| Oracle® Database Concepts 11g Release 2 (11.2) E40540-01 |
|
|
PDF · Mobi · ePub |
| Oracle® Database Concepts 11g Release 2 (11.2) E40540-01 |
|
|
PDF · Mobi · ePub |
This chapter provides an overview of the Structured Query Language (SQL) and how Oracle Database processes SQL statements.
This chapter includes the following topics:
SQL (pronounced sequel) is the set-based, high-level declarative computer language with which all programs and users access data in an Oracle database. Although some Oracle tools and applications mask SQL use, all database operations are performed using SQL. Any other data access method circumvents the security built into Oracle Database and potentially compromises data security and integrity.
SQL provides an interface to a relational database such as Oracle Database. SQL unifies tasks such as the following in one consistent language:
Creating, replacing, altering, and dropping objects
Inserting, updating, and deleting table rows
Controlling access to the database and its objects
SQL can be used interactively, which means that statements are entered manually into a program. SQL statements can also be embedded within a program written in a different language such as C or Java.
See Also:
Oracle Database SQL Language Reference for an introduction to SQL
"Introduction to Server-Side Programming" and "Client-Side Database Programming"
There are two broad families of computer languages: declarative languages that are nonprocedural and describe what should be done, and procedural languages such as C++ and Java that describe how things should be done. SQL is declarative in the sense that users specify the result that they want, not how to derive it. The SQL language compiler performs the work of generating a procedure to navigate the database and perform the desired task.
SQL enables you to work with data at the logical level. You need be concerned with implementation details only when you want to manipulate the data. For example, the following statement queries records for employees whose last name begins with K:
SELECT last_name, first_name FROM hr.employees WHERE last_name LIKE 'K%' ORDER BY last_name, first_name;
The database retrieves all rows satisfying the WHERE condition, also called the predicate, in a single step. These rows can be passed as a unit to the user, to another SQL statement, or to an application. You do not need to process the rows one by one, nor are you required to know how the rows are physically stored or retrieved.
All SQL statements use the optimizer, a part of Oracle Database that determines the most efficient means of accessing the specified data. Oracle Database also supports techniques that you can use to make the optimizer perform its job better.
See Also:
Oracle Database SQL Language Reference for detailed information about SQL statements and other parts of SQL (such as operators, functions, and format models)Oracle strives to follow industry-accepted standards and participates actively in SQL standards committees. Industry-accepted committees are the American National Standards Institute (ANSI) and the International Organization for Standardization (ISO). Both ANSI and the ISO/IEC have accepted SQL as the standard language for relational databases.
The latest SQL standard was adopted in July 2003 and is often called SQL:2003. One part of the SQL standard, Part 14, SQL/XML (ISO/IEC 9075-14) was revised in 2006 and is often referred to as SQL/XML:2006.
Oracle SQL includes many extensions to the ANSI/ISO standard SQL language, and Oracle Database tools and applications provide additional statements. The tools SQL*Plus, SQL Developer, and Oracle Enterprise Manager enable you to run any ANSI/ISO standard SQL statement against an Oracle database and any additional statements or functions available for those tools.
See Also:
Oracle Database SQL Language Reference for an explanation of the differences between Oracle SQL and standard SQL
SQL*Plus User's Guide and Reference for SQL*Plus commands, including their distinction from SQL statements
"Tools for Database Administrators" and "Tools for Database Developers"
All operations performed on the information in an Oracle database are run using SQL statements. A SQL statement is a computer program or instruction that consists of identifiers, parameters, variables, names, data types, and SQL reserved words.
Note:
SQL reserved words have special meaning in SQL and should not be used for any other purpose. For example,SELECT and UPDATE are reserved words and should not be used as table names.A SQL statement must be the equivalent of a complete SQL sentence, such as:
SELECT last_name, department_id FROM employees
Oracle Database only runs complete SQL statements. A fragment such as the following generates an error indicating that more text is required:
SELECT last_name;
Oracle SQL statements are divided into the following categories:
Data definition language (DDL) statements define, structurally change, and drop schema objects. For example, DDL statements enable you to:
Create, alter, and drop schema objects and other database structures, including the database itself and database users. Most DDL statements start with the keywords CREATE, ALTER, or DROP.
Delete all the data in schema objects without removing the structure of these objects (TRUNCATE).
Add a comment to the data dictionary (COMMENT).
DDL enables you to alter attributes of an object without altering the applications that access the object. For example, you can add a column to a table accessed by a human resources application without rewriting the application. You can also use DDL to alter the structure of objects while database users are performing work in the database.
Example 7-1 uses DDL statements to create the plants table and then uses DML to insert two rows in the table. The example then uses DDL to alter the table structure, grant and revoke privileges on this table to a user, and then drop the table.
