depending on the type of search to perform, use one of the following sets of instructions.
Performing regular search involves the following steps:
Performing an advanced search involves the following steps:
The Advanced Find dialog box enables you to search for operators, groups, or attributes within a mapping or pluggable mapping. By default, this dialog box displays the options required to perform a regular search. In a regular search, you search for an operator, group, or attribute using its display name. You can also specify how the search results should be displayed.
An advanced search provides techniques to define the scope of the search and the search criteria. To perform an advanced search, click Show Advanced. The additional parameters that you must define for an advanced search are displayed.
Specifying the Object to Locate
Use the Find field to specify the object to locate. A regular search locates objects containing the same display name as the one specified in the Find field.
While performing an advanced search, in addition to the display name, you can specify a string that you provided in the Description property, physical name, business name, or name of the workspace object to which an operator is bound.
You can use wildcards in the search criteria. For example, specifying "C*" in the Find field searches for an object whose name begins with C or c.
Specifying the Method Used to Display Search Results
Use the Turn On Highlighting button on the Advanced Find dialog box to specify the method used to display the search results. This is a toggle button, and you can turn highlighting on or off.
When you turn highlighting on, all objects located because of the search operation are highlighted in yellow in the Mapping Editor. Highlighting enables you to easily spot objects that are part of the search results.
This is the default behavior. When you turn off highlighting, objects located because of the search operation are identified by the control being moved to these objects. When control is on a particular object, the border around the object is blue. When highlighting is off, the search results are presented one at a time.
For example, if an operator is found because of the search, the borders of the node representing the operator are blue.
You can restrict the objects searched by specifying the scope of the search. The In Selected field in the Scope section enables you to limit the scope of the search to within the objects selected on the canvas.
To locate an object within a specific set of operators, you first select all the operators on the canvas and then choose In Selected. You can select multiple operators by holding down the Shift key while selecting operators.
Specifying the Search Criteria
To perform an advanced search, you must specify additional search criteria that further refines the search.
Find By
Use the Find By list to specify which name is necessary to search for an object. The options you can select are:
Display Name: Search either the physical names or the business names, depending on the Naming Mode set.
Physical Name: Search for an object containing the same physical name as the one specified in the Find field.
Business Name: Search for an object containing the same business name as the one specified in the Find field.
Bound Name: Search for an object containing the same bound name as the one specified in the Find field, if this property is available for the object.
Description: Search for an object containing the same description as the one specified in the Find field, if this property is defined for the object.
Use the Match Options section to specify the matching options used while finding the object. The options that you can select are:
Match Case: Locates objects whose name and case match the search string specified in the Find field.
When searching by physical name, match case is set to false by default.
In physical name mode, everything a user creates must be in uppercase, but the imported objects may be in mixed case.
When searching by logical name, match case is set to true by default.
Whole Word Only: Restricts matches to exclude those objects that do not match the entire search string, unless specifically overridden by a wildcard.
Regular Expression: Supports the specification of a pattern, used for a Java regular expression as the search string. If Regular Expression is combined with Whole Word Only, then a boundary matcher "$" is appended to the search string pattern.
For more information about regular expression support, see Oracle Database SQL Language Reference.
Specifies options for managing the search operation. Select one of the following options:
Incremental: Performs a search after any character is typed or if characters are removed from the search string. Use the Find button to find additional objects that match the search string
Wrap Find: Continues the search operation with the first object when the last object in the set has been reached.
Find from Beginning: Continues the search with the first object in the set.
Use this section to restrict the scope of the search.
In Selected: Select this option to locate the search string only among the objects currently selected in the Mapping Editor.
Use the Direction section to step through the objects in the search result set either forward or backward. Select Next to step forward through the result set and Previous to step backward through the result set.
You can use the Mapping Editor to debug complex data flows that you design in mappings. Once you begin a debug session and connect to a valid target schema, the debugging functions appear on the Mapping Editor toolbar and under Log window. You can run a debugging session using a defined set of test data, and follow the flow of data as it is extracted, transformed, and loaded to ensure that the designed data flow performs as expected. If you find problems, then you can correct them and restart the debug session to ensure that the problems have been fixed before proceeding to deployment.
When you modify a mapping that is being debugged, the mapping properties are changed. Unless display sets in operators are modified, the Mapping Debugger reinitializes to reflect the changes to the mapping.
Ensure that you are connected to a Control Center and that the Control Center is running.
The following restrictions and limitations apply to the Mapping Debugger.
Mappings run using the debug mode in the Mapping Editor are intended to be used for debug purposes only. Mappings run from the Mapping Editor do not perform and mappings that are run from the Control Center. This is attributed to the setup of temporary objects necessary to support the debugging capabilities. Use the Control Center to run mappings.