CREATE TABLE plants
( plant_id NUMBER PRIMARY KEY,
common_name VARCHAR2(15) );
INSERT INTO plants VALUES (1, 'African Violet'); # DML statement
INSERT INTO plants VALUES (2, 'Amaryllis'); # DML statement
ALTER TABLE plants ADD
( latin_name VARCHAR2(40) );
GRANT SELECT ON plants TO scott;
REVOKE SELECT ON plants FROM scott;
DROP TABLE plants;
An implicit COMMIT occurs immediately before the database executes a DDL statement and a COMMIT or ROLLBACK occurs immediately afterward. In Example 7-1, two INSERT statements are followed by an ALTER TABLE statement, so the database commits the two INSERT statements. If the ALTER TABLE statement succeeds, then the database commits this statement; otherwise, the database rolls back this statement. In either case the two INSERT statements have already been committed.
See Also:
"Overview of Database Security" to learn about privileges and roles
Oracle Database 2 Day Developer's Guide and Oracle Database Administrator's Guide to learn how to create schema objects
Oracle Database SQL Language Reference for a list of DDL statements
Data manipulation language (DML) statements query or manipulate data in existing schema objects. Whereas DDL statements enable you to change the structure of the database, DML statements enable you to query or change the contents. For example, ALTER TABLE changes the structure of a table, whereas INSERT adds one or more rows to the table.
DML statements are the most frequently used SQL statements and enable you to:
Retrieve or fetch data from one or more tables or views (SELECT).
Add new rows of data into a table or view (INSERT) by specifying a list of column values or using a subquery to select and manipulate existing data.
Change column values in existing rows of a table or view (UPDATE).
Update or insert rows conditionally into a table or view (MERGE).
View the execution plan for a SQL statement (EXPLAIN PLAN). See "How Oracle Database Processes DML".
Lock a table or view, temporarily limiting access by other users (LOCK TABLE).
The following example uses DML to query the employees table. The example uses DML to insert a row into employees, update this row, and then delete it:
SELECT * FROM employees; INSERT INTO employees (employee_id, last_name, email, job_id, hire_date, salary) VALUES (1234, 'Mascis', 'JMASCIS', 'IT_PROG', '14-FEB-2011', 9000); UPDATE employees SET salary=9100 WHERE employee_id=1234; DELETE FROM employees WHERE employee_id=1234;
A collection of DML statements that forms a logical unit of work is called a transaction. For example, a transaction to transfer money could involve three discrete operations: decreasing the savings account balance, increasing the checking account balance, and recording the transfer in an account history table. Unlike DDL statements, DML statements do not implicitly commit the current transaction.
See Also:
Oracle Database 2 Day Developer's Guide to learn how to query and manipulate data
Oracle Database SQL Language Reference for a list of DML statements
A query is an operation that retrieves data from a table or view. SELECT is the only SQL statement that you can use to query data. The set of data retrieved from execution of a SELECT statement is known as a result set.
Table 7-1 shows two required keywords and two keywords that are commonly found in a SELECT statement. The table also associates capabilities of a SELECT statement with the keywords.
Table 7-1 Keywords in a SQL Statement
| Keyword | Required? | Description | Capability |
|---|---|---|---|
|
|
Yes |
Specifies which columns should be shown in the result. Projection produces a subset of the columns in the table. An expression is a combination of one or more values, operators, and SQL functions that resolves to a value. The list of expressions that appears after the |
Projection |
|
|
Yes |
Specifies the tables or views from which the data should be retrieved. |
Joining |
|
|
No |
Specifies a condition to filter rows, producing a subset of the rows in the table. A condition specifies a combination of one or more expressions and logical (Boolean) operators and returns a value of |
Selection |
|
|
No |
Specifies the order in which the rows should be shown. |
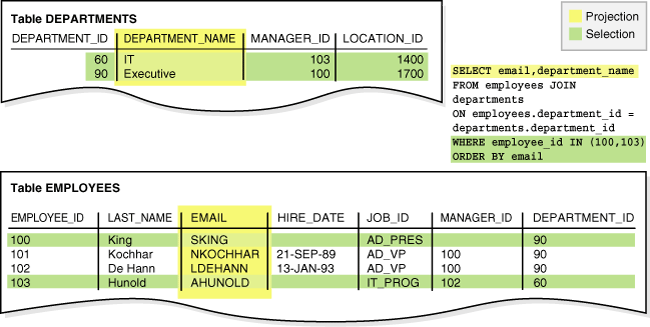
A join is a query that combines rows from two or more tables, views, or materialized views. Example 7-2 joins the employees and departments tables (FROM clause), selects only rows that meet specified criteria (WHERE clause), and uses projection to retrieve data from two columns (SELECT). Sample output follows the SQL statement.
SELECT email, department_name FROM employees JOIN departments ON employees.department_id = departments.department_id WHERE employee_id IN (100,103) ORDER BY email; EMAIL DEPARTMENT_NAME ------------------------- ------------------------------ AHUNOLD IT SKING Executive
Figure 7-1 graphically represents the operations of projection and selection in the join shown in Example 7-2.
Most joins have at least one join condition, either in the FROM clause or in the WHERE clause, that compares two columns, each from a different table. The database combines pairs of rows, each containing one row from each table, for which the join condition evaluates to TRUE. The optimizer determines the order in which the database joins tables based on the join conditions, indexes, and any available statistics for the tables.
Join types include the following:
An inner join is a join of two or more tables that returns only rows that satisfy the join condition. For example, if the join condition is employees.department_id=departments.department_id, then rows that do not satisfy this condition are not returned.
Outer joins
An outer join returns all rows that satisfy the join condition and also returns rows from one table for which no rows from the other table satisfy the condition. For example, a left outer join of employees and departments retrieves all rows in the employees table even if there is no match in departments. A right outer join retrieves all rows in departments even if there is no match in employees.
Cartesian products
If two tables in a join query have no join condition, then the database returns their Cartesian product. Each row of one table combines with each row of the other. For example, if employees has 107 rows and departments has 27, then the Cartesian product contains 107*27 rows. A Cartesian product is rarely useful.
See Also:
Oracle Database SQL Language Reference for detailed descriptions and examples of joinsA subquery is a SELECT statement nested within another SQL statement. Subqueries are useful when you must execute multiple queries to solve a single problem.
Each query portion of a statement is called a query block. In Example 7-3, the subquery in parentheses is the inner query block. The inner SELECT statement retrieves the IDs of departments with location ID 1800. These department IDs are needed by the outer query block, which retrieves names of employees in the departments whose IDs were supplied by the subquery.
SELECT first_name, last_name FROM employees WHERE department_id IN (SELECT department_id FROM departments WHERE location_id = 1800);
The structure of the SQL statement does not force the database to execute the inner query first. For example, the database could rewrite the entire query as a join of employees and departments, so that the subquery never executes by itself. As another example, the Virtual Private Database (VPD) feature could restrict the query of employees using a WHERE clause, so that the database decides to query the employees first and then obtain the department IDs. The optimizer determines the best sequence of steps to retrieve the requested rows.
An implicit query is a component of a DML statement that retrieves data without using a subquery. An UPDATE, DELETE, or MERGE statement that does not explicitly include a SELECT statement uses an implicit query to retrieve rows to be modified. For example, the following statement includes an implicit query for the Baer record:
UPDATE employees SET salary = salary*1.1 WHERE last_name = 'Baer';
The only DML statement that does not necessarily include a query component is an INSERT statement with a VALUES clause. For example, an INSERT INTO TABLE mytable VALUES (1) statement does not retrieve rows before inserting a row.
See Also:
"Virtual Private Database (VPD)"Transaction control statements manage the changes made by DML statements and group DML statements into transactions. These statements enable you to:
Undo the changes in a transaction, since the transaction started (ROLLBACK) or since a savepoint (ROLLBACK TO SAVEPOINT). A savepoint is a user-declared intermediate marker within the context of a transaction.
Note:
TheROLLBACK command ends a transaction, but ROLLBACK TO SAVEPOINT does not.Specify whether a deferrable integrity constraint is checked following each DML statement or when the transaction is committed (SET CONSTRAINT).
The following example starts a transaction named Update salaries. The example creates a savepoint, updates an employee salary, and then rolls back the transaction to the savepoint. The example updates the salary to a different value and commits.
SET TRANSACTION NAME 'Update salaries'; SAVEPOINT before_salary_update; UPDATE employees SET salary=9100 WHERE employee_id=1234 # DML ROLLBACK TO SAVEPOINT before_salary_update; UPDATE employees SET salary=9200 WHERE employee_id=1234 # DML COMMIT COMMENT 'Updated salaries';
Session control statements dynamically manage the properties of a user session. As explained in "Connections and Sessions", a session is a logical entity in the database instance memory that represents the state of a current user login to a database. A session lasts from the time the user is authenticated by the database until the user disconnects or exits the database application.
Session control statements enable you to:
Alter the current session by performing a specialized function, such as enabling and disabling SQL tracing (ALTER SESSION).
Enable and disable roles, which are groups of privileges, for the current session (SET ROLE).
The following example turns on SQL tracing for the session and then enables all roles granted in the current session except dw_manager:
ALTER SESSION SET SQL_TRACE = TRUE; SET ROLE ALL EXCEPT dw_manager;
Session control statements do not implicitly commit the current transaction.
System control statements change the properties of the database instance. The only system control statement is ALTER SYSTEM. It enables you to change settings such as the minimum number of shared servers, terminate a session, and perform other system-level tasks.
Following are examples of system control statements:
ALTER SYSTEM SWITCH LOGFILE; ALTER SYSTEM KILL SESSION '39, 23';
The ALTER SYSTEM statement does not implicitly commit the current transaction.
Embedded SQL statements incorporate DDL, DML, and transaction control statements within a procedural language program. They are used with the Oracle precompilers. Embedded SQL is one approach to incorporating SQL in your procedural language applications. Another approach is to use a procedural API such as Open Database Connectivity (ODBC) or Java Database Connectivity (JDBC).
Embedded SQL statements enable you to:
Define, allocate, and release cursors (DECLARE CURSOR, OPEN, CLOSE).