You cannot pause an active debug run using the Pause button on the toolbar or the associated item in the debug menu.
You cannot use the Repository Browser to view the results of a mapping run in debug mode.
Only mappings that can be implemented as a PL/SQL package can currently be run in debug mode. ABAP mappings are not supported in the debugger.
The Advanced Queue operator is not supported when you run mappings in debug mode.
To start a debug session, open the mapping to debug in the Mapping Editor. From the Debug menu, select Start. Or, click Start on the Mapping Editor toolbar. The Mapping Editor switches to debug mode with the debug panels appearing in the Log window, and the debugger connects to the appropriate Control Center for the project. The debug-generated code is deployed to the target schema specified by the location of the module that contains the map being debugged.
Note:
When the connection cannot be made, an error message is displayed and you have an option to edit the connection information and retry.After the connection has been established, a message appears, indicating that you may want to define test data. When you have previously defined test data, then you are asked to continue with initialization.
To debug a mapping, each source or target operator must be bound to a database object. Defining test data for the source and target operators is optional. By default, the debugger uses the same source and target data that is currently defined for the non-debug deployment of the map.
When the Mapping Editor is opened in Debug mode, the Log window displays two new panels: "Info Panel" and "Data Panel".
When the Mapping Editor is in Debug mode, the Info panel in the Log window contains the following tabs:
Messages: Displays all debugger operation messages. These messages let you know the status of the debug session. This includes any error messages that occur while running the mapping in debug mode.
Breakpoints: Displays a list of all breakpoints that you have set in the mapping. You can use the check boxes to activate and deactivate breakpoints. For more information, see "Setting Breakpoints".
Test Data: Displays a list of all data objects used in the mapping. The list also indicates which data objects have test data defined.
When the Mapping Editor is in Debug mode, the Data panel is displayed in the Log window. The Data panel includes Step Data and watch point tabs, that contain input and output information for the operators being debugged. The Step Data tab contains information about the current step in the debug session. Additional tabs can be added for each watch that you set. These watch tabs enable you to keep track of and view data that has passed or should pass through an operator regardless of the currently active operator in the debug session. Operators that have multiple input group or multiple output group display an additional list that enables you to select a specific group.
If an operator has multiple input or output group then the debugger must have a list in the upper-right corner, above the input or output groups. Use this list to select the group you are interested in. This applies both to the step data and to a watch.
Every source or target operator in the mapping is listed on the Test Data tab in the lower Info tab panel. It also contains the object type, the source, and a check mark that indicates whether the database object has been bound to the source or target operator.
The object type listed on the tab is determined by whether the column names in the data source that you select (for example, a table) matches the columns in the mapping operators. There are two possible types:
Direct Access. When there is an exact match, the type is listed as Direct Access.
Deployed as View. When you choose a data source with columns that do not match the mapping operator columns, you can choose how you want the columns mapped. This object is deployed as a view when you run the mapping and the type is listed as Deployed as View.
Click Edit to add or change the binding of an operator and the test data in the bound database objects. Before you can run the mapping in debug mode, each listed source or target operator must be bound and have a check mark. The requirement to have test data defined and available in the bound database object depends on what aspect of the data flow you are interested in focusing on when running the debug session. Typically, you should need test data for all source operators. Test data for target operators is usually necessary to debug loading scenarios that involve updates or target constraints.
To define or edit test data:
From the Test Data tab in the Mapping Editor, select an operator from the list and click Edit. The Define Test Data dialog box is displayed.
In the Define Test Data dialog box, specify the characteristics of the test data Oracle Warehouse Builder to use when it debugs. There are many characteristics that you can specify. For example, you can specify that the test data be from a new or existing database object or that you can or cannot manually edit the test data. Click Help on the Define Test Data dialog box for more information.
When you create a new table using the Define Test Data dialog box, Oracle Warehouse Builder creates the table in the target schema that you specified when you started the debug run. Because the debugger does not automatically drop this table when you end the debug session, you can reuse it for other sessions. Constraints are not carried over for the new table. However, all other staging tables created by the debug session are dropped when the debug session ends.
When you create a new table, Oracle Warehouse Builder creates the new table in the connected run time schema. The new table has an automatically generated name, and the value of the Debug Binding name changes to reflect the new table name. The new table has columns defined for it that exactly match the names and data types of the mapping source or target attributes. In addition, any data that is displayed in the grid at the time the table is created is copied into the newly created table.
You can use both scalar and user-defined data types in tables that you create using the Define Test Data dialog box.
You can edit test data at any time using the Define Test Data dialog box. Editing test data is applicable for scalar data types only.
If you change the binding of the operator to another database object, you must reinitialize the debug session to implement the change before running the mapping again in debug mode.
Note:
The data loaded in the target definitions are implicitly committed. If you do not want the target objects updated, then you should create copies of target objects by clicking Create New Table.Debug tables, with names prefixed with DBG$, are created in the run time schema when you debug mappings. Because multiple users, using multiple instances, can debug the same mapping, debug objects are created separately for each debug session. The debug objects for a session are automatically dropped after the session. However, if the user abruptly exits the Design Center without exiting the mapping debugger, the debug objects for the debug session in progress are not dropped, and become stale objects.
However, you can clean up all debug objects in the run time schema by using the OWB_HOME/bin/admin/cleanupalldebugobjects.sql script. This script drops all the stale objects prefixed by DBG$ in the run time repository user schema.
This script should be run by an Oracle Warehouse Builder user with administrator privileges. Before you run this script, determine if all the objects that are prefixed by DBG$ in the run time user schema are stale. Because the same mapping can be debugged using multiple instances, running this script causes disruptions for other users debugging the same mapping.
If you are interested in how a specific operator is processing data, you can set a breakpoint on that operator to cause a break in the debug session. It enables you to proceed quickly to a specific operator in the data flow without having to go through all the operators step by step. When the debug session gets to the breakpoint, you can run data through the operator step by step to ensure that it is functioning as expected.
To set or remove a breakpoint:
From the Mapping Editor, click an operator, select Debug, and then select Set Breakpoint. You can also click Set Breakpoint on the toolbar to toggle the breakpoint on and off for the currently highlighted operator.
If you are setting the breakpoint, the name of the operator set as a breakpoint appears in the list on the Breakpoints tab on the Info panel. If you are removing the breakpoint, then the name is removed. Use the Clear button on the Breakpoint tab to remove breakpoints.
Deselect or select the breakpoints on the Breakpoint tab to disable or enable them.
The Step Data tab on the "Data Panel" always shows the data for the current operator. To keep track of data that has passed through any other operator irrespective of the active operator, you can set a watch.
Use watches to track data that has passed through an operator or for sources and targets, the data that currently resides in the bound database objects. You can also set watches on operators after the debug run has passed the operator and look back to see how the data was processed by an operator in the data flow.
To set a watch:
From the Mapping Editor, select an operator. From the Debug menu, select Set Watch. You can also select the operator and click Set Watch on the Mapping Editor toolbar to toggle the watch on and off.
A separate Watch panel is displayed to view data for Constant, Mapping Input, Mapping Output, Pre Mapping, Post Mapping, and Sequence operators. Since these operators contain lesser information than other operators, information regarding multiple of these operators is displayed in the Watch panel. Thus, only one instance of Watch panel is displayed for these operators if you choose to watch values.
To remove a watch:
To remove a watch, select the operator on the Mapping Editor canvas. Then, click Set Watch on the Mapping Editor toolbar or select Set Watch from the Debug menu.
If a watch panel consists of non-data based operators such as Constant, Mapping Input, Mapping Output, Pre Mapping, Post Mapping, and Sequence, you can remove these operators by right-clicking the operator and selecting Remove. You can remove all these operators by closing the Watch panel.
When you set a watch for an operator, Oracle Warehouse Builder automatically saves the watch points for this operator, unless you close the watch panels. When you end the debug session and start again, the tabs for operator watches that you created are displayed.
If you do not want to save watch points, click Set Watch in the Mapping Debugger toolbar or close the tab related to the Watch point.
After you have defined the test data connections for each of the data operators, you can initially generate the debug code by selecting Reinitialize from the Debug menu, or by clicking Reinitialize on the Mapping Editor toolbar. Oracle Warehouse Builder generates the debug code and deploys the package to the target schema that you specified.
You can run the debug session in one of the following modes:
Continue processing until the next breakpoint or until the debug run finishes by using the Resume button on the toolbar or the associated menu item.
Process row by row using the Step button on the toolbar or the associated menu item.
Process all remaining rows for the current operator by using the Skip button on the toolbar or the associated menu item.
Reset the debug run and go back to the beginning by using the Reset button or the associated item from the Debug menu.
A mapping may have multiple source and multiple path to debug:
When a mapping has multiple source, Oracle Warehouse Builder prompts you to designate the source with which to begin. For example, when two tables are mapped to a joiner, you must select the first source table to use when debugging.
There may be multiple paths that the debugger can walk through after it has finished one path. For example, this is the case when you use a splitter. Having finished one path, the debugger asks you whether you would like to complete the other paths as well.
The mapping finishes if all target operators have been processed or if the maximum number of errors as configured for the mapping has been reached. The debug connection and test data definitions are stored when you commit changes to Oracle Warehouse Builder workspace. Breakpoint and watch settings are stored when you save the project.