Specify a database and connect to it (DECLARE DATABASE, CONNECT).
Initialize descriptors (DESCRIBE).
Specify how error and warning conditions are handled (WHENEVER).
Parse and run SQL statements (PREPARE, EXECUTE, EXECUTE IMMEDIATE).
To understand how Oracle Database processes SQL statements, it is necessary to understand the part of the database called the optimizer (also known as the query optimizer or cost-based optimizer). All SQL statements use the optimizer to determine the most efficient means of accessing the specified data.
To execute a DML statement, Oracle Database may have to perform many steps. Each step either retrieves rows of data physically from the database or prepares them for the user issuing the statement.
Many different ways of processing a DML statement are often possible. For example, the order in which tables or indexes are accessed can vary. The steps that the database uses to execute a statement greatly affect how quickly the statement runs. The optimizer generates execution plans describing possible methods of execution.
The optimizer determines which execution plan is most efficient by considering several sources of information, including query conditions, available access paths, statistics gathered for the system, and hints. For any SQL statement processed by Oracle, the optimizer performs the following operations:
Evaluation of expressions and conditions
Inspection of integrity constraints to learn more about the data and optimize based on this metadata
Statement transformation
Choice of optimizer goals
Choice of join orders
The optimizer generates most of the possible ways of processing a query and assigns a cost to each step in the generated execution plan. The plan with the lowest cost is chosen as the query plan to be executed.
Note:
You can obtain an execution plan for a SQL statement without executing the plan. Only an execution plan that the database actually uses to execute a query is correctly termed a query plan.You can influence optimizer choices by setting the optimizer goal and by gathering representative statistics for the optimizer. For example, you may set the optimizer goal to either of the following:
Total throughput
The ALL_ROWS hint instructs the optimizer to get the last row of the result to the client application as fast as possible.
Initial response time
The FIRST_ROWS hint instructs the optimizer to get the first row to the client as fast as possible.
A typical end-user, interactive application would benefit from initial response time optimization, whereas a batch-mode, non-interactive application would benefit from total throughput optimization.
See Also:
Oracle Database PL/SQL Packages and Types Reference for information about using DBMS_STATS
Oracle Database Performance Tuning Guide for more information about the optimizer and using hints
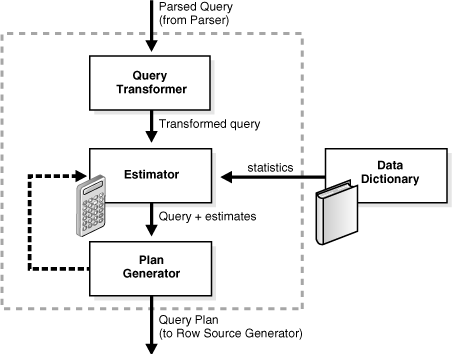
The optimizer contains three main components, which are shown in Figure 7-2.
The input to the optimizer is a parsed query (see "SQL Parsing"). The optimizer performs the following operations:
The optimizer receives the parsed query and generates a set of potential plans for the SQL statement based on available access paths and hints.
The optimizer estimates the cost of each plan based on statistics in the data dictionary. The cost is an estimated value proportional to the expected resource use needed to execute the statement with a particular plan.
The optimizer compares the costs of plans and chooses the lowest-cost plan, known as the query plan, to pass to the row source generator (see "SQL Row Source Generation").
The query transformer determines whether it is helpful to change the form of the query so that the optimizer can generate a better execution plan. The input to the query transformer is a parsed query, which is represented by a set of query blocks.
See Also:
"Query Rewrite"The estimator determines the overall cost of a given execution plan. The estimator generates three different types of measures to achieve this goal:
Selectivity
This measure represents a fraction of rows from a row set. The selectivity is tied to a query predicate, such as last_name='Smith', or a combination of predicates.
Cardinality
Cost
This measure represents units of work or resource used. The query optimizer uses disk I/O, CPU usage, and memory usage as units of work.
If statistics are available, then the estimator uses them to compute the measures. The statistics improve the degree of accuracy of the measures.
The plan generator tries out different plans for a submitted query and picks the plan with the lowest cost. The optimizer generates subplans for each of the nested subqueries and unmerged views, which is represented by a separate query block. The plan generator explores various plans for a query block by trying out different access paths, join methods, and join orders.
The optimizer automatically manages plans and ensures that only verified plans are used. SQL Plan Management (SPM) allows controlled plan evolution by only using a new plan after it has been verified to be perform better than the current plan.
Diagnostic tools such as the EXPLAIN PLAN statement enable you to view execution plans chosen by the optimizer. EXPLAIN PLAN shows the query plan for the specified SQL query if it were executed now in the current session. Other diagnostic tools are Oracle Enterprise Manager and the SQL*Plus AUTOTRACE command. Example 7-6 shows the execution plan of a query when AUTOTRACE is enabled.
See Also:
Oracle Database SQL Language Reference to learn about EXPLAIN PLAN
Oracle Database Performance Tuning Guide to learn about the optimizer components
An access path is the way in which data is retrieved from the database. For example, a query that uses an index has a different access path from a query that does not. In general, index access paths are best for statements that retrieve a small subset of table rows. Full scans are more efficient for accessing a large portion of a table.
The database can use several different access paths to retrieve data from a table. The following is a representative list:
This type of scan reads all rows from a table and filters out those that do not meet the selection criteria. The database sequentially scans all data blocks in the segment, including those under the high water mark that separates used from unused space (see "Segment Space and the High Water Mark").
Rowid scans
The rowid of a row specifies the data file and data block containing the row and the location of the row in that block. The database first obtains the rowids of the selected rows, either from the statement WHERE clause or through an index scan, and then locates each selected row based on its rowid.
Index scans
This scan searches an index for the indexed column values accessed by the SQL statement (see "Index Scans"). If the statement accesses only columns of the index, then Oracle Database reads the indexed column values directly from the index.
Cluster scans
A cluster scan is used to retrieve data from a table stored in an indexed table cluster, where all rows with the same cluster key value are stored in the same data block (see "Overview of Indexed Clusters"). The database first obtains the rowid of a selected row by scanning the cluster index. Oracle Database locates the rows based on this rowid.
Hash scans
A hash scan is used to locate rows in a hash cluster, where all rows with the same hash value are stored in the same data block (see "Overview of Hash Clusters". The database first obtains the hash value by applying a hash function to a cluster key value specified by the statement. Oracle Database then scans the data blocks containing rows with this hash value.
The optimizer chooses an access path based on the available access paths for the statement and the estimated cost of using each access path or combination of paths.
See Also:
Oracle Database 2 Day + Performance Tuning Guide and Oracle Database Performance Tuning Guide to learn about access pathsOptimizer statistics are a collection of data that describe details about the database and the objects in the database. The statistics provide a statistically correct picture of data storage and distribution usable by the optimizer when evaluating access paths.
Optimizer statistics include the following:
Table statistics
These include the number of rows, number of blocks, and average row length.
Column statistics
These include the number of distinct values and nulls in a column and the distribution of data.
Index statistics
These include the number of leaf blocks and index levels.
System statistics
These include CPU and I/O performance and utilization.
Oracle Database gathers optimizer statistics on all database objects automatically and maintains these statistics as an automated maintenance task. You can also gather statistics manually using the DBMS_STATS package. This PL/SQL package can modify, view, export, import, and delete statistics.
Optimizer statistics are created for the purposes of query optimization and are stored in the data dictionary. These statistics should not be confused with performance statistics visible through dynamic performance views.
See Also:
Oracle Database 2 Day + Performance Tuning Guide and Oracle Database Performance Tuning Guide to learn how to gather and manage statistics
Oracle Database PL/SQL Packages and Types Reference to learn about DBMS_STATS
A hint is a comment in a SQL statement that acts as an instruction to the optimizer. Sometimes the application designer, who has more information about a particular application's data than is available to the optimizer, can choose a more effective way to run a SQL statement. The application designer can use hints in SQL statements to specify how the statement should be run.
For example, suppose that your interactive application runs a query that returns 50 rows. This application initially fetches only the first 25 rows of the query to present to the end user. You want the optimizer to generate a plan that gets the first 25 records as quickly as possible so that the user is not forced to wait. You can use a hint to pass this instruction to the optimizer as shown in the SELECT statement and AUTOTRACE output in Example 7-4.
Example 7-4 Execution Plan for SELECT with FIRST_ROWS Hint
SELECT /*+ FIRST_ROWS(25) */ employee_id, department_id FROM hr.employees WHERE department_id > 50; ------------------------------------------------------------------------ | Id | Operation | Name | Rows | Bytes ------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 26 | 182 | 1 | TABLE ACCESS BY INDEX ROWID | EMPLOYEES | 26 | 182 |* 2 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX | | ------------------------------------------------------------------------
The execution plan in Example 7-4 shows that the optimizer chooses an index on the employees.department_id column to find the first 25 rows of employees whose department ID is over 50. The optimizer uses the rowid retrieved from the index to retrieve the record from the employees table and return it to the client. Retrieval of the first record is typically almost instantaneous.
Example 7-5 shows the same statement, but without the optimizer hint.
Example 7-5 Execution Plan for SELECT with No Hint
SELECT employee_id, department_id FROM hr.employees WHERE department_id > 50; ------------------------------------------------------------------------ | Id | Operation | Name | Rows | Bytes | Cos ------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 50 | 350 | |* 1 | VIEW | index$_join$_001 | 50 | 350 | |* 2 | HASH JOIN | | | | |* 3 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX | 50 | 350 | | 4 | INDEX FAST FULL SCAN| EMP_EMP_ID_PK | 50 | 350 |
The execution plan in Example 7-5 joins two indexes to return the requested records as fast as possible. Rather than repeatedly going from index to table as in Example 7-4, the optimizer chooses a range scan of EMP_DEPARTMENT_IX to find all rows where the department ID is over 50 and place these rows in a hash table. The optimizer then chooses to read the EMP_EMP_ID_PK index. For each row in this index, it probes the hash table to find the department ID.