As the debugger runs, it generates debug messages whenever applicable. You can follow the data flow through the operators. A red dashed box surrounds the active operator.
How a mapping is debugged depends on whether the mapping has the Correlated Commit parameter set to ON or OFF:
When you begin a debug session for a mapping that has the Correlated Commit parameter set to ON, the mapping is not debugged using paths. Instead, all paths are run and all targets are loaded during the initial stepping through the mapping regardless of what path is chosen. Also, if one of the targets has a constraint violation for the step, then none of the targets are loaded for that step.
When you begin a debug session for a mapping that has the Correlated Commit parameter set to OFF, the mapping is debugged using one path at a time. All other paths are left unexecuted and all other targets are not loaded unless you reach the end of the original path and return to run another path in the mapping.
For example, you have a mapping that has a source, S1, connected to a splitter that goes to two targets, T1 and T2:
If Correlated Commit is OFF, then the mapping is debugged starting with S1. You can then choose either the path going to T1 or the path going to T2. If you choose the path to T1, then the data going to T1 is processed and displayed, and the target T1 is loaded. After T1 is completely loaded, you are given the option to go back, run the other path, and load target T2.
If Correlated Commit is ON, then the mapping is also debugged starting with S1, and you are given the option of choosing a path however in this case, the path you choose only determines the path that gets displayed in the Mapping Editor as you step through the data. All paths are run simultaneously. This is also how a mapping using Correlated Commit is run when the deployable code is run.
You can select an operator as a starting point, even if it is not a source. To set an operator as a starting point, start a debug session, then select the operator and click Set as Starting Point on the Mapping Editor toolbar. Or, from the Debug menu, select Set as Starting Point.
When an operator is set as a starting point, Oracle Warehouse Builder combines all the upstream operators and sources into a single query, which is used as a source, and the operator is automatically used as the first source when stepping through the map. The operators that are upstream of the starting point operator are not steppable, and do not have displayable data, even if a watch point is set.
A good use of "set as starting point" would be for a mapping with three source tables that were all connected to a single Joiner operator. Each source table contains a large number of rows (more than 50000 rows), too many rows to efficiently step through in the debugger. In this case, set the Joiner operator as a starting point, and limit the row count for one of the source tables to a more manageable number of rows (500) by using the Test Data Editor. It would be best to limit the row count of the source table that is effectively driving the joiner (that is, the source with which all the other sources are joined in the join condition).
You can also debug a map which contains one or more pluggable submap operators. This could include a user-defined pluggable submap operator from the pluggable folder, or a system-defined submap operator. When the debug session is started, the mapping passes through debug initialization and start stepping at the first executable operator, just as usual.
While stepping through the operator, the debugger reaches a pluggable submap operator, then that operator is highlighted as the current step operator just like any other operator. If you click Step at this point, then the debugger steps through all of the operators contained by the pluggable submap without changing the graphical context of the map to show the implementation of the pluggable map. If you click Step Into, then the graphical context of the map changes to the pluggable mapping implementation, and the current step operator is set to the first executable source operator inside the pluggable mapping. The first executable source operator for the pluggable submap is one of the operators connected from the input signature operator.
You can now step through the pluggable mapping just as you would any other type of map. When the pluggable submap operator contains targets, the debugger loads theses just as it does for a top-level map. When the final executable operator is done executing, then the next time you click Step, the context changes back to the top-level map and begins execution at the next executable operator following the pluggable submap that was just run. When the pluggable submap has no output connections, and it is the final executable operator in the top-level map, then stepping is done.
You can set breakpoints and watch points on operators inside of a pluggable submap. Additionally, during normal editing, you can change the graphical context as you do in normal editing, by clicking Visit Child Graph and Return to Parent Graph.
When you have made changes to the mapping, or have bound source or target operators to different database objects, then you must reinitialize the debug session to continue debugging the mapping with the new changes. To reinitialize, click Reinitialize on the toolbar or select Reinitialize from the Debug menu. Reinitializing both regenerates and redeploys the debug code. After reinitialization, the mapping debug session starts from the beginning.
Scalability when debugging a mapping applies both to the amount of data that is passed and to the number of columns displayed in the Step Data panel. The Define Test Data dialog box provides a row limit that you can use to limit the amount of data that flows through the mapping. Also, you can define your own data set by creating your own table and manipulating the records manually.
To restrict the number of columns displayed on the Step Data tab, or on a watch tab, you can use display sets. By default, every operator has a display set ALL and a display set MAPPED (to display only the mapped attributes). You can manually add display sets on sources by using the Mapping Editor directly. Select the Use Display Set option under the right mouse button on an input or output group to select the display set.
|
Copyright © 2000, 2011, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|