In this case, the database cannot return the first row to the client until the index range scan of EMP_DEPARTMENT_IX completes. Thus, this generated plan would take longer to return the first record. Unlike the plan in Example 7-4, which accesses the table by index rowid, the plan in Example 7-5 uses multiblock I/O, resulting in large reads. The reads enable the last row of the entire result set to be returned more rapidly.
See Also:
Oracle Database Performance Tuning Guide to learn how to use optimizer hintsThis section explains how Oracle Database processes SQL statements. Specifically, the section explains the way in which the database processes DDL statements to create objects, DML to modify data, and queries to retrieve data.
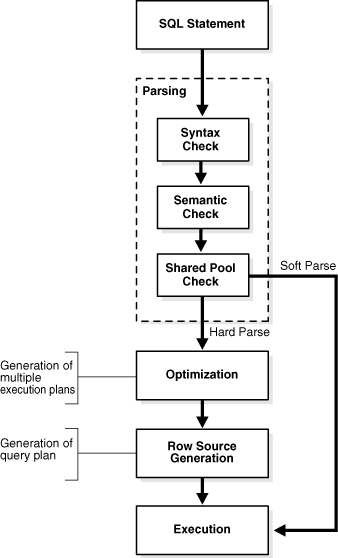
Figure 7-3 depicts the general stages of SQL processing: parsing, optimization, row source generation, and execution. Depending on the statement, the database may omit some of these steps.
As shown in Figure 7-3, the first stage of SQL processing is parsing. This stage involves separating the pieces of a SQL statement into a data structure that can be processed by other routines. The database parses a statement when instructed by the application, which means that only the application, and not the database itself, can reduce the number of parses.
When an application issues a SQL statement, the application makes a parse call to the database to prepare the statement for execution. The parse call opens or creates a cursor, which is a handle for the session-specific private SQL area that holds a parsed SQL statement and other processing information. The cursor and private SQL area are in the PGA.
During the parse call, the database performs the following checks:
The preceding checks identify the errors that can be found before statement execution. Some errors cannot be caught by parsing. For example, the database can encounter deadlocks or errors in data conversion only during statement execution (see "Locks and Deadlocks").
Oracle Database must check each SQL statement for syntactic validity. A statement that breaks a rule for well-formed SQL syntax fails the check. For example, the following statement fails because the keyword FROM is misspelled as FORM:
SQL> SELECT * FORM employees;
SELECT * FORM employees
*
ERROR at line 1:
ORA-00923: FROM keyword not found where expected
The semantics of a statement are its meaning. Thus, a semantic check determines whether a statement is meaningful, for example, whether the objects and columns in the statement exist. A syntactically correct statement can fail a semantic check, as shown in the following example of a query of a nonexistent table:
SQL> SELECT * FROM nonexistent_table;
SELECT * FROM nonexistent_table
*
ERROR at line 1:
ORA-00942: table or view does not exist
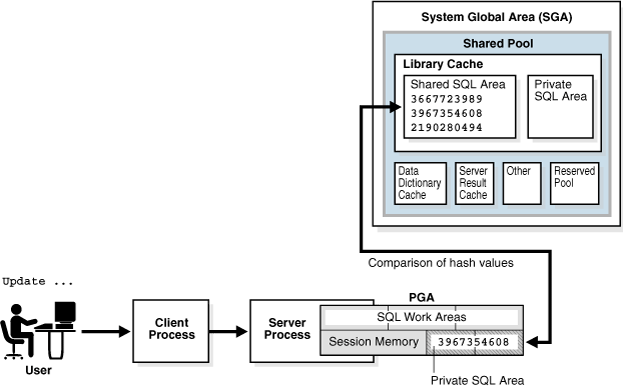
During the parse, the database performs a shared pool check to determine whether it can skip resource-intensive steps of statement processing. To this end, the database uses a hashing algorithm to generate a hash value for every SQL statement. The statement hash value is the SQL ID shown in V$SQL.SQL_ID.
When a user submits a SQL statement, the database searches the shared SQL area to see if an existing parsed statement has the same hash value. The hash value of a SQL statement is distinct from the following values:
Memory address for the statement
Oracle Database uses the SQL ID to perform a keyed read in a lookup table. In this way, the database obtains possible memory addresses of the statement.
Hash value of an execution plan for the statement
A SQL statement can have multiple plans in the shared pool. Each plan has a different hash value. If the same SQL ID has multiple plan hash values, then the database knows that multiple plans exist for this SQL ID.
Parse operations fall into the following categories, depending on the type of statement submitted and the result of the hash check:
If Oracle Database cannot reuse existing code, then it must build a new executable version of the application code. This operation is known as a hard parse, or a library cache miss. The database always perform a hard parse of DDL.
During the hard parse, the database accesses the library cache and data dictionary cache numerous times to check the data dictionary. When the database accesses these areas, it uses a serialization device called a latch on required objects so that their definition does not change (see "Latches"). Latch contention increases statement execution time and decreases concurrency.
A soft parse is any parse that is not a hard parse. If the submitted statement is the same as a reusable SQL statement in the shared pool, then Oracle Database reuses the existing code. This reuse of code is also called a library cache hit.
Soft parses can vary in the amount of work they perform. For example, configuring the session shared SQL area can sometimes reduce the amount of latching in the soft parses, making them "softer."
In general, a soft parse is preferable to a hard parse because the database skips the optimization and row source generation steps, proceeding straight to execution.
Figure 7-4 is a simplified representation of a shared pool check of an UPDATE statement in a dedicated server architecture.
If a check determines that a statement in the shared pool has the same hash value, then the database performs semantic and environment checks to determine whether the statements have the same meaning. Identical syntax is not sufficient. For example, suppose two different users log in to the database and issue the following SQL statements:
CREATE TABLE my_table ( some_col INTEGER ); SELECT * FROM my_table;
The SELECT statements for the two users are syntactically identical, but two separate schema objects are named my_table. This semantic difference means that the second statement cannot reuse the code for the first statement.
Even if two statements are semantically identical, an environmental difference can force a hard parse. In this case, the environment is the totality of session settings that can affect execution plan generation, such as the work area size or optimizer settings. Consider the following series of SQL statements executed by a single user:
ALTER SYSTEM FLUSH SHARED_POOL; SELECT * FROM my_table; ALTER SESSION SET OPTIMIZER_MODE=FIRST_ROWS; SELECT * FROM my_table; ALTER SESSION SET SQL_TRACE=TRUE; SELECT * FROM my_table;
In the preceding example, the same SELECT statement is executed in three different optimizer environments. Consequently, the database creates three separate shared SQL areas for these statements and forces a hard parse of each statement.
See Also:
Oracle Database Performance Tuning Guide to learn how to configure the shared pool
As explained in "Overview of the Optimizer", query optimization is the process of choosing the most efficient means of executing a SQL statement. The database optimizes queries based on statistics collected about the actual data being accessed. The optimizer uses the number of rows, the size of the data set, and other factors to generate possible execution plans, assigning a numeric cost to each plan. The database uses the plan with the lowest cost.
The database must perform a hard parse at least once for every unique DML statement and performs optimization during this parse. DDL is never optimized unless it includes a DML component such as a subquery that requires optimization.
See Also:
Oracle Database Performance Tuning Guide for detailed information about the query optimizerThe row source generator is software that receives the optimal execution plan from the optimizer and produces an iterative plan, called the query plan, that is usable by the rest of the database. The iterative plan is a binary program that, when executed by the SQL virtual machine, produces the result set.
The query plan takes the form of a combination of steps. Each step returns a row set. The rows in this set are either used by the next step or, in the last step, are returned to the application issuing the SQL statement.
A row source is a row set returned by a step in the execution plan along with a control structure that can iteratively process the rows. The row source can be a table, view, or result of a join or grouping operation.
The row source generator produces a row source tree, which is a collection of row sources. The row source tree shows the following information:
An ordering of the tables referenced by the statement
An access method for each table mentioned in the statement
A join method for tables affected by join operations in the statement
Data operations such as filter, sort, or aggregation
Example 7-6 shows the execution plan of a SELECT statement when AUTOTRACE is enabled. The statement selects the last name, job title, and department name for all employees whose last names begin with the letter A. The execution plan for this statement is the output of the row source generator.
SELECT e.last_name, j.job_title, d.department_name
FROM hr.employees e, hr.departments d, hr.jobs j
WHERE e.department_id = d.department_id
AND e.job_id = j.job_id
AND e.last_name LIKE 'A%' ;
Execution Plan
----------------------------------------------------------
Plan hash value: 975837011
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 189 | 7 (15)| 00:00:01 |
|* 1 | HASH JOIN | | 3 | 189 | 7 (15)| 00:00:01 |
|* 2 | HASH JOIN | | 3 | 141 | 5 (20)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 3 | 60 | 2 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | EMP_NAME_IX | 3 | | 1 (0)| 00:00:01 |
| 5 | TABLE ACCESS FULL | JOBS | 19 | 513 | 2 (0)| 00:00:01 |
| 6 | TABLE ACCESS FULL | DEPARTMENTS | 27 | 432 | 2 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
2 - access("E"."JOB_ID"="J"."JOB_ID")
4 - access("E"."LAST_NAME" LIKE 'A%')
filter("E"."LAST_NAME" LIKE 'A%')
During execution, the SQL engine executes each row source in the tree produced by the row source generator. This step is the only mandatory step in DML processing.
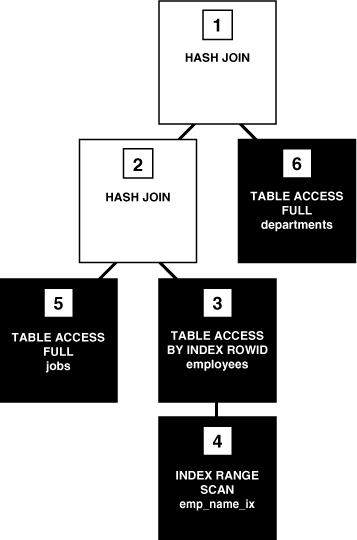
Figure 7-5 is an execution tree, also called a parse tree, that shows the flow of row sources from one step to another. In general, the order of the steps in execution is the reverse of the order in the plan, so you read the plan from the bottom up. Initial spaces in the Operation column indicate hierarchical relationships. For example, if the name of an operation is preceded by two spaces, then this operation is a child of an operation preceded by one space. Operations preceded by one space are children of the SELECT statement itself.
In Figure 7-5, each node of the tree acts as a row source, which means that each step of the execution plan either retrieves rows from the database or accepts rows from one or more row sources as input. The SQL engine executes each row source as follows:
Steps indicated by the black boxes physically retrieve data from an object in the database. These steps are the access paths, or techniques for retrieving data from the database.
Step 6 uses a full table scan to retrieve all rows from the departments table.
Step 5 uses a full table scan to retrieve all rows from the jobs table.
Step 4 scans the emp_name_ix index in order, looking for each key that begins with the letter A and retrieving the corresponding rowid (see "Index Range Scan"). For example, the rowid corresponding to Atkinson is AAAPzRAAFAAAABSAAe.
Step 3 retrieves from the employees table the rows whose rowids were returned by Step 4. For example, the database uses rowid AAAPzRAAFAAAABSAAe to retrieve the row for Atkinson.
Steps indicated by the clear boxes operate on row sources.
Step 2 performs a hash join, accepting row sources from Steps 3 and 5, joining each row from the Step 5 row source to its corresponding row in Step 3, and returning the resulting rows to Step 1.
For example, the row for employee Atkinson is associated with the job name Stock Clerk.
Step 1 performs another hash join, accepting row sources from Steps 2 and 6, joining each row from the Step 6 source to its corresponding row in Step 2, and returning the result to the client.
For example, the row for employee Atkinson is associated with the department named Shipping.
In some execution plans the steps are iterative and in others sequential. The plan shown in Example 7-6 is iterative because the SQL engine moves from index to table to client and then repeats the steps.
During execution, the database reads the data from disk into memory if the data is not in memory. The database also takes out any locks and latches necessary to ensure data integrity and logs any changes made during the SQL execution. The final stage of processing a SQL statement is closing the cursor.
See Also:
Oracle Database Performance Tuning Guide for detailed information about execution plans and theEXPLAIN PLAN statementMost DML statements have a query component. In a query, execution of a cursor places the results of the query into a set of rows called the result set.
Result set rows can be fetched either a row at a time or in groups. In the fetch stage, the database selects rows and, if requested by the query, orders the rows. Each successive fetch retrieves another row of the result until the last row has been fetched.
In general, the database cannot determine for certain the number of rows to be retrieved by a query until the last row is fetched. Oracle Database retrieves the data in response to fetch calls, so that the more rows the database reads, the more work it performs. For some queries the database returns the first row as quickly as possible, whereas for others it creates the entire result set before returning the first row.
In general, a query retrieves data by using the Oracle Database read consistency mechanism. This mechanism, which uses undo data to show past versions of data, guarantees that all data blocks read by a query are consistent to a single point in time.
For an example of read consistency, suppose a query must read 100 data blocks in a full table scan. The query processes the first 10 blocks while DML in a different session modifies block 75. When the first session reaches block 75, it realizes the change and uses undo data to retrieve the old, unmodified version of the data and construct a noncurrent version of block 75 in memory.
See Also:
"Multiversion Read Consistency"DML statements that must change data use the read consistency mechanism to retrieve only the data that matched the search criteria when the modification began. Afterward, these statements retrieve the data blocks as they exist in their current state and make the required modifications. The database must perform other actions related to the modification of the data such as generating redo and undo data.
See Also:
"Overview of the Online Redo Log"Oracle Database processes DDL differently from DML. For example, when you create a table, the database does not optimize the CREATE TABLE statement. Instead, Oracle Database parses the DDL statement and carries out the command.
The database process DDL differently because it is a means of defining an object in the data dictionary. Typically, Oracle Database must parse and execute many recursive SQL statements to execute a DDL command. Suppose you create a table as follows:
CREATE TABLE mytable (mycolumn INTEGER);
Typically, the database would run dozens of recursive statements to execute the preceding statement. The recursive SQL would perform actions such as the following:
Issue a COMMIT before executing the CREATE TABLE statement
Verify that user privileges are sufficient to create the table
Determine which tablespace the table should reside in
Ensure that the tablespace quota has not been exceeded
Ensure that no object in the schema has the same name
Insert rows that define the table into the data dictionary
Issue a COMMIT if the DDL statement succeeded or a ROLLBACK if it did not
See Also:
Oracle Database Advanced Application Developer's Guide to learn about SQL processing for application developers
|
Copyright © 1993, 2013, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